

Advanced Sequence Encoding and Decoding Techniques in Python for Time Series Analysis
Exploring the Power of Python in Unraveling Complex Sequences in Time Series Data

In this concise guide, we explore the intricate world of sequence encoding and decoding in time series analysis using Python. Starting with essential libraries like NumPy, Pandas, and Matplotlib for data manipulation and visualization, we delve into preprocessing and understanding time series data, emphasizing stationarity. The core discussion focuses on advanced techniques such as the MinMaxScaler for normalization, the Dickey-Fuller test for assessing stationarity, and fractional differencing to balance data stationarity with memory retention. Using Keras, we construct and refine neural network models, highlighting LSTM cells in handling sequence data and regularization methods to prevent overfitting. This guide aims to equip readers with the skills to analyze complex time series sequences and extract predictive insights using Python’s machine learning capabilities.
#Import all the necessary libraries
import numpy as np
#from __future__ import print_function
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inlineThis code snippet imports all the necessary libraries for data analysis and visualization. This includes numpy, which is used for mathematical operations, pandas, which is used for data manipulation, and matplotlib, which is used for creating graphs and charts. The last line of code, %matplotlib inline, ensures that any created plots will be displayed within the notebook environment.
df= pd.read_csv('path-to-your-data-file.csv', header=None)
dfThis code creates a dataframe object called df by reading in a CSV file from the specified path. The header parameter is set to None, meaning there are no column names in the CSV file, so the dataframe will automatically assign column names. The second line prints the contents of the dataframe.
df=df.drop([0])
dfThis code snippet removes the first row of a dataframe and then resets the index of the remaining rows, ensuring that they are sequential starting from 0. This can be useful when the first row contains column headers or data that is not relevant to the analysis.
df=pd.DataFrame(df.values, columns=['Date', 'open','high','low','close','volume'])
dfThis code snippet converts the existing dataframe, df, into a new dataframe with the specified columns — Date, open, high, low, close, and volume. The values from the original dataframe are used to populate the new dataframe.
df1=df.apply(pd.to_numeric, errors='ignore')
df1=df1.drop(df1[df1.volume==0].index)
df1=df1.reset_index(drop=True)
df1This code snippet converts the dataframe into a numeric format, ignoring any errors that may occur during the conversion process. It then drops any rows with a volume value of 0 and resets the index of the remaining rows in the dataframe. Finally, it assigns this modified dataframe to the variable df1.
There is no source code to download for this article.
high_prices = df1.loc[:,'high'].values
low_prices = df1.loc[:,'low'].values
mid_prices = (high_prices+low_prices)/2.0
mid_prices=pd.DataFrame(mid_prices, columns=['mid'])
mid_pricesThis peice of python code basically takes the high and low columns from a dataframe named df1 and converts them into new arrays. It then calculates the mid price for each row by adding together the high and low prices, and dividing by 2. The mid prices are then stored in a new dataframe called mid_prices, with a column header mid. Essentially, this code is creating a new column in the df1 dataframe with the average of the high and low prices for each data point.
from sklearn.preprocessing import MinMaxScalerThe sklearn library is a popular machine learning library in Python. The MinMaxScaler function or class is used for scaling numerical data to a specific range, usually between 0 and 1. This is a common preprocessing step in machine learning to ensure that all features are on a similar scale and to prevent one feature from dominating the learning algorithm.
scaler=MinMaxScaler(feature_range=(1,10))The MinMaxScaler is used to rescale numerical data within a specific range, so the feature_range argument specifies the minimum and maximum values to use for scaling. In this case, the range is set to be between 1 and 10. The scaler object can then be used to transform data to fit within this specified range.
#Mnauly splitting training and testing data, again, just for research
traindf=df_temp.iloc[:810,:]
testdf=df_temp.iloc[810:,:]This python code snippet splits the data into training and testing data by using the index position of the data. The first 810 rows of data are selected for the training data while the remaining rows are used for the testing data. This split is typically done in machine learning and data analysis tasks to evaluate the performance of a model on unseen data.
df00=pd.concat([new_df, date], axis=1)This code creates a new pandas DataFrame called df00 by concatenating two existing DataFrames: new_df and date. The resulting DataFrame will have all of the columns from both input DataFrames, with new_df columns appearing first and date columns appearing second. The axis=1 parameter specifies that the DataFrames should be concatenated side by side as opposed to vertically.
#This is a function from the book "Advances in Financial Machine Learning" by Marco Lopes De Prado
#It checks for how the data's underlying distribution and it's mean and variance changes.
#Since most ML methods assume stationarity in data, this is a crucial check
def test_stationarity(x):
#Determing rolling statistics
rolmean = x.rolling(window=22,center=False).mean()
rolstd = x.rolling(window=12,center=False).std()
#Plot rolling statistics:
orig = plt.plot(x, color='blue',label='Original')
mean = plt.plot(rolmean, color='red', label='Rolling Mean')
std = plt.plot(rolstd, color='black', label = 'Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
#Perform Dickey Fuller test
result=adfuller(x)
print('ADF Stastistic: %f'%result[0])
print('p-value: %f'%result[1])
pvalue=result[1]
for key,value in result[4].items():
if result[0]>value:
print("The graph is non stationery")
break
else:
print("The graph is stationery")
break;
print('Critical values:')
for key,value in result[4].items():
print('\t%s: %.3f ' % (key, value))This code snippet is used to check for stationarity in a given dataset. It first calculates the rolling mean and standard deviation for the data, then plots these rolling statistics. It then uses the Dickey Fuller test to determine the p-value and compares it to predetermined critical values. If the p-value is greater than the critical value, the data is considered non-stationary. If the p-value is less than or equal to the critical value, the data is considered stationary. This is important for machine learning methods as they often assume stationarity in data.
df00['date']=pd.to_datetime(df00.date)
format='%Y-%m-%d'
df00['Datetime']=pd.to_datetime(df00['date'],format=format)
df00=df00.set_index(pd.DatetimeIndex(df00['Datetime']))
df00This code converts a column in a dataframe called date to a datetime format using the to_datetime function from the Pandas library. The format of the datetime is specified as YYYY-MM-DD. Next, a new column called Datetime is created by applying the to_datetime function to the date column, using the specified format. The dataframe is then re-indexed using the Datetime column as the index. Finally, a new column called year is created by extracting the year value from the Datetime column using the dt function.
df_raw=df00[['open','close','volume','mid']]This code creates a new dataframe called df_raw and extracts four specific columns open, close, volume, and mid from an existing dataframe called df00. The four columns are then assigned to the new dataframe in the exact order they were extracted.
#Again, these functions are from the book
#They check for how much fractional differentiation is needed in the data so that it becomes stationary
#WHILE preserving memory.
#I personally stil don't know how much of an effect this memory-vs-stationarity dilemma has, but this was a research project
#so i went along with it.
def plotMinFFD():
from statsmodels.tsa.stattools import adfuller
out=pd.DataFrame(columns=['adfStat','pVal','lags','nObs','95%conf','corr'])
for d in np.linspace(0,1,11):
df1=np.log(df_raw[['close']]).resample('1D').last() #downcast to daily obs
df2=fracDiff_FFD(df1,d,thres=0.01)
corr=np.corrcoef(df1.loc[df2.index,'close'],df2['close'])[0,1]
df2=adfuller(df2['close'],maxlag=1,regression='c',autolag=None)
out.loc[d]=list(df2[:4])+[df2[4]['5%']]+[corr]
out.to_csv('/home/parth/Documents/testMinFFD_daily.csv')
out[['adfStat','corr']].plot(secondary_y='adfStat')
plt.axhline(out['95%conf'].mean(), linewidth=0.6,color='r',linestyle='dotted')
plt.savefig('/home/parth/Pictures/MinFFD_daily.png', dpi=1200)
return
def getWeights_FFD(d,thres):
w,k=[1.],1
while True:
w_=-w[-1]/k*(d-k+1)
if abs(w_)<thres:break
w.append(w_)
k+=1
w=np.array(w[::-1]).reshape(-1,1)
return w
def fracDiff_FFD(series,d,thres=1e-5):
#1)Compute weights for the longest series
w=getWeights_FFD(d,thres)
width= len(w)-1
#2)Apply weights to values
df={}
for name in series.columns:
seriesF=series[[name]].fillna(method='ffill').dropna()
df_=pd.Series()
for iloc1 in range(width, seriesF.shape[0]):
loc0,loc1=seriesF.index[iloc1-width],seriesF.index[iloc1]
if not np.isfinite(series.loc[loc1,name]):continue #exlcude NAs
df_[loc1]=np.dot(w.T,seriesF.loc[loc0:loc1])[0,0]
df[name]=df_.copy(deep=True)
df=pd.concat(df,axis=1)
return dfThis code snippet contains two functions: plotMinFFD and getWeights_FFD, and one helper function fracDiff_FFD. These functions aim to find the optimal amount of fractional differentiation needed to make a given data series stationary, while still preserving its memory. This is an important concept in time series analysis as it helps to eliminate trends and seasonality in the data, making it easier to model and make predictions. In simple terms, the functions calculate the weights for the data and then apply them to the values, adjusting them to find the best fit for stationarity. The first function, plotMinFFD, uses the statsmodels library to perform the necessary calculations and outputs a plot showing the relationship between the adfStat a measure of stationarity and the correlation coefficient. The second function, getWeights_FFD, is responsible for calculating the weights used in the calculations, and the helper function, fracDiff_FFD, applies those weights to the data series to achieve the desired level of differentiation. Overall, this code snippet helps to analyze and modify time series data for more accurate predictions and analysis.
plotMinFFD()
This function plots the minimum energy flux force density FFD values on a graph. The FFD is a measure of the force and energy exerted on a surface by a fluid or gas. The function likely takes in data inputs, calculates the minimum FFD values, and then plots them using a graphing library. This can help visualize the least amount of force and energy that will be exerted on a surface by a fluid or gas, which could be useful for understanding and predicting potential impacts or damage.
#Implementing the Dickey-Fuller test here.
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.arima_model import ARIMAThis code snippet imports the Dickey-Fuller test and the ARIMA model from the statsmodels package. The Dickey-Fuller test is used to test for stationarity in a time series data, while ARIMA is an acronym for autoregressive integrated moving average, which is used for time series forecasting. The snippet does not show any code, so it is not clear which specific functions or parameters are being used.
df01=fracDiff_FFD(df_raw, d=0.1,thres=0.01)
df01This code snippet calls the function fracDiff_FFD, passing in a dataframe df_raw, a parameter d with a value of 0.1, and a parameter thres with a value of 0.01. The function takes the dataframe and performs the fractional differencing method with the specified coefficients, resulting in a new dataframe. The code then prints out the new dataframe. This method is commonly used in time series analysis to remove long-term dependencies and make the data more stationary.
#As you can see, the way it's coded up, I can only check for the stationarity of a single column at once.
#This is annoying, but for research purposes it works. Different amounts of differentiation is needed for all columns
#So you ave to, by trial and error, find the best degree of fractional differentiation.
test_stationarity(df01['volume'])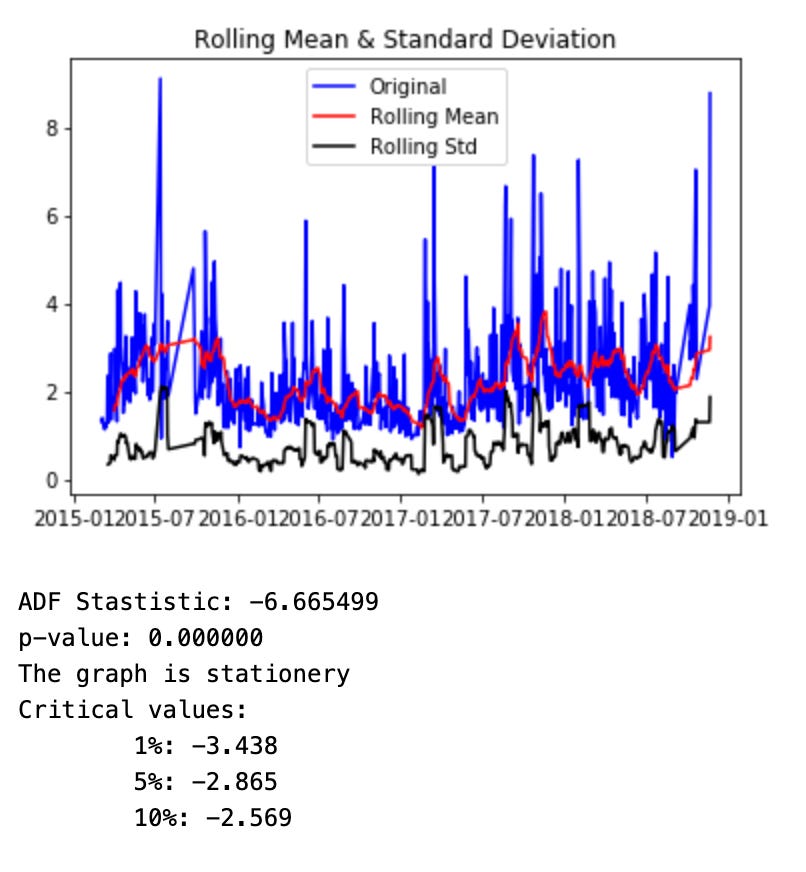
This code snippet is checking for the stationarity of a single column in a dataset. Stationarity refers to the statistical property of a time series data where the mean, variance, and autocorrelation structure do not change over time. This is important in time series analysis as many models assume stationarity in order to make accurate predictions. The snippet indicates that the dataset has multiple columns and each column may require a different degree of fractional differentiation a method to transform a time series into a stationary one. Therefore, in order to determine the best degree of fractional differentiation for each column, the researcher may have to manually test and adjust the values until a satisfactory result is achieved.
