

Data Structures Used In Algorithms Explained
During the execution of algorithms, there is a need for in-memory data structures that can hold temporary data.

Effective implementation of data structures requires the selection of the appropriate data structures. Iterative or recursive algorithms require data structures that are specifically designed for their logic.
In the case of recursive algorithms, nested data structures may facilitate their implementation and enhance their performance. Algorithms are discussed in this article in relation to data structures. The focus of this article is on Python data structures since we will be using Python throughout the article. However, the concepts presented in this article can be applied to other languages as well, such as Java and C++.
In this article, you should gain an understanding of how Python handles complex data structures and which one should be used for a particular type of data.
In this article, the following points will be discussed:
Using Python to explore data structures
An exploration of abstract data types
Queues and stacks
The trees
Python data structures exploration
Data structures are used to store and manipulate complex data in any programming language. Data structures in Python are containers for managing, organizing, and searching data efficiently. They are used to store and process groups of data elements referred to as collections. The following five data structures can be used to store collections in Python:
An ordered sequence of elements that can be mutated
Sequences of elements ordered in an immutable manner
The elements of the sets are unordered
The dictionary defines key-value pairs as unordered bags
A data frame is a two-dimensional structure for storing two-dimensional data
In the following subsections, we’ll explore them in greater detail.
List
A list is Python’s primary data structure for storing mutable elements. A list does not have to contain the same type of data elements.
It is necessary to enclose the elements of a list in [ ] and separate them with a comma. This code, for example, creates four different types of data elements together:
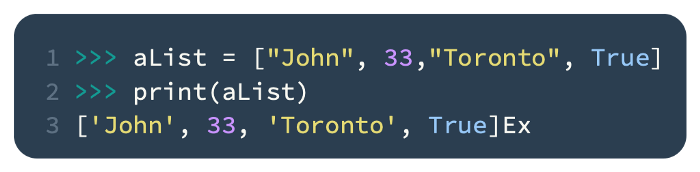
In Python, lists are useful for creating one-dimensional writable data structures that are needed at different stages of an algorithm’s development.
Lists
Lists can be managed using utility functions in data structures, which make them very useful.
In order to make use of them, let’s consider the following:
It is possible to obtain an element at a particular position by using the index of a list, since the position of elements in a list is deterministic. A demonstration of this concept can be found in the following code:

This code generates a four-element list as shown in the screenshot below:
Because the index begins at 0, Green is retrieved using index 1, that is, bin_color[1].
A list can be sliced by specifying a range of indexes in order to retrieve a subset of its elements. You can create a slice of the list using the following code:

Python’s list data structure is one of the most popular single-dimensional data structures.
During the process of slicing a list, the range is indicated as follows: the first number (inclusive) and the second number (exclusive). Similarly, bin_colors[0:2] contains bin_color[0] and bin_color[1], but not bin_color[2]. As some Python users complain that lists are not intuitive, you should keep this in mind while using them.
Here is a snippet of code that you might find useful:
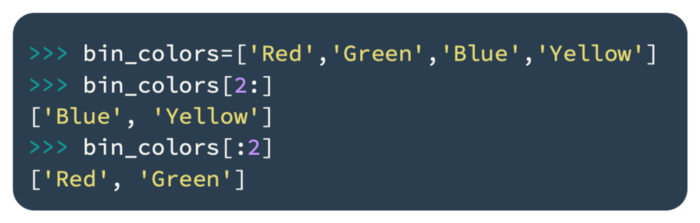
If no starting or ending index is specified, the list will begin at the beginning, and if neither index is specified, the list will end at the end. As can be seen from the preceding code, this concept is actually demonstrated.
It is also possible to have negative indices in Python, which count from the end of the list. Following is a code example that illustrates this:
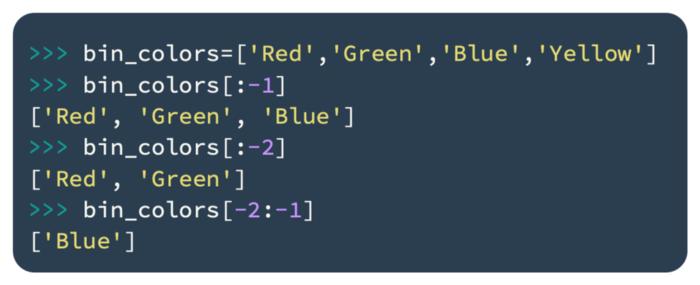
Negative indices are especially useful when we want to refer to the last element rather than the first one.
There are two types of nesting in a list: simple and complex. The nesting of lists is enabled by this feature. In the case of iterative and recursive algorithms, this provides important capabilities.
Consider the following code example, which shows a list within a list (nesting):

In Python, a for loop can be used to iterate over each element of a list. An example of this can be seen below:

Each element of the list is printed by iterating through the code preceding.
Functions in Lambda
Lambda functions can be applied to lists in a variety of ways. In the context of algorithms, they are particularly important as they provide the capability to create functions on the fly. They are sometimes referred to as anonymous functions in the literature. The following examples demonstrate how they can be used:
The first step in filtering data is to define a predicate, which is a function that accepts a single argument and returns a Boolean value. A demonstration of its use can be found in the following code:

Using lambda functions to filter a list, we specify the filtering criteria in this code. Based on a defined criterion, the filter function filters elements out of a sequence. It is usually used in conjunction with lambda in Python to use the filter function. Additionally, tuples and sets can be filtered using it. x > 100 is the criterion defined for the preceding code. All elements in the list will be iterated through and any that fail this filter will be removed.
Lambda functions can be used to transform data using the map() function. The following is an example:

It is quite powerful to use the map function with a lambda function. It is possible to specify a transformer for each element of the sequence using the lambda function when used with the map function. The preceding code uses multiplication by two as the transformer. Each element in the list is multiplied by two using the map function.
Reduce() can be used to recursively run a function on each element of a list in order to aggregate data:
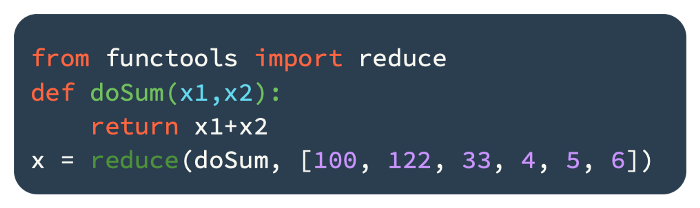
It is important to note that a data aggregation function is required for the reduce function. This code includes a data aggregation function called functools. It specifies how a list of items will be aggregated. As the result of the aggregation, the first two elements will be replaced with the result. Until we reach the end, we repeat the reduction process until one aggregated number is reached. The doSum function represents the aggregation criterion for x1 and x2 in each iteration.
270 is the result of the preceding code block.
Using the range function
With the range function, large lists of numbers can be easily generated. A sequence of numbers in a list can be automatically populated with this function.
It is easy to use the range function. To use it, we just need to specify how many elements we want in the list. It starts at zero and increases by one by default:

Additionally, we can specify the step and the end number:
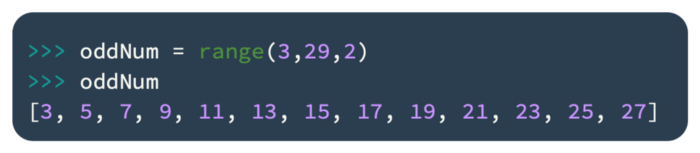
Odd numbers starting from 3 to 29 will be returned by the previous range function.
Lists are time-consuming
Using the Big O notation, a list’s time complexity can be summarized as follows:
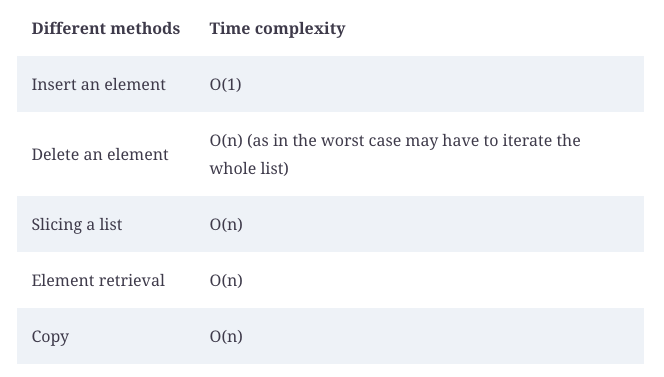
Note that adding an element takes the same amount of time regardless of the size of the list. The size of the list affects other operations shown in the table. The performance impact increases as the list grows.
Tuples
Collections can also be stored in tuples, which are data structures. The tuple data structure differs from lists in that it is immutable (read-only). The elements of a tuple are surrounded by ( ).
A tuple can contain elements of different types, just like a list. Their elements also support complex data types. As a result, it is possible to create nested data structures by using a tuple within a tuple. Iterative and recursive algorithms greatly benefit from the ability to create nested data structures.
You can create tuples using the following code:

Due to their performance advantages, immutable data structures (such as tuples) should be preferred whenever possible. The performance of immutable data structures is significantly faster than that of mutable ones, especially when dealing with big data. For instance, there is a price we have to pay for the ability to change data elements in lists, so we should carefully consider whether it is really necessary, in order to implement the code as read-only tuples.
This code refers to tuples (100,200,300) as the third element, a[2]. The second element of this tuple is 200, referred to as a[2][1].
Tuple time complexity
(Using Big O notation) Here are a few examples of time complexity of functions of tuples:

It is important to note that Append adds additional elements to the already existing tuple. O(1) is its complexity.
Dictionary
Especially in distributed algorithms, key-value pairs are important. A dictionary in Python contains a collection of these key-value pairs. It is important to choose the key that is best suited to identifying data throughout data processing when creating a dictionary. Any type of element can be used as the value, for example a number or string. A list is always used as a value in Python, as well as other complex data types. As a value type, a dictionary can be used to create nested dictionaries.
An easy way to assign colors to variables is to enclose key-value pairs in { }. As an illustration, here is a code that creates a simple dictionary with three key-value pairs:
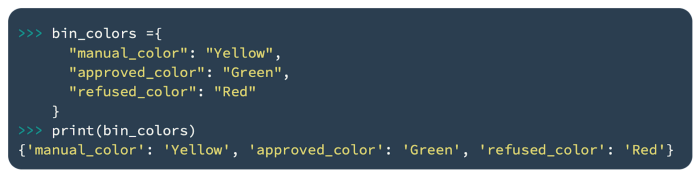
As shown in the following screenshot, the preceding code creates three key-value pairs:
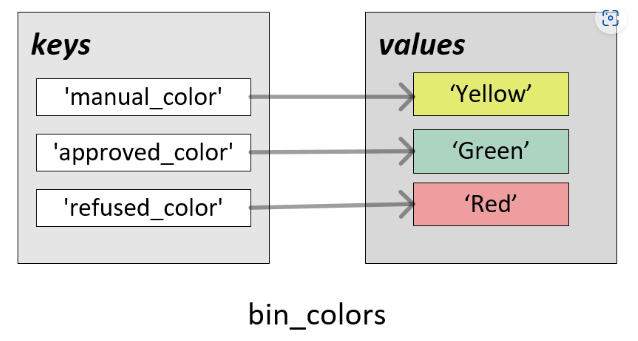
The following code retrieves and updates a value associated with a key:
A key can be used as the index or the get function can be used to retrieve a value associated with it:

Using the following code, you can update the value associated with a key:

We can update a value in a dictionary by updating its key in the preceding code.
An estimate of a dictionary’s time complexity
A dictionary in Big O notation has the following time complexity:
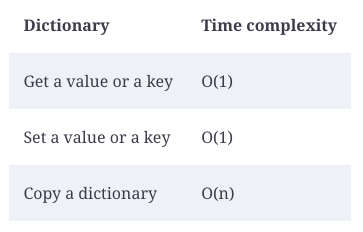
Based on the complexity analysis of the dictionary, it is important to note that key-value retrieval or setting is independent of dictionary size. In other words, adding a key-value pair to a dictionary of three dimensions takes the same amount of time as adding a pair to a dictionary of one million dimensions.
The sets
Sets are collections of elements with different types. Within [] are the elements. Check out the following code block as an example:

Sets are characterized by storing only distinct values for each element. The following illustration illustrates what happens if you try to add another redundant element:

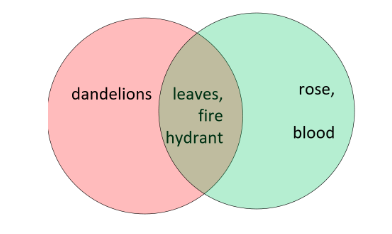
Let’s define two sets to illustrate what operations can be performed on them:
Things that are yellow belong to a set called yellow
There is another set named red, which contains red things
These two sets have some things in common. The following Venn diagram illustrates the relationship between the two sets:
These two sets can be implemented in Python as follows:

Here’s a Python code demonstrating set operations:

In Python, sets can be joined and intersected, as shown in the preceding code snippet. As we know, unions combine all of the elements of two sets, and intersections yield a set of elements that are common to both. The following should be noted:
To get the union of the two previously defined sets, use yellow|red.
In order to find the overlap between yellow and red, we use yellow&red.
Set time complexity analysis
The following is an analysis of the time complexity of sets:
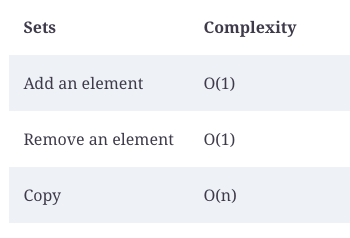
When the complexity analysis of the sets is performed, it becomes apparent that adding elements to a set does not take the same amount of time regardless of its size.
The DataFrame
Python’s pandas package provides DataFrames for storing tabular data. Traditionally structured data is processed using this data structure, which is one of the most important data structures for algorithms. Here is a table to consider:
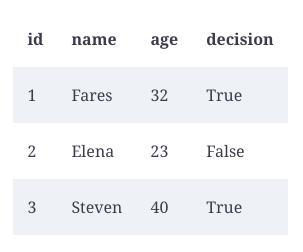
This can now be represented using a DataFrame.
By using the following code, we can create a simple DataFrame:
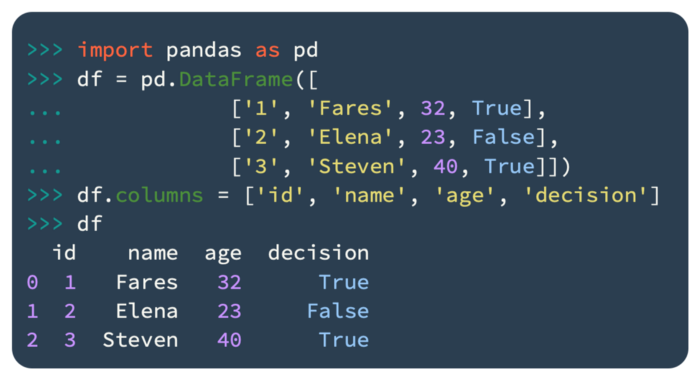
A list of column names is specified in df.column in the preceding code.
A tabular data structure can also be implemented using the DataFrame in other languages and frameworks. The Apache Spark framework and R are two examples.
DataFrame terminology
In this article, we’ll examine some of the terminology used in the context of DataFrames:
DataFrame columns or rows are called axes in the pandas documentation.
As a group, multiple axes are called axes.
DataFrames allow labels to be applied to both columns and rows.
DataFrame subset creation
It is possible to create a subset of a DataFrame in two different ways (say the name of the subset is myDF):
Selection of columns
Selection of rows
Let’s take a closer look at each of them.
Selection of columns
The selection of the appropriate set of features is one of the most important tasks in machine learning algorithms. Depending on the algorithm, not all features may be needed at a particular stage. The following section explains how Python features are selected by column selection.
It is possible to retrieve a column by its name, as in the following example:
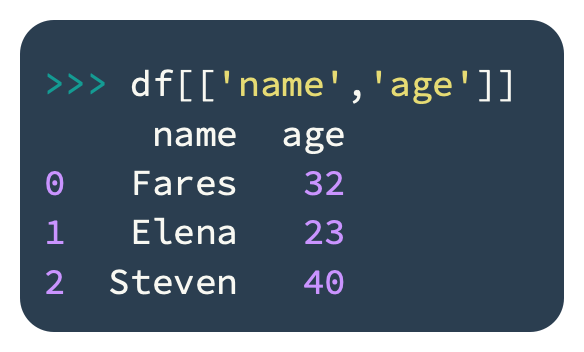
DataFrames position columns deterministically. In order to retrieve a column by its position, follow these steps:
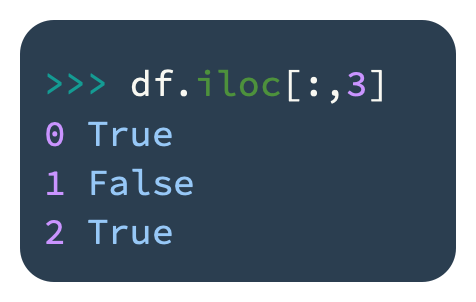
It is important to note that we are retrieving only the first three rows of the DataFrame in this code.
Selection of rows
DataFrame rows represent data points in our problem space. Creating a subset of our problem space requires row selection. There are two ways to create this subset:
Positioning them by specifying where they are
Filtering is done by specifying one
By identifying the row’s position, a subset of rows can be retrieved:
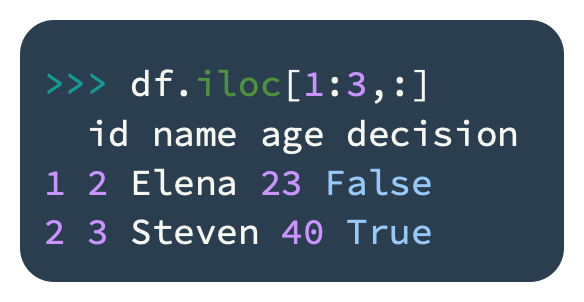
All columns and the first two rows will be returned by the preceding code.
The selection criteria for creating a subset can be defined by adding columns to the filter. Using this method, you can select a subset of data elements as follows:
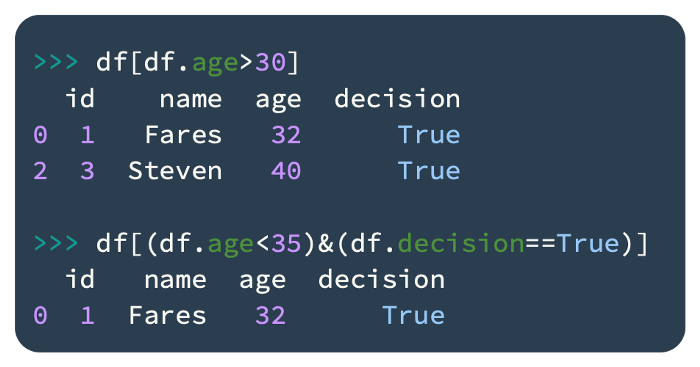
In this code, only those rows are created that satisfy the filter’s conditions.
The matrix
There are columns and rows in a matrix, which is a two-dimensional data structure. In a matrix, each element is identified by its column and row.
Numpy arrays can be used to create matrix values in Python, as shown below:
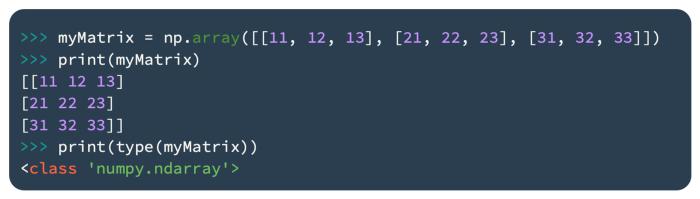
Three rows and three columns will be created by the preceding code.
Operation matrix
In matrix data manipulation, there are many operations available. Let’s try transposing the matrix above. Columns will be converted into rows and rows into columns using the transpose() function:
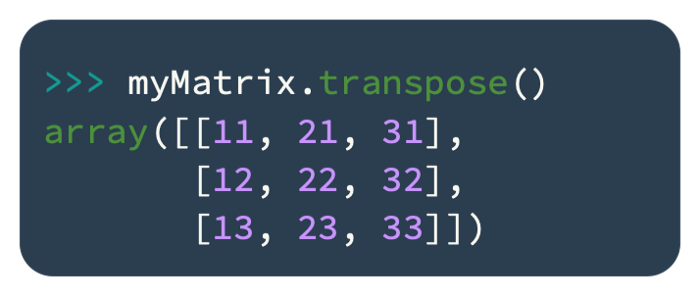
Multimedia data manipulation relies heavily on matrix operations.
Our next section will discuss abstract data types in Python after learning about data structures.
Abstract data types: an exploration
The rest of the article is under a paid subscription. It takes a lot of time to produce this detailed article, and I published an article every day. SO please if you can subscribe for just $5 a month. It is really helpful. Thanks for your consideration.
