



An Introduction To Using Transorfmers And Hugging Face
Transform your understanding of transformers into real life solutions

Introduction
Researchers in Natural Language Processing, NLP, have generated innovative results in a wide range of fields over the past few decades. Natural Language Processing examples include:
Apple’s Siri personal assistant. It can be used for day-to-day activities such as setting alarms, texting, answering questions, etc.
Medical field researchers use NLP. In order to accelerate the discovery of new drugs.
Language translation. We can also overcome communication barriers with this application.
As one of the most powerful NLP models ever created, Transformers will be discussed in this conceptual blog. Transformers will be explained after explaining their advantages over recurrent neural networks. Our next step will be to demonstrate some real-world case scenarios using Huggingface transformers.
Recurrent Network — The Shinning Era Before Transformers
Let’s first understand what recurrent models are and their limitations before diving into the core concept of transformers.
As recurrent networks use the encoder-decoder architecture, they are primarily used for tasks where the inputs and outputs are sequences in some defined order. Machine translation and time series data modelling are two of the most important applications of recurrent networks.
Recurrent networks pose challenges
Taking this French sentence as an example, let’s translate it into English. The encoder receives the original French sentence, and the decoder generates the translated output.

The recurrent network for language translation illustrated in a simple way
The input French sentence is passed to the encoder one word at a time, and the word embeddings are generated in the same order by the decoder. This causes the system to be slow to train.
No matter how powerful the computer is, the parallel computation cannot be performed without knowing the hidden state of the previous word.
Whenever neural networks are sequenced to sequence, gradients explode, resulting in poor performance.
To mitigate the vanishing gradient, other types of recurrent networks have been introduced, such as Long Short-Term Memory (LSTM) networks. However, these networks are even slower than sequence models.
A model that combines the benefits of recurrent networks with parallel computation would be great, wouldn’t it?
The transformer comes in handy here.
What are Transformers in NLP?
As part of their famous research paper “Attention is all you need,” Google Brain introduced Transformers in 2017 as new neural network architecture. As opposed to recurrent networks, it is based on the attention mechanism instead of sequential computation.
Transformers consist of what main components?
The transformer also consists of two main blocks: an encoder and a decoder, each with its own self-attention mechanism. Transformers were originally designed with RNN and LSTM encoder-decoder architectures, which later evolved into self-attention and feed-forward networks.
A general overview of each transformer block is provided in the following section.
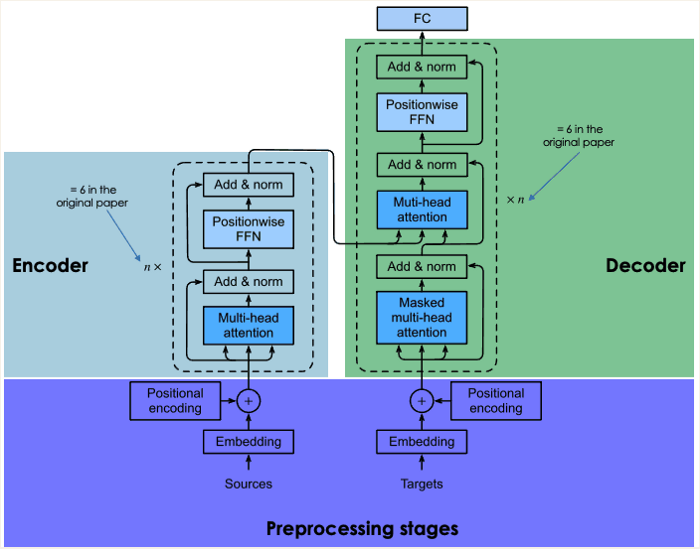
Preprocessing of input sentences
In this section, we compute the positional vectors of words in the input sentence and generate embeddings of the input sentence. Both the source sentence and target sentence are computed in the same way (before the encoder block).
Embedding of the input data
By tokenizing the input data first, we create the embeddings of individual words without considering their relationship in the sentence.
Positional encoding
During tokenization, any relations that were present in the input sentence are discarded. By generating a context vector for each word, the positional encoding attempts to mimic the original cyclic nature.
Encoder bloc
In the previous step, we obtained two vectors for each word: (1) it's embedding and (2) its context. A single vector is created for each word by adding these vectors together.
Multi-head attention
We lost all concepts of a relationship, as mentioned previously. It captures contextual relationships between words in the input sentence by using the attention layer. A vector of attention is generated for each word as a result of this step.
Position-wise feed-forward net (FFN)
In this stage, each attention vector is transformed into a format that is expected by the next multi-head attention layer in the decoder using a feed-forward neural network.
Decoder block
Multi-head masked attention is the first layer of the decoder block, followed by multi-head attention and a position-wise feedforward network.
Our understanding of the last two layers, which are identical in the encoder, is already complete.
While the network is being trained, two main inputs are sent to the decoder: (1) the vectors of the input sentences we want to translate, and (2) the translated English target sentences.
So, what is the masked multi-head attention layer responsible for?
The network is allowed to use all the words from the French word when generating the next English word. The network cannot access the next words in the target sequence (English translation) when it is dealing with a given word since it would “cheat” by obtaining the next ones and not learning properly. The benefits of the masked multi-head attention layer can be seen here. Transforming those next words into zeros, it prevents the attention network from using them.
A probability score is generated by passing the results of the masked multi-head attention layer through the rest of the layers.
There are several reasons why this architecture was successful:
When compared to RNNs, the total computational complexity at each layer is lower.
Unlike RNNs that require sequence input, it does not require recurrence, allowing sequence parallelization.
As a result of the lengths of the forward and backward signals in RNNs, they are inefficient at learning from long-range sequences. Self-attention facilitates learning by shortening this path.
Transfer Learning in NLP
It is not easy to train deep neural networks from scratch, including transformers, and may present the following challenges:
It can be difficult to find the right amount of data for the target problem
In order to train deep networks, it is extremely costly to get the necessary computation resources, such as GPUs.
In addition to reducing training time, transfer learning can speed up the training process for new models and reduce project delivery time.
The Mandingo language is a low-resource language, so imagine translating it to Wolof from scratch. It is expensive to gather data about those languages. For training the new model, one can re-use pre-trained deep-neural networks instead of going through all these challenges.
In language translation tasks, such as French to English translation, these models have been trained using a vast amount of data, made available by others (a moral individual, organization, etc.).
Is re-using deep neural networks what you mean?
Using the data you supplied, retrain the head of the pre-trained model using the input-output pair of your target task that matches your use case.
Since Transformers were introduced, state-of-the-art transfer learning models have been developed, such as:
In 2018, Google researchers developed BERT, short for Bidirectional Encoder Representations from Transformers. As well as character recognition, sentiment analysis, question answering, text summarization, and others, it can be used to solve the most common language tasks.
It is referred to as GPT3 (Generative Pre-Training-3), and it has been proposed by OpenAI researchers. Basically, it is a multi-layer transformer that generates any type of text. In response to a given question, GPT models can produce text responses similar to those of humans.
An introduction to Hugging Face Transformers
Julien Chaumond, Clément Delangue, and Thomas Wolf founded Hugging Face in 2016 as an AI community and Machine Learning platform. Using the state-of-the-art transformer architecture, it enables Data Scientists, AI practitioners, and Engineers to access over 20,000 pre-trained NLP models. There are a number of applications for these models, including:
Performing tasks such as classification, information extraction, question answering, generation, generation, and translation using text in over 100 languages.
The use of speech for tasks such as classifying audio objects and recognizing speech.
A vision system for detecting objects, classifying images, and segmenting images.
The use of tabular data in regression and classification problems.
Transformers that implement reinforcement learning.
Using nearly 31 libraries, programmers can interact with Hugging Face Transformers models using almost 2000 data sets and layered APIs. A majority of these are deep learning tools, such as Pytorch, Tensorflow, Jax, ONNX, Fastai, and Stable-Baseline 3.
Transformer pipelines: what are they?
By using pipeline(), you can perform inference over a variety of tasks easily.
Natural Language Processing tasks like text cleaning, tokenization, embedding, etc., use to encapsulate the overall process.
The pipeline() method is structured as follows:

Hugging Face Tutorial:
We will walk you through real-world scenarios based on Transformers, the Hugging Face platform, language translation, sequence classification with zero-shot classification, sentiment analysis, and question answering.
An article’s popularity can be predicted before publication using this dataset, which is available online and enriched by Facebook. The description column will be used for the analysis. From the data, only three examples will be used to illustrate our examples.


Language Translation
MariamMT is an efficient framework for machine translation. MarianNMT is the engine used under the hood, which was developed by Microsoft and many universities, including the University of Edinburgh and Adam Mickiewicz University in Pozna. The same engine is currently behind the Microsoft Translator service.
Multiple translation models have been released by the University of Helsinki’s Natural Language Processing group in the format Helsinki-NLP/opus-mt-[src]-[tgt] where [src] and [tgt] refer to the source and target languages.
Here, English (en) is the source language and French (fr) is the target language.On Opus parallel data, MarianMT was previously trained using Marian.
As well as Transformers, MarianMT requires sentence piece:

Pre-trained models can be loaded by selecting them, getting the tokenizer, and loading them

Add the special token >>{tgt}<< in front of each source (English) text with the help of the following function.

Using the following function, implement batch translation logic, where a batch is a list of texts that need to be translated.
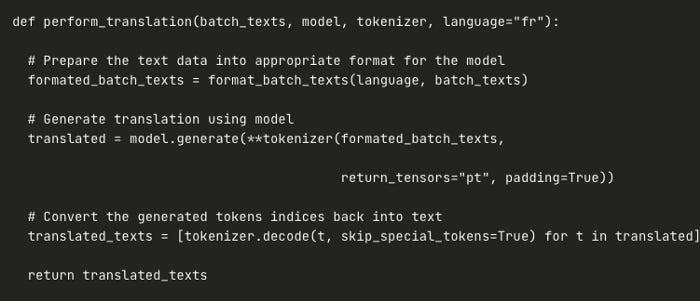
Analyze the previous descriptions and translate them

