

Advanced Stock Market Analysis and Visualization Using Python
Leveraging Data Science for Insightful Financial Predictions

In this article, we explore the intricate world of stock market analysis through Python, employing libraries such as Numpy for numerical computations, Pandas for data management, and Matplotlib for visual representation. The focus is on a practical approach, starting from the ingestion of stock data from “THYAO_ENDEKSLI.csv”, which is presumed to contain pivotal historical stock market information, to the execution of basic data viewing operations. This foundational step sets the stage for more complex analytical tasks.
Advancing into the realms of data processing and machine learning, we demonstrate the calculation of average stock prices, the transformation of data for model readiness, and the critical step of data normalization using Scikit-learn’s MinMaxScaler. These processes are instrumental in preparing the stock data for a deeper analytical dive, utilizing advanced techniques to extract meaningful insights from the financial figures. The article seamlessly integrates theory with practical Python code, providing a comprehensive guide for those interested in financial data analysis and visualization.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
%matplotlib inline
stock_data = pd.read_csv("THYAO_ENDEKSLI.csv")This Python code sets up the environment for analyzing visualizing stock data. It imports numpy for numerical operations, pas for data manipulation, matplotlib.pyplot for plotting, datetime for hling date time data. It also enables the display of plots in Jupyter Notebook or IPython using %matplotlib inline. Then it reads a CSV file named THYAO_ENDEKSLI.csv using pas stores the data in a variable called stock_data. This file likely contains historical stock market data that can be used for analysis or visualization.
print(stock_data)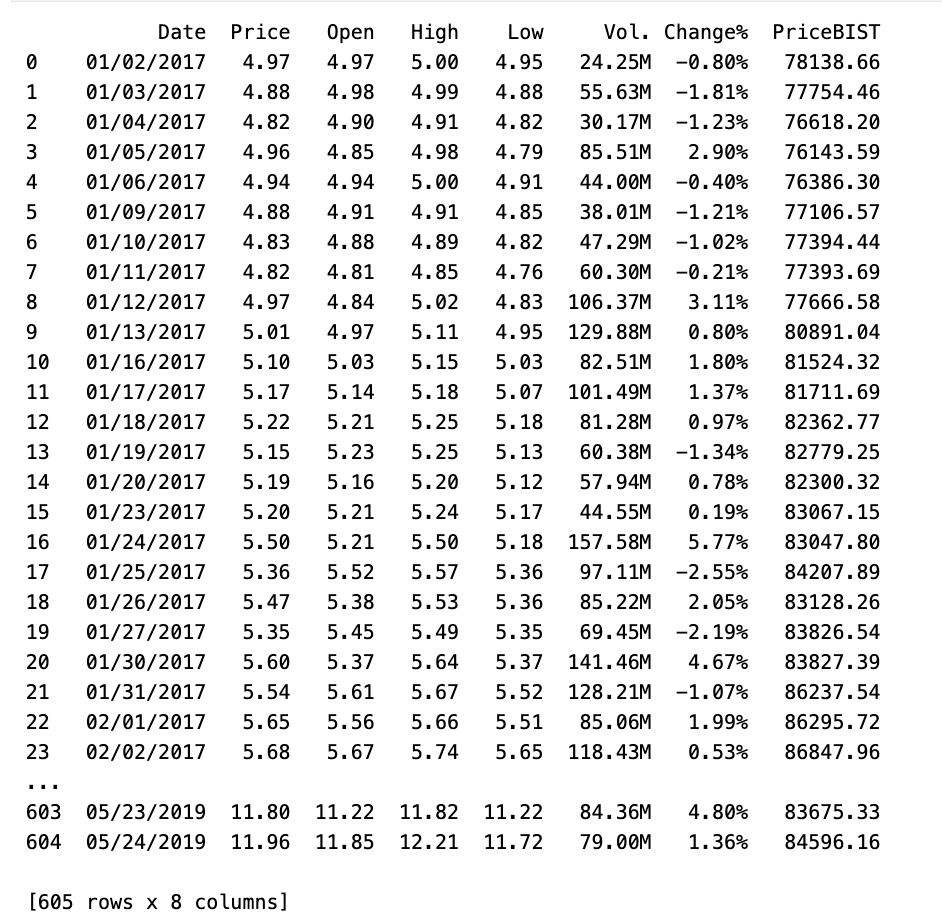
This code displays the value of stock_data variable to the user. It could show numbers, text, or more complex data structures stored in the variable. Its commonly used for checking variable contents while running a script.
import math
stock_data["Average"] = (stock_data["High"] + stock_data["Low"])/2This code calculates the average stock price for each day from the High Low columns in the stock_data dataset. It creates a new column called Average uses vectorization to efficiently perform the calculation.
input_feature= stock_data.iloc[:,[1,7,8]].values
input_data = input_feature
input_data_INVERSE = input_feature
print(input_data[:,0])
This code snippet selects specific columns from the stock_data dataset using iloc, converts it to a NumPy array, prints the first column to the console. Two copies of the array are also created using two new variables.
lookback= 50
test_size=int(.6 * len(stock_data))
print(test_size)
This code snippet extracts two values, lookback test_size. The value of lookback is set as 50, representing a period of past observations. Test_size is calculated as 60% of the length of stock_data, a datasets total number of entries. The code then prints this value. These parameters are used for data analysis, where 60% is defined as the testing size lookback represents a predefined window period.
Train_ORG=input_data_INVERSE[:test_size+lookback]
Test_ORG=input_data_INVERSE[test_size+lookback:]
print(Test_ORG[:,0])
This code creates two datasets — one for training one for testing — by manipulating an array called input_data_INVERSE. The test_size variable represents the number of samples for testing, while lookback accounts for additional context needed from the data. The training dataset (Train_ORG) is created by slicing input_data_INVERSE from the beginning up to the sum of test_size lookback, while the testing dataset (Test_ORG) is created by slicing from the sum of test_size lookback to the end of the array. The first column of the Test_ORG array can be printed as a quick check.
from sklearn.preprocessing import MinMaxScaler
sc1= MinMaxScaler(feature_range=(0,1))
sc2= MinMaxScaler(feature_range=(0,1))
sc3=MinMaxScaler(feature_range=(0,1))
stock_prices = Test_ORG[:,0]
stock_bist = Test_ORG[:,1]
stock_average = Test_ORG[:,2]
stock_P=stock_prices.reshape(-1,1)
stock_B=stock_bist.reshape(-1,1)
stock_A=stock_average.reshape(-1,1)
input_data_prices = sc1.fit(stock_P)
input_price=input_data_prices.transform(stock_P)
input_price_reverse=sc1.inverse_transform(input_price)
input_data_bist = sc2.fit(stock_B)
input_bist=input_data_bist.transform(stock_B)
input_bist_reverse=sc2.inverse_transform(input_bist)
input_data_average = sc3.fit(stock_A)
input_average=input_data_average.transform(stock_A)
input_average_reverse=sc3.inverse_transform(input_average)
input_data4 = np.hstack((input_price, input_bist, input_average))The code uses Scikit-learns MinMaxScaler to normalize transform stock-related data. Three instances of this preprocessing tool are created with a range of 0 to 1, indicating three types of stock data to scale: prices, BIST, averages. Each data type is taken from the Test_ORG array reshaped into a 2D array for the scaler. The scaler is fitted to each type of stock data individually, calculating the necessary minimum maximum values for scaling. The scaled data is then transformed back to its original range using inverse_transform. The resulting datasets are stacked together to create an array called input_data4. This can be used for further analysis or as input for a machine learning model.
plt.plot(input_feature[:,0])
plt.title("Close of stocks sold")
plt.xlabel("Time (latest-> oldest)")
plt.ylabel("Close of stocks traded")
plt.show()
This code snippet creates a 2D line plot to visualize the closing price of stocks over time. It uses a Python visualization library, like matplotlib, applies labels a title to the graph. Overall, it displays trends in stock closing prices over a specified time period.
plt.plot(input_feature[:,1], color='blue')
plt.title("BIST 100")
plt.xlabel("Time (latest-> oldest)")
plt.ylabel("Stock Closing Price")
plt.show()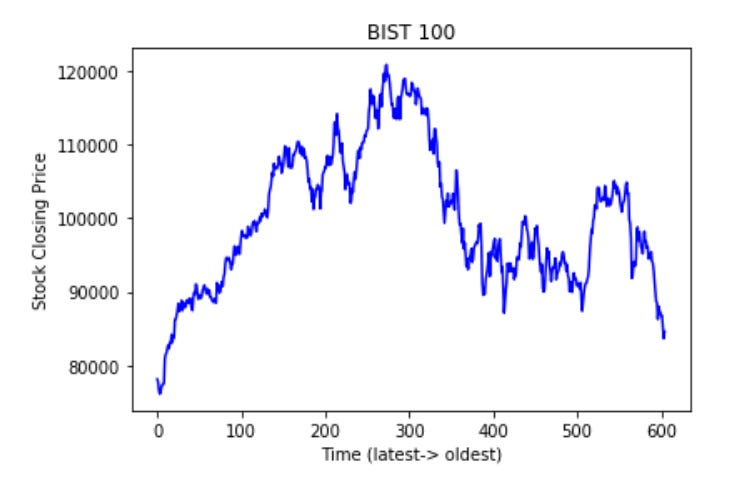
This code generates a line chart using matplotlib in Python to visualize stock closing prices over time from the input_feature dataset. The chart shows the second column as blue is titled BIST 100. The X-axis is labeled Time (latest-> oldest) the Y-axis is labeled Stock Closing Price. Use plt.show() to display the chart.
scTrain= MinMaxScaler(feature_range=(0,1))
scTest= MinMaxScaler(feature_range=(0,1))
Train=input_data[:test_size+lookback]
Test=input_data[test_size+lookback:]
Train_feature=input_feature[:test_size+lookback]
Test_feature=input_feature[test_size+lookback:]
Train[:,0:3] = scTrain.fit_transform(Train_feature[:,:])
Test[:,0:3] = scTest.fit_transform(Test_feature[:,:])
print(input_data.shape)
print(Test.shape)
print(Train.shape)
The code snippet scales input data features to a range of 0 to 1 using the MinMaxScaler from a machine learning library. It creates separate instances for training testing datasets, then defines the datasets by slicing the input_data input_feature arrays based on test_size lookback parameters. The training test features are scaled using the fitted MinMaxScaler, the shapes of the input_data, Test, Train arrays are printed for verification.
X_train=[]
y_train=[]
for i in range(len(Train)-lookback-1):
t_train=[]
for j in range(0,lookback):
t_train.append(Train[[(i+j)], :])
X_train.append(t_train)
y_train.append(Train[i+ lookback,0])This code prepares training data for a machine learning model. It creates empty lists, X_train y_train, to store the features target values. The outer loop iterates over the Train data creates a sequence of lookback data points. The inner loop appends elements from the Train dataset to the temporary list t_train. After the inner loop finishes, the sequence is added to X_train as the feature set. The data point at position i+lookback in the first column of the Train dataset becomes the target value is appended to y_train. This creates a collection of sequences with corresponding target values that can be used to train a model for time series forecasting or sequential analysis.
X_train, y_train = np.array(X_train), np.array(y_train)
X_train=X_train.reshape(X_train.shape[0], lookback , 3)This code prepares time-series or sequence data for machine learning models such as RNNs or LSTMs. It converts X_train y_train to numpy arrays reshapes X_train into a 3-dimensional array. This allows for optimal use in libraries like TensorFlow or PyTorch. Reshaping is necessary for models that require specific input shapes.
look=lookback-1
X_test = []
y_test = []
for i in range(len(Test)-look):
t_test=[]
for j in range(0,lookback):
t_test.append(Test[[(i+j)], :])
if(i<len(Test)-look-1):
y_test.append(Test[i+ lookback,0])
X_test.append(t_test) This code creates sequences from a dataset, with a specified lookback length. It stores features labels for a test dataset, ensures each sequence has a corresponding label. The resulting X_test y_test contain sequential data predicted outputs.
X_test, y_test= np.array(X_test), np.array(y_test)
X_test=X_test.reshape(X_test.shape[0], lookback , 3)This code prepares arrays for machine learning testing. It converts input data to numpy arrays reshapes it to meet model requirements. The new shape is 3-dimensional with dimensions for samples, time steps, features. It allows for compatibility with models that expect sequential data.
from keras import Sequential
from keras.layers import Dense, LSTMThis code snippet imports specific modules from the Keras library for building training neural networks. The Sequential model is made up of a linear stack of layers, including Dense LSTM layers. These are fully connected, capable of capturing long-term dependencies in sequence data such as time series or natural language. The code only makes the necessary classes available for creating the model later on.
model = Sequential()
model.add(LSTM(128, input_shape=(X_train.shape[1],3)))
#model.add(LSTM(30, return_sequences=True))
#model.add(LSTM(30))
model.add(Dense(units=1))
model.summary()
This code creates a neural network using Keras TensorFlow for processing sequential data. It includes a Sequential model with an LSTM layer of 128 units for excellent sequence processing. The input shape is based on the second dimension of the training data, with each timestep having a 3-dimensional data. Additional LSTM layers could be added for more complexity, it ends with a Dense layer with one unit, suitable for regression tasks. Use model.summary() for an overview of the models structure.