

Deep Learning for Quant Trading
Decoding the StockMixer Architecture and PyTorch Pipeline

Download source code using the url at the end of this article!
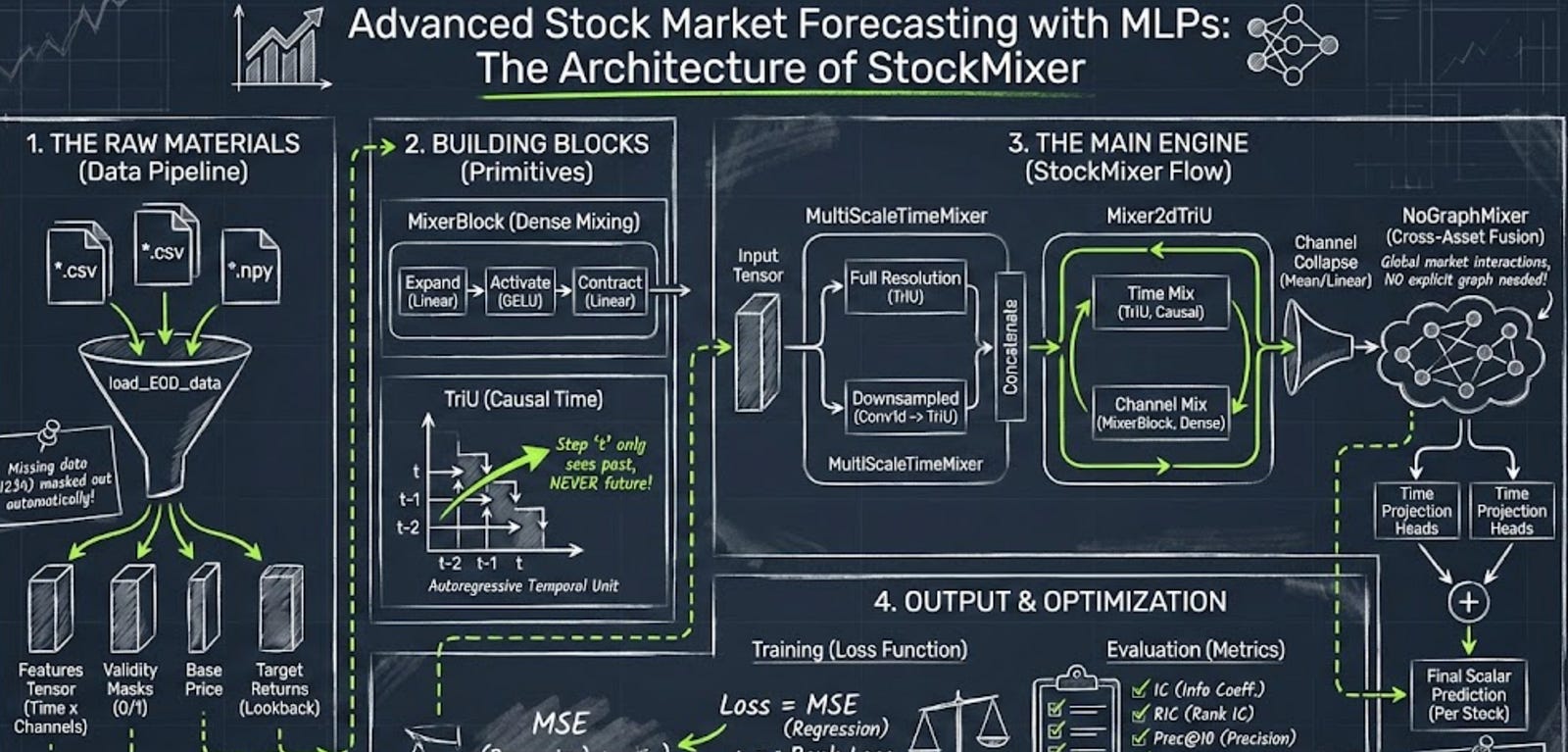
Forecasting the stock market requires a delicate balance: you need to capture how individual assets behave over time while simultaneously understanding how they influence each other — all without accidentally leaking future data into your training set. This article provides a comprehensive guide to the StockMixer architecture, a PyTorch forecasting engine that trades complex Transformers and Graph Neural Networks for elegant, highly efficient MLP mixers. In the following sections, you will read about the journey of a financial data tensor. We will walk through the data ingestion pipeline, explore the math and code behind multi-scale temporal and channel mixing, and break down the evaluation metrics that translate raw predictions into actionable quantitative signals.
# file path: src/model.py
import torch
import torch.nn as nn
import torch.nn.functional as FThe file imports the core PyTorch packages it needs to define neural building blocks: the top-level torch module for tensor objects and autograd, torch.nn (referred to as nn) for base classes like Module and the parameterized layer primitives used to construct MixerBlock and the specialized mixers, and torch.nn.functional (referred to as F) for the stateless ops used inside forward passes such as activation functions, dropout calls, and other functional kernels. In the context of the StockMixer-master_cleaned_cleaned architecture, these imports enable the file to declare layers and parameters with nn.Module subclasses and then implement the forward-time computations and mixing logic using the functional utilities in F. Compared with other modules in the project that import a broader set of utilities (random, numpy, os, data loaders, evaluator, pickle and higher-level symbols like get_loss and StockMixer), the imports here are intentionally minimal and focused on model construction; related concerns you saw elsewhere such as explicit device selection and seeding for reproducibility are handled in other parts of the codebase rather than in these model definitions.
# file path: src/model.py
acv = nn.GELU()Here an acv variable is assigned an instance of PyTorch’s GELU activation (nn.GELU), providing the concrete nonlinear function that the MixerBlock and the specialized channel/temporal/stock mixer primitives will call between their dense projections; in the context of the file that defines the core neural building blocks, acv serves as the shared, ready-to-use activation module that the composed mixers use to introduce nonlinearity in the MLP-centric mixing operations. This is consistent with the project choice of a smooth activation for dense mixer layers and complements the configuration-style entry where activation is recorded as the string ‘GELU’ (that line is just declaring the chosen activation by name, whereas acv is the actual callable instance). The fea_num setting that specifies the number of input channels is a separate concern (it defines how many feature dimensions the channel mixers will accept), and the StockMixer construction later in the code uses that channel count when wiring the model; acv is the instantiated nonlinearity that those channel and temporal mixing components will apply during forward computation.
# file path: src/model.py
def get_loss(prediction, ground_truth, base_price, mask, batch_size, alpha):
device = prediction.device
all_one = torch.ones(batch_size, 1, dtype=torch.float32).to(device)
return_ratio = torch.div(torch.sub(prediction, base_price), base_price)
reg_loss = F.mse_loss(return_ratio * mask, ground_truth * mask)
pre_pw_dif = torch.sub(
return_ratio @ all_one.t(),
all_one @ return_ratio.t()
)
gt_pw_dif = torch.sub(
all_one @ ground_truth.t(),
ground_truth @ all_one.t()
)
mask_pw = mask @ mask.t()
rank_loss = torch.mean(
F.relu(pre_pw_dif * gt_pw_dif * mask_pw)
)
loss = reg_loss + alpha * rank_loss
return loss, reg_loss, rank_loss, return_ratioget_loss computes the training objective used by validate after the StockMixer produces raw predictions and get_batch supplies the base price and mask. It first converts the model outputs and base_price into per-stock return ratios by subtracting base_price from prediction and dividing by base_price, then applies the per-stock mask so only valid instruments contribute to the regression term. The regression term reg_loss is a mean-squared error between the masked return ratios and the masked ground_truth, enforcing numeric accuracy of predicted returns. To capture ranking quality important for downstream evaluation in evaluate, get_loss constructs pairwise difference matrices for both predictions and ground truth by using an all-one vector to form outer-product style broadcasts; the predicted pairwise differences represent predicted_i minus predicted_j and the ground-truth pairwise differences are arranged as ground_truth_j minus ground_truth_i, so that a positive product indicates a disagreement in ordering. Those pairwise products are elementwise-multiplied by a pairwise mask formed from the input masks to ignore invalid stock pairs, passed through a ReLU to keep only ranking disagreements, and averaged to produce rank_loss. The final scalar loss is the sum of reg_loss and alpha-weighted rank_loss, and get_loss returns the combined loss, the regression and ranking components separately, and the computed return_ratio so validate can collect the per-stock predicted returns for evaluation.
# file path: src/model.py
class MixerBlock(nn.Module):
def __init__(self, mlp_dim, hidden_dim, dropout=0.0):
super(MixerBlock, self).__init__()
self.mlp_dim = mlp_dim
self.dropout = dropout
self.dense_1 = nn.Linear(mlp_dim, hidden_dim)
self.LN = acv
self.dense_2 = nn.Linear(hidden_dim, mlp_dim)
def forward(self, x):
x = self.dense_1(x)
x = self.LN(x)
if self.dropout != 0.0:
x = F.dropout(x, p=self.dropout)
x = self.dense_2(x)
if self.dropout != 0.0:
x = F.dropout(x, p=self.dropout)
return xMixerBlock is the simple two-layer MLP primitive the rest of the mixer stack reuses to perform dense mixing along an axis. On initialization it records the projection width and dropout rate and creates a first linear projection from the declared mlp_dim into a hidden_dim, stores the activation module referenced as acv under the attribute LN, and creates a second linear projection that maps the hidden representation back to the original mlp_dim. At runtime the forward path applies the first linear, runs the result through the stored activation, optionally applies dropout, projects back to mlp_dim with the second linear, and may apply dropout again before returning the output. Conceptually it provides the classic expand-activate-contract MLP bottleneck used by channel and time mixers: it raises representational capacity by expanding into a wider hidden space and then compresses back, while dropout provides regularization. MixerBlock itself does not perform normalization or residual addition; those are handled by its callers (for example, Mixer2d applies LayerNorm and residual connections around time and channel mixers), and time-specialized mixers use alternative primitives (TriU/TimeMixerBlock) where autoregressive structure is required.
# file path: src/model.py
def __init__(self, mlp_dim, hidden_dim, dropout=0.0):
super(MixerBlock, self).__init__()
self.mlp_dim = mlp_dim
self.dropout = dropout
self.dense_1 = nn.Linear(mlp_dim, hidden_dim)
self.LN = acv
self.dense_2 = nn.Linear(hidden_dim, mlp_dim)MixerBlock.init wires up the reusable two-layer MLP primitive that the rest of the mixers use to perform axis-wise mixing. It stores the mlp_dim and dropout settings on the instance so other components can treat the block parametrically, and it constructs two linear projection layers: the first projects from the axis dimension into a hidden representation and the second projects back to the original axis dimension, allowing the block to expand and then compress feature information along whichever axis it is applied to (time or channel when Mixer2d constructs timeMixer and channelMixer). It also assigns LN to acv so that a common nonlinearity/normalization callable will be applied between the two projections during forward. The dropout value saved here controls whether stochastic regularization is applied after each projection in the forward pass. In short, MixerBlock.init prepares the projection, activation/normalization, and dropout components that implement the MLP-style mixing step used throughout the model’s channel, temporal, and stock-mixing pipelines.
# file path: src/model.py
def forward(self, x):
x = self.dense_1(x)
x = self.LN(x)
if self.dropout != 0.0:
x = F.dropout(x, p=self.dropout)
x = self.dense_2(x)
if self.dropout != 0.0:
x = F.dropout(x, p=self.dropout)
return xMixerBlock.forward implements the simple two-layer feed‑forward step that each mixer primitive uses to mix features: it takes the incoming tensor and first runs it through the dense_1 projection that was created in MixerBlock.init to expand from the block’s MLP dimension into the hidden bottleneck, then applies the configured nonlinearity stored in LN (which here references the acv activation). After that it may apply dropout if the instance’s dropout value is nonzero — that is the first conditional branch. The tensor is then projected back to the original MLP dimensionality via dense_2, and a second conditional dropout may be applied before the result is returned. Conceptually this is the standard expand‑apply‑contract MLP pattern used inside the model’s mixers: dense_1 -> activation -> optional dropout -> dense_2 -> optional dropout, producing a transformed feature tensor that upstream mixers such as the time and channel mixers consume to perform temporal or channel mixing.
# file path: src/model.py
class Mixer2d(nn.Module):
def __init__(self, time_steps, channels):
super(Mixer2d, self).__init__()
self.LN_1 = nn.LayerNorm([time_steps, channels])
self.LN_2 = nn.LayerNorm([time_steps, channels])
self.timeMixer = MixerBlock(time_steps, time_steps)
self.channelMixer = MixerBlock(channels, channels)
def forward(self, inputs):
x = self.LN_1(inputs)
x = x.permute(0, 2, 1)
x = self.timeMixer(x)
x = x.permute(0, 2, 1)
x = self.LN_2(x + inputs)
y = self.channelMixer(x)
return x + yMixer2d implements the two-dimensional mixing primitive that alternates an axis-wise temporal MLP and an axis-wise channel MLP to fuse per-stock features across time and indicators. During construction Mixer2d allocates two LayerNorms named LN_1 and LN_2 that expect a tensor shaped by time_steps and channels, and it creates a timeMixer and a channelMixer by instantiating MixerBlock for the time axis and for the channel axis respectively. On the forward path an input tensor shaped batch × time × channels is first normalized with LN_1, then its axes are permuted so that the time axis becomes the last dimension; the timeMixer (a MixerBlock configured with mlp_dim equal to time_steps) is applied across that last dimension to capture temporal interactions per channel, and the result is permuted back to restore the batch × time × channels layout. That time-mixed output is added back to the original inputs and normalized by LN_2, producing a residual-stabilized representation which is then fed into the channelMixer (a MixerBlock configured with mlp_dim equal to channels) to mix information across indicator channels at each time step. The final output is produced by adding the channelMixer’s update to the residual-normalized tensor. Mixer2d therefore implements the axis-alternating MLP-Mixer pattern: normalize, mix across time, residual+normalize, mix across channels, and return the residual-summed result. MixerBlock.forward (previously explained) performs the actual two-layer dense projections with the shared activation and optional dropout, so the two MixerBlock instances realize the per-axis MLP transforms; Mixer2dTriU is the closely related variant that swaps the timeMixer for TriU to impose causal/multi-scale temporal structure.
# file path: src/model.py
def __init__(self, time_steps, channels):
super(Mixer2d, self).__init__()
self.LN_1 = nn.LayerNorm([time_steps, channels])
self.LN_2 = nn.LayerNorm([time_steps, channels])
self.timeMixer = MixerBlock(time_steps, time_steps)
self.channelMixer = MixerBlock(channels, channels)Mixer2d.init sets up the two-step, axis-separable mixing unit that the model uses to fuse temporal patterns and per-stock feature (channel) signals. It constructs two LayerNorm modules sized to the incoming 2D token layout so normalization operates over the time and channel dimensions before and after temporal processing. It then instantiates a timeMixer as a MixerBlock configured to operate along the time axis (using the time dimension as the MLP width) and a channelMixer as a MixerBlock configured to operate along the channel axis (using the channel count as the MLP width). That arrangement implements the factorized mixing pattern the engine relies on: normalize, apply an MLP-style mixing across time (the forward method permutes the tensor so the timeMixer sees the time axis as the feature axis), permute back, apply a second normalization with a residual connection, and then apply channel-wise MLP mixing. Mixer2d.init therefore composes two reusable MixerBlock primitives into the canonical temporal-then-channel mixer used throughout the forecasting blocks; Mixer2dTriU follows the same structure but swaps the temporal MixerBlock for a TriU variant to enforce causal, autoregressive ordering.
# file path: src/model.py
def forward(self, inputs):
x = self.LN_1(inputs)
x = x.permute(0, 2, 1)
x = self.timeMixer(x)
x = x.permute(0, 2, 1)
x = self.LN_2(x + inputs)
y = self.channelMixer(x)
return x + yMixer2d.forward implements the two-step mixer pattern that this file defines: first it normalizes and applies the temporal mixer so each indicator stream is processed along the look-back horizon, then it normalizes the residual and applies the channel mixer to fuse features across indicators. Concretely, the input tensor is normalized by LN_1 and its time and channel axes are swapped so the timeMixer instance (a MixerBlock configured with the look-back length) sees the time dimension as the feature axis it expects; after timeMixer does its small MLP-style mixing across the temporal axis the axes are swapped back to the original layout. That temporally mixed output is added residually to the original inputs and normalized by LN_2, and then the channelMixer instance (a MixerBlock configured with the channel count) performs dense mixing across the indicator/channel axis. The method returns the sum of the post-normalized temporal residual and the channel-mixed output, preserving residual connections for gradient flow and feature preservation while realizing the sequential temporal-then-channel mixing primitive used throughout the MLP-centric forecasting architecture.
# file path: src/model.py
class TriU(nn.Module):
def __init__(self, time_step):
super(TriU, self).__init__()
self.time_step = time_step
self.triU = nn.ParameterList(
[
nn.Linear(i + 1, 1)
for i in range(time_step)
]
)
def forward(self, inputs):
x = self.triU[0](inputs[:, :, 0].unsqueeze(-1))
for i in range(1, self.time_step):
x = torch.cat([x, self.triU[i](inputs[:, :, 0:i + 1])], dim=-1)
return xTriU implements the triangular (causal) temporal unit used for autoregressive time mixing: it registers a list of small linear modules where the k-th module consumes the first k+1 time steps and produces a single scalar output for that time position. At runtime TriU expects its input in batch-by-channel-by-time order (Mixer2dTriU permutes to that shape before calling it), and it computes the transformed time series one position at a time: it first applies the first linear module to the time-0 slice to produce the first output, then iteratively applies the i-th linear module to the window spanning time 0..i to produce the i-th output, concatenating each scalar along the time axis to rebuild a per-channel time sequence. Because each output only depends on current and earlier time steps, TriU enforces causal, autoregressive ordering for temporal mixing; its outputs are then fed back into the surrounding blocks (for example, LayerNorm and the channel mixer in Mixer2dTriU, or stacked in MultiScaleTimeMixer after downsampling). Conceptually TriU differs from MixerBlock’s dense time mixer by using independent, progressively wider linear projections per output timestep to capture growing temporal context while preserving causality, and it operates independently per channel and per batch element.
# file path: src/model.py
def __init__(self, time_step):
super(TriU, self).__init__()
self.time_step = time_step
self.triU = nn.ParameterList(
[
nn.Linear(i + 1, 1)
for i in range(time_step)
]
)TriU.init prepares the triangular, causal temporal mixing unit that the model uses to enforce autoregressive ordering over the look‑back horizon: it records the provided time_step on the instance and then constructs a tracked sequence of small linear modules so that the k‑th module consumes the first k+1 time positions and collapses them to a single scalar for that output time index. By calling the parent module initializer and storing the linear modules in a ParameterList, TriU.init ensures those per‑time linear weights are registered with PyTorch and available to TriU.forward, which will invoke them sequentially to build the time‑wise outputs. This initialization is why TimeMixerBlock, Mixer2dTriU, MultiScaleTimeMixer and other temporal mixers can plug in TriU as their timeMixer primitive to realize the triangular, causal temporal mixing behavior described in the architecture.
# file path: src/model.py
def forward(self, inputs):
x = self.triU[0](inputs[:, :, 0].unsqueeze(-1))
for i in range(1, self.time_step):
x = torch.cat([x, self.triU[i](inputs[:, :, 0:i + 1])], dim=-1)
return xTriU.forward consumes the per-batch, per-stock time-series tensor and produces a new time-aligned sequence where each time position is computed by a dedicated linear projector that only sees that time position and its past — enforcing the triangular, causal receptive field TriU.init set up. It begins by producing the time‑zero output via the first linear in triU applied to the single-step slice for time zero, then enters a loop over subsequent time indices; at each index i it calls the i-th linear on the prefix of the input spanning times zero through i, producing a single scalar for that time position and concatenating that scalar onto the growing output along the time axis. Because triU was constructed as a list of linears whose input widths increase from one up to the full horizon, each produced scalar depends only on the allowed past, so the forward pass yields a time-wise vector of learned causal summaries (when time_step equals one the loop is skipped and only the initial projection is used). Compared with Mixer2d, which mixes across the whole look-back and channels, TriU.forward implements the autoregressive triangular temporal mixing primitive that will be consumed by higher-level blocks.
# file path: src/model.py
class TimeMixerBlock(nn.Module):
def __init__(self, time_step):
super(TimeMixerBlock, self).__init__()
self.time_step = time_step
self.dense_1 = TriU(time_step)
self.LN = acv
self.dense_2 = TriU(time_step)
def forward(self, x):
x = self.dense_1(x)
x = self.LN(x)
x = self.dense_2(x)
return xTimeMixerBlock implements a dedicated temporal mixing primitive that swaps the dense linear layers used by MixerBlock.forward for causal, triangular temporal operators. Its constructor records the time_step, builds two TriU modules to serve as the first and second “dense” stages, and references the acv nonlinearity as its LN. At runtime the forward pass threads the input through the first TriU, applies acv, then passes the activated result through the second TriU and returns the output. Conceptually this produces a two-layer temporal MLP where every layer is triangular (autoregressive): each output time position is produced from a prefix of earlier time steps via the TriU linear maps, so the block enforces causal ordering while learning temporal mixing. This contrasts with MixerBlock.forward which uses full linear expand/contract projections and optional dropout; TimeMixerBlock replaces those dense projections with TriU to achieve time-causal behavior and assumes the caller has arranged the tensor axes so TriU operates along the time axis (for example, Mixer2dTriU permutes axes before invoking its time mixer). In the overall architecture TimeMixerBlock is the compact building block used whenever the model needs causal temporal mixing instead of a generic dense temporal projection, and it composes naturally into the larger 2D and multiscale mixers that coordinate channel, temporal, and stock mixing.
# file path: src/model.py
def __init__(self, time_step):
super(TimeMixerBlock, self).__init__()
self.time_step = time_step
self.dense_1 = TriU(time_step)
self.LN = acv
self.dense_2 = TriU(time_step)TimeMixerBlock.init builds a compact, two‑stage temporal mixer that specializes the general two‑layer MixerBlock pattern to enforce causal, autoregressive ordering along the time axis. It first initializes the module base and records the provided time_step so the block and its submodules know the look‑back horizon they operate over. Instead of the dense linear projections that MixerBlock.init creates, it constructs two TriU instances and assigns them to dense_1 and dense_2, and it sets LN to the acv activation; these three attributes are the exact components that TimeMixerBlock.forward wires together at runtime. The practical effect is that the familiar two‑layer feed‑forward flow we covered for MixerBlock.forward is retained here — an input is passed through the first temporal operator, then through the nonlinearity, then through the second temporal operator — but both projection steps are implemented by TriU so every position’s computation is triangular/causal (the k‑th TriU submodule only consumes the first k+1 time steps). This mirrors the use of TriU as the timeMixer in Mixer2dTriU and the temporal primitives used by the multi‑scale mixers, but TimeMixerBlock packages that causal two‑stage structure as a standalone block dedicated to time mixing.
# file path: src/model.py
def forward(self, x):
x = self.dense_1(x)
x = self.LN(x)
x = self.dense_2(x)
return xTimeMixerBlock.forward orchestrates the block’s causal time mixing by running the incoming tensor through a two-stage temporal transform: it first applies the TriU instance assigned to dense_1 to perform the autoregressive, triangular mixing over the look-back horizon, then applies the acv nonlinearity stored in LN, and finally passes the activated result through the second TriU instance assigned to dense_2 before returning it. Conceptually this mirrors the two-layer pattern you saw in MixerBlock.forward—an expand/activate/collapse sequence—but here the linear projections are replaced with triangular, prefix‑consuming TriU modules so every step of the transform respects autoregressive ordering; there is no dropout or branching in the control flow, so the happy path simply threads data through TriU → acv → TriU and hands the temporally mixed output back to the caller.
# file path: src/model.py
class MultiScaleTimeMixer(nn.Module):
def __init__(self, time_step, channel, scale_count=1):
super(MultiScaleTimeMixer, self).__init__()
self.time_step = time_step
self.scale_count = scale_count
self.mix_layer = nn.ParameterList([nn.Sequential(
nn.Conv1d(in_channels=channel, out_channels=channel, kernel_size=2 ** i, stride=2 ** i),
TriU(int(time_step / 2 ** i)),
nn.Hardswish(),
TriU(int(time_step / 2 ** i))
) for i in range(scale_count)])
self.mix_layer[0] = nn.Sequential(
nn.LayerNorm([time_step, channel]),
TriU(int(time_step)),
nn.Hardswish(),
TriU(int(time_step))
)
def forward(self, x):
x = x.permute(0, 2, 1)
y = self.mix_layer[0](x)
for i in range(1, self.scale_count):
y = torch.cat((y, self.mix_layer[i](x)), dim=-1)
return yMultiScaleTimeMixer implements a multi-resolution temporal mixing stage that builds richer time-aware representations for the rest of the forecasting pipeline by running the input sequence through several scale-specific temporal pipelines and concatenating their outputs. On construction it records the configured time_step and scale_count and creates mix_layer as a ParameterList of sequential scale modules: for scales greater than zero each module is a downsampling path that first reduces temporal resolution with a Conv1d whose kernel and stride are powers of two, then applies a TriU causal temporal unit, a nonlinearity using Hardswish, and a second TriU to form a small two-stage temporal feedforward at the reduced timescale; the scale‑zero entry is explicitly replaced with a full-resolution path that uses LayerNorm followed by TriU, Hardswish and another TriU instead of the Conv1d downsampler. In forward the incoming per-stock sequence tensor is permuted so the channel dimension becomes the convolution channel axis, the full-resolution path is evaluated first to produce the base temporal features, and then each additional scale path is applied and its output concatenated along the last feature dimension to accumulate multi-scale temporal signals. Because TriU enforces autoregressive, prefix-aware aggregation (as explained earlier), each scale produces causal summaries of its receptive field; concatenating these scale outputs yields a composite temporal representation that downstream components such as MultTime2dMixer and StockMixer can consume to fuse temporal, channel and cross-asset information.
# file path: src/model.py
def __init__(self, time_step, channel, scale_count=1):
super(MultiScaleTimeMixer, self).__init__()
self.time_step = time_step
self.scale_count = scale_count
self.mix_layer = nn.ParameterList([nn.Sequential(
nn.Conv1d(in_channels=channel, out_channels=channel, kernel_size=2 ** i, stride=2 ** i),
TriU(int(time_step / 2 ** i)),
nn.Hardswish(),
TriU(int(time_step / 2 ** i))
) for i in range(scale_count)])
self.mix_layer[0] = nn.Sequential(
nn.LayerNorm([time_step, channel]),
TriU(int(time_step)),
nn.Hardswish(),
TriU(int(time_step))
)MultiScaleTimeMixer.init sets up a small bank of parallel, trainable temporal mixers that produce multi‑horizon time representations for the rest of the model to consume. It records the provided time_step and scale_count and then builds mix_layer as a registered list of sequential modules, one per scale. For scales above zero each module begins with a 1D convolution that down‑samples the time axis with kernel and stride equal to powers of two so that progressively coarser temporal resolutions are produced; that downsampled signal is then passed through a TriU block, a Hardswish nonlinearity, and a second TriU block to perform causal, autoregressive time mixing at that coarser horizon. The scale‑zero path is replaced with a full‑resolution branch that uses a LayerNorm over the [time_step, channel] axes instead of convolution and otherwise applies the same TriU → Hardswish → TriU sequence, preserving the native temporal resolution as the base representation. Using a ParameterList of Sequential modules ensures all per‑scale parameters are registered and optimized together. Conceptually this implements a parallel multi‑scale temporal tower: each branch produces a temporally mixed view of the input at a different horizon (with TriU enforcing causal time mixing as previously discussed), and MultiScaleTimeMixer.forward will permute the input into channel‑first layout, apply the base branch, then concatenate the other scale outputs along the last dimension to form the combined multi‑horizon temporal feature used by downstream channel and stock mixers.
# file path: src/model.py
def forward(self, x):
x = x.permute(0, 2, 1)
y = self.mix_layer[0](x)
for i in range(1, self.scale_count):
y = torch.cat((y, self.mix_layer[i](x)), dim=-1)
return yMultiScaleTimeMixer.forward begins by swapping the time and channel axes of the incoming tensor so the sequence dimension is in the position expected by the Conv1d/TriU processing defined in MultiScaleTimeMixer.init. It then runs the full-resolution branch stored at mix_layer[0] to produce an initial temporal embedding y; recall that mix_layer[0] was specialized in the constructor to use LayerNorm and TriU units so it produces a causal, full‑resolution temporal representation. After that the method enters a loop over the remaining scale indices (from 1 up to scale_count−1); for each scale it invokes the corresponding mix_layer entry, which represents a downsampling path built from Conv1d followed by TriU and nonlinearities, and concatenates each scale’s output onto y along the final feature axis. The concatenation assembles multiscale, causal temporal features side‑by‑side so downstream blocks receive a single tensor that encodes multiple look‑back resolutions; if scale_count is one the loop is skipped and only the full‑resolution branch is returned. The returned y is therefore a multiscale temporal embedding ready for the subsequent mixing stages in the forecast pipeline.
# file path: src/model.py
class Mixer2dTriU(nn.Module):
def __init__(self, time_steps, channels):
super(Mixer2dTriU, self).__init__()
self.LN_1 = nn.LayerNorm([time_steps, channels])
self.LN_2 = nn.LayerNorm([time_steps, channels])
self.timeMixer = TriU(time_steps)
self.channelMixer = MixerBlock(channels, channels)
def forward(self, inputs):
x = self.LN_1(inputs)
x = x.permute(0, 2, 1)
x = self.timeMixer(x)
x = x.permute(0, 2, 1)
x = self.LN_2(x + inputs)
y = self.channelMixer(x)
return x + yMixer2dTriU implements the familiar two-stage temporal-then-channel mixing pattern used throughout the forecast engine, but it swaps the dense time MLP for the causal TriU so the temporal pass respects autoregressive ordering. On initialization it creates two layer‑norms that operate over the time and channel axes, instantiates a TriU as its timeMixer, and builds a channelMixer using MixerBlock to perform the per-indicator dense fusion. At runtime the forward path expects the usual tensor shaped by time and channels: it first normalizes the incoming tensor with the first LayerNorm, then permutes axes so the TriU sees each channel’s time series as a sequence; TriU then performs the triangular, causal aggregation across look‑back steps (the component you already saw implemented in TriU). After permuting the time-mixed output back to the original axis order it adds the original inputs as a residual and applies the second LayerNorm; that normalized residual is handed to channelMixer, which uses the MixerBlock feed‑forward pattern you previously learned to mix information across indicators for each time step. Finally it returns the sum of the channel mixer’s output with the pre-mixer residual so gradients and original signal flow cleanly. Functionally, Mixer2dTriU mirrors Mixer2d’s control flow and residual/normalization structure but enforces causality in time by using TriU for the temporal stage, and MultTime2dMixer composes two instances of Mixer2dTriU to produce the multiscale concatenation used by the StockMixer.
# file path: src/model.py
def __init__(self, time_steps, channels):
super(Mixer2dTriU, self).__init__()
self.LN_1 = nn.LayerNorm([time_steps, channels])
self.LN_2 = nn.LayerNorm([time_steps, channels])
self.timeMixer = TriU(time_steps)
self.channelMixer = MixerBlock(channels, channels)Mixer2dTriU.init wires up the four core components that the Mixer2dTriU block will use at runtime: two LayerNorms and two mixers. It creates LN_1 and LN_2 as layer normalizers configured for the pair of axes defined by the passed time_steps and channels so the block can normalize across the full time×channel patch before and after time mixing. For temporal processing it instantiates timeMixer as a TriU configured with the same time_steps so the block will apply the triangular, causal temporal unit that enforces autoregressive ordering over the look‑back horizon. For channel mixing it reuses the MixerBlock primitive by creating channelMixer with channels as both its input and internal MLP dimension so the block will run the two‑layer feature mixer (the dense_1 → acv → dense_2 pattern you already saw in MixerBlock.forward) to fuse indicators at each time position. This mirrors Mixer2d.init in structure (two LayerNorms and a channel MixerBlock), but replaces the timeMixer MixerBlock with TriU to get causal time behavior; those attributes LN_1, LN_2, timeMixer, and channelMixer are what Mixer2dTriU.forward later composes (with the known permute/triangular temporal call and residual path) to perform time‑then‑channel mixing and return the fused output used by MultTime2dMixer and StockMixer.
# file path: src/model.py
def forward(self, inputs):
x = self.LN_1(inputs)
x = x.permute(0, 2, 1)
x = self.timeMixer(x)
x = x.permute(0, 2, 1)
x = self.LN_2(x + inputs)
y = self.channelMixer(x)
return x + yMixer2dTriU.forward performs a two-stage mix with normalization and residuals: it first normalizes the incoming batch/time/channel tensor with LN_1, then swaps the time and channel axes so the sequence dimension sits where TriU expects it (the same axis-swap pattern you saw in MultiScaleTimeMixer.forward). With the axes swapped it dispatches the data into timeMixer, which is the TriU causal temporal mixer that enforces autoregressive ordering and produces a temporally mixed sequence representation. The forward then swaps the axes back to restore the original time-by-channel layout and immediately adds the original inputs before applying LN_2, so the temporally processed signal is combined with the raw input via a residual path and re-normalized. Next it calls channelMixer, the MixerBlock that performs dense indicator/channel mixing across features at each time step, producing a channel-mixing correction y. Finally it returns the sum of the post-time-normalized tensor and that channel-mixing correction, preserving residual connections so the block learns incremental updates rather than replacing input information. This flow is identical in structure to Mixer2d.forward except the temporal stage uses TriU to keep the temporal pass causal for forecasting.
# file path: src/model.py
class MultTime2dMixer(nn.Module):
def __init__(self, time_step, channel, scale_dim=8):
super(MultTime2dMixer, self).__init__()
self.mix_layer = Mixer2dTriU(time_step, channel)
self.scale_mix_layer = Mixer2dTriU(scale_dim, channel)
def forward(self, inputs, y):
y = self.scale_mix_layer(y)
x = self.mix_layer(inputs)
return torch.cat([inputs, x, y], dim=1)MultTime2dMixer constructs two Mixer2dTriU instances at initialization: one configured for the full lookback horizon and one configured for a shorter scale dimension, so it can produce both full-resolution and coarse temporal mixes. At runtime it first runs the scale-side Mixer2dTriU over the auxiliary y input (the downsampled/conv-processed sequence produced by StockMixer), then runs the main Mixer2dTriU over the original inputs; because Mixer2dTriU (as you already saw) applies a TriU causal temporal pass followed by a channel MixerBlock, both outputs preserve the batch × time × channel shape while embedding autoregressive temporal structure and per-channel interactions. Finally, MultTime2dMixer concatenates the original inputs, the full-resolution mixed output, and the scale-mixed output along the temporal axis to produce an augmented time-axis tensor; this augmented tensor supplies the combined multi‑resolution temporal context expected later by StockMixer’s time projection and the cross-asset NoGraphMixer, effectively fusing raw, fine-grained, and coarse temporal representations for downstream channel and stock mixing.
# file path: src/model.py
def __init__(self, time_step, channel, scale_dim=8):
super(MultTime2dMixer, self).__init__()
self.mix_layer = Mixer2dTriU(time_step, channel)
self.scale_mix_layer = Mixer2dTriU(scale_dim, channel)MultTime2dMixer.init builds two parallel 2D TriU-based mixer instances so the module can produce both a full-resolution temporal-channel mixed representation and a compact, lower‑temporal‑resolution mixed representation for multi‑scale fusion. It begins by initializing the module as a nn.Module, then creates mix_layer as a Mixer2dTriU configured for the provided time_step and channel counts and creates scale_mix_layer as a second Mixer2dTriU configured for the smaller scale_dim time axis (scale_dim defaults to eight). The intention is that inputs will be passed through mix_layer and a separate, shorter sequence tensor (y) will be passed through scale_mix_layer and the two outputs (together with the original inputs) will later be concatenated by forward to produce a richer, multi‑horizon tensor. Because Mixer2dTriU uses TriU for causal temporal mixing and a MixerBlock for channel mixing (as covered earlier), these two mixer instances give both autoregressive-aware temporal processing and per‑channel projection at two resolutions; this is a lighter-weight way to obtain multi‑scale temporal features compared with the convolutional parallel bank implemented in MultiScaleTimeMixer. The small scale_dim variant is what StockMixer instantiates when it requests a MultTime2dMixer with a compact temporal embedding to feed into subsequent channel and time linear heads.
# file path: src/model.py
def forward(self, inputs, y):
y = self.scale_mix_layer(y)
x = self.mix_layer(inputs)
return torch.cat([inputs, x, y], dim=1)MultTime2dMixer.forward accepts the main sequence tensor named inputs and an auxiliary scale tensor y, runs y through the instance’s scale_mix_layer and inputs through the instance’s mix_layer (both are Mixer2dTriU objects created in MultTime2dMixer.init), and then concatenates the original inputs, the temporally processed output from mix_layer, and the scale-processed output from scale_mix_layer along the sequence/time axis before returning the result. Because Mixer2dTriU performs a causal temporal pass via TriU followed by channel mixing with a MixerBlock (as explained earlier), the mix_layer produces an autoregressively aware representation of the primary lookback window while the scale_mix_layer produces a compact, scale-specific temporal representation; concatenating inputs, x, and y therefore produces an expanded time-stacked tensor that fuses raw frames, main-horizon temporal features, and multi-scale temporal features for downstream channel- and stock-mixing stages to consume.
# file path: src/model.py
class NoGraphMixer(nn.Module):
def __init__(self, stocks, hidden_dim=20):
super(NoGraphMixer, self).__init__()
self.dense1 = nn.Linear(stocks, hidden_dim)
self.activation = nn.Hardswish()
self.dense2 = nn.Linear(hidden_dim, stocks)
self.layer_norm_stock = nn.LayerNorm(stocks)
def forward(self, inputs):
x = inputs
x = x.permute(1, 0)
x = self.layer_norm_stock(x)
x = self.dense1(x)
x = self.activation(x)
x = self.dense2(x)
x = x.permute(1, 0)
return xNoGraphMixer implements the cross‑asset mixing stage that StockMixer uses to fuse information across the stock axis without an explicit graph: it accepts the channel‑collapsed per
# file path: src/train.py
import random
import numpy as np
import os
import torch as torch
from load_data import load_EOD_data
from evaluator import evaluate
from model import get_loss, StockMixer
import pickleThe top-level imports bring together basic system utilities, data I/O, the model and loss logic, and evaluation helpers that train.py needs to orchestrate the data-to-model pipeline and the training/validation loop. random and numpy provide RNG and array utilities used when preparing reproducible batches and shuffling or manipulating the EOD data coming from load_EOD_data; os is available for filesystem operations such as checkpoint or results paths. torch supplies the core tensor, device, autograd, and optimizer machinery used to run forward passes and backprop when StockMixer is executed on a device. load_EOD_data is the data loader that supplies the end‑of‑day datasets the batching code will slice into lookback windows; evaluate is the external evaluator that validate will call to compute metrics on model outputs. get_loss supplies the training loss function that the loop applies to StockMixer predictions, and StockMixer is the model class that composes mixer primitives such as MultiScaleTimeMixer and Mixer2dTriU (these were covered earlier) into the full forecasting network the training loop runs. pickle is included for serializing artifacts like saved checkpoints or cached datasets. Compared to similar import sets elsewhere in the project, train.py focuses less on layer-level imports (other modules import torch.nn and functional helpers) and more on wiring up higher-level components: it ties together data loading, the StockMixer model, the loss from model.py, and the evaluator rather than importing low-level neural building blocks.
# file path: src/train.py
activation = ‘GELU’The training script sets a configuration flag named activation to the GELU choice; that flag is the high-level selector the training orchestration uses when constructing MixerBlock instances so the mixer stages get the intended nonlinearity. MixerBlock.init ultimately stores an activation module into its self.LN using the activation instance provided at construction (the project also defines an acv instance of GELU elsewhere that is wired into those blocks), whereas NoGraphMixer constructs and uses a Hardswish instance locally inside its constructor. Putting the activation choice here alongside other hyperparameters lets the training/validation pipeline consistently determine which nonlinear function the temporal, channel and stock mixing primitives will use without modifying each module’s internal code.
# file path: src/model.py
def __init__(self, stocks, hidden_dim=20):
super(NoGraphMixer, self).__init__()
self.dense1 = nn.Linear(stocks, hidden_dim)
self.activation = nn.Hardswish()
self.dense2 = nn.Linear(hidden_dim, stocks)
self.layer_norm_stock = nn.LayerNorm(stocks)NoGraphMixer.init constructs a compact, per-timestep feed‑forward that mixes information across the universe of stocks without any explicit graph structure: it creates a linear projection that reduces the stocks dimension into a small hidden embedding, an element-wise nonlinearity, a second linear projection that maps back to the original stocks dimension, and a LayerNorm configured to operate across the stocks axis. In the architecture of the forecasting engine this block acts as the cross-asset mixer used by StockMixer to produce market-aware stock interactions; StockMixer assigns a NoGraphMixer instance to its stock_mixer, passing the number of stocks and a market-sized hidden_dim so the projection widths line up with the surrounding modules. Conceptually this follows the same two-layer MLP pattern you saw in MixerBlock.init, but specialized to operate across assets only (no time/channel two-stage composition, no dropout or the shared acv normalizer used in MixerBlock). The layer normalization is placed to normalize the stock axis before the two linear projections so the forward path (which permutes the axes) receives a consistent, normalized stock vector per sample; the default hidden_dim of 20 gives a small bottleneck embedding that the activation shapes before projecting back to stock space.
# file path: src/model.py
def forward(self, inputs):
x = inputs
x = x.permute(1, 0)
x = self.layer_norm_stock(x)
x = self.dense1(x)
x = self.activation(x)
x = self.dense2(x)
x = x.permute(1, 0)
return xNoGraphMixer.forward accepts the per-step representations produced earlier in the pipeline (for example the time-aware outputs coming out of the temporal mixers) and performs a compact cross-asset mixing pass: it first swaps the first two axes so the stock axis is placed where the subsequent LayerNorm and linear projections expect the feature dimension, then applies layer_norm_stock to normalize across the stock axis. After normalization it projects the stock-dimension into a smaller hidden space using dense1, applies the block’s pointwise nonlinearity (the instance’s Hardswish activation), and projects back to the original stock dimensionality with dense2. Finally it restores the original axis order and returns the result. Conceptually this is a simple two-layer MLP token-mixing step across assets (no residual addition or separate time/ channel passes like Mixer2d.forward); its role is to model cross-asset relationships after the temporal mixing stages have already produced time-aware features.
# file path: src/model.py
class StockMixer(nn.Module):
def __init__(self, stocks, time_steps, channels, market, scale):
super(StockMixer, self).__init__()
scale_dim = 8
self.mixer = MultTime2dMixer(time_steps, channels, scale_dim=scale_dim)
self.channel_fc = nn.Linear(channels, 1)
self.time_fc = nn.Linear(time_steps * 2 + scale_dim, 1)
self.conv = nn.Conv1d(in_channels=channels, out_channels=channels, kernel_size=2, stride=2)
self.stock_mixer = NoGraphMixer(stocks, market)
self.time_fc_ = nn.Linear(time_steps * 2 + scale_dim, 1)
def forward(self, inputs):
x = inputs.permute(0, 2, 1)
x = self.conv(x)
x = x.permute(0, 2, 1)
y = self.mixer(inputs, x)
y = self.channel_fc(y).squeeze(-1)
z = self.stock_mixer(y)
y = self.time_fc(y)
z = self.time_fc_(z)
return y + zStockMixer composes the temporal, channel and cross‑asset mixer primitives into the final per‑stock prediction head for the forecasting engine. In __
# file path: src/model.py
def __init__(self, stocks, time_steps, channels, market, scale):
super(StockMixer, self).__init__()
scale_dim = 8
self.mixer = MultTime2dMixer(time_steps, channels, scale_dim=scale_dim)
self.channel_fc = nn.Linear(channels, 1)
self.time_fc = nn.Linear(time_steps * 2 + scale_dim, 1)
self.conv = nn.Conv1d(in_channels=channels, out_channels=channels, kernel_size=2, stride=2)
self.stock_mixer = NoGraphMixer(stocks, market)
self.time_fc_ = nn.Linear(time_steps * 2 + scale_dim, 1)StockMixer.init sets up the three coordinated mixer stages and the small auxiliary layers that the forward path will combine into a final per‑stock scalar output. It begins with a small constant scale_dim set to eight and constructs a MultTime2dMixer configured with the supplied time_steps and channels and that scale_dim; that mixer is the temporal/core 2D mixing unit that we saw earlier, which internally uses a Mixer2dTriU for the main time axis and a second Mixer2dTriU operating at the smaller scale. StockMixer then creates a channel projection named channel_fc that will collapse the channel axis down to a single value per time step (the channel mixer / indicator fusion output), and two time projection layers named time_fc and time_fc_ sized to accept the combined time dimension produced by MultTime2dMixer (the concatenation of original time, the time-mixed output, and the scale-mixed output totals time_steps * 2 + scale_dim). To provide the scale-level input to the multiscale mixer, StockMixer builds a 1D convolution configured to downsample the time axis by a factor of two while preserving the channels; that convolved signal is what MultTime2dMixer uses as its scale input. For cross-asset mixing it instantiates a NoGraphMixer using the stocks and market parameters (NoGraphMixer performs the compact per-timestep stock mixing and normalization you already reviewed). The duplicate time_fc_ exists because the forward path produces two parallel temporal-aggregated streams — one that flows through the per-time channel collapse into time_fc and another that is produced by the stock_mixer and then reduced by time_fc_ — and the outputs of those two temporal reductions are combined to form the final prediction. The constructor also calls the module super initializer so these submodules are registered in the model.
# file path: src/model.py
def forward(self, inputs):
x = inputs.permute(0, 2, 1)
x = self.conv(x)
x = x.permute(0, 2, 1)
y = self.mixer(inputs, x)
y = self.channel_fc(y).squeeze(-1)
z = self.stock_mixer(y)
y = self.time_fc(y)
z = self.time_fc_(z)
return y + zThe forward path orchestrates the three mixing axes the project emphasizes: temporal multi-scale extraction, channel collapse, and cross-asset interaction. It first reorders the input so the channel axis is placed where the Conv1d expects it, runs a stride-2 1D convolution to produce a downsampled temporal view, and then swaps axes back so time/channel ordering is restored. It then hands both the original time-resolution tensor and the conv-produced downsample to MultTime2dMixer, which you’ve seen composes a primary Mixer2dTriU temporal pass with an auxiliary scale mixer and returns a concatenated multi-horizon representation. The channel_fc projection then collapses the channel dimension into a single scalar per time step (the squeeze removes that singleton channel axis), producing y as the channel-aggregated per-time signal. That per-time signal is sent through NoGraphMixer to produce z, invoking the cross-asset mixing behavior we already covered. Separately, y is reduced over time by time_fc and z is reduced by time_fc_ (they are two parallel time-aggregation heads operating on the channel-aggregated and stock-mixed streams respectively). The method returns the elementwise sum of those two scalar outputs, effectively fusing a time-only prediction head with a stock-aware prediction head to produce the final per-sample forecast.
# file path: src/train.py
np.random.seed(123456789)The statement sets NumPy’s global random number generator to a fixed, hard-coded seed so any randomness produced by NumPy — for example in data preprocessing, shuffling inside get_batch, synthetic feature perturbations, or any NumPy-based initialization used before PyTorch takes over — is deterministic across runs. Placing this early in train.py ensures that NumPy-driven steps that feed into the forward passes through NoGraphMixer, StockMixer and the other mixer stages behave reproducibly for training and validation. It complements the separate PyTorch seeding declared elsewhere that controls weight initialization, dropout and other torch-based randomness; together they lock down the two runtime RNG sources. Conceptually this line is similar to the nearby fixed hyperparameter assignments such as the learning rate and alpha in that it establishes a global, run-level configuration rather than a per-call decision, but it differs functionally because it governs stochastic behavior rather than numeric hyperparameters.
# file path: src/train.py
torch.random.manual_seed(12345678)The call to torch.random.manual_seed at the top of the training script fixes PyTorch’s pseudorandom number generator to a deterministic state so that subsequent tensor-level randomness—layer weight initializations inside NoGraphMixer.init and other module constructors, any stochastic behavior in MixerBlock instances such as dropout, and random tensor operations used during forward passes or in get_batch—will produce the same sequence of values across runs. In the context of src/train.py’s role of orchestrating data-to-model flow and training/validation, that deterministic PyTorch stream makes model initialization, training dynamics, and validation reproducibility repeatable when you rerun the script. This mirrors the nearby numpy RNG seeding performed by np.random.seed, which stabilizes randomness coming from NumPy-based operations (for example data shuffling or preprocessing that uses NumPy), while the device selection via torch.device and scalar settings like learning_rate serve different purposes: device chooses compute placement and learning_rate sets an optimization hyperparameter rather than controlling randomness.
# file path: src/train.py
device = torch.device(”cuda”) if torch.cuda.is_available() else ‘cpu’The statement selects the runtime compute device by asking PyTorch whether a CUDA GPU is available and assigning a device handle accordingly, so the training orchestration can place model parameters and tensors on the accelerator when present and fall back to the CPU otherwise. The device name is later used when moving the StockMixer instance to the chosen execution context and throughout the training and validation loops so the NoGraphMixer and other mixer primitives execute on the same hardware as the tensors they consume. Conceptually this is a global runtime configuration in the training script—similar in intent to the global random seed and the learning_rate assignments—so all subsequent data allocation, forward passes, and loss computations are consistent with the selected compute target; the value will be a PyTorch device object for CUDA or the CPU identifier used for the fallback.
# file path: src/train.py
data_path = ‘../dataset’data_path is a top-level configuration variable that points the training orchestration to the dataset root the script will read from; train.py uses this value when preparing batches in get_batch and when loading data for the validate routine so the model pipeline (including MixerBlock construction and the forward passes through NoGraphMixer and StockMixer) receives its input tensors from the intended storage location. It plays the same role as dataset_path, which is a closely related variable that builds a market-specific dataset locator by appending a market identifier, but data_path represents the more general base directory while dataset_path specializes it per market. Conceptually it is the I/O counterpart to other file-level constants like fea_num and learning_rate: all are top-level settings declared for the training run, but data_path configures where training and validation read their samples from, whereas fea_num and learning_rate configure model input dimensionality and optimization behavior respectively.
# file path: src/train.py
market_name = ‘NASDAQ’The variable market_name is a top-level configuration string set to NASDAQ that tells the training orchestration which market-specific dataset and resources to operate on; in the data-to-model pipeline it is the human-readable label that the script uses when forming dataset_path so get_batch and validate will load the correct market folder and files. It complements the numeric market_num flag (which is used when constructing StockMixer to convey a numeric market identifier into the model), so market_name serves the filesystem/data-selection role while market_num serves the model-initialization role. In short, market_name selects the market dataset used during training and evaluation, and works alongside market_num and the StockMixer construction to align dataset selection with the model’s market-aware inputs.
# file path: src/train.py
relation_name = ‘wikidata’The assignment establishes a top-level configuration identifier that tells the training orchestration which external relation source to use when preparing inputs and any relation-aware components. Within train.py this string is treated the same way as the other simple configuration constants you already saw such as the dataset location, horizon length, and validation split: it is read by the data-loading and batching logic so that get_batch and the validation routine know which relations file or knowledge base to load and attach to per-stock inputs. Even though NoGraphMixer performs a cross-asset pass without an explicit graph, StockMixer and the surrounding data pipeline can incorporate relational/knowledge features, and that loader/attachment step will pick the dataset named by this identifier. In short, this line sets the relation data source used downstream by the data I/O and model-input construction stages, following the same pattern as the other top-level configuration values but carrying a semantic name rather than a numeric or path value.
# file path: src/train.py
stock_num = 1026Assigning stock_num the value 1026 establishes the universe size the training run will operate on: it tells the data pipeline and model how many distinct asset channels to expect and therefore fixes the stocks dimension used throughout batching, tensor shapes, and parameter matrices. That scalar is consumed when constructing StockMixer via its stocks parameter, so it directly controls the width of the cross‑asset mixing primitives (for example the LayerNorm and linear projections inside NoGraphMixer that normalize and project across the stock axis) and therefore the number of outputs the prediction head must produce. Conceptually it follows the same pattern as other top‑level hyperparameters like market_num and steps, which respectively define how many market groups and how many prediction steps are used; all three are simple, global configuration constants declared at module scope so get_batch, the model instantiation, and the validation routine share a consistent view of input/output dimensions.
# file path: src/train.py
lookback_length = 16lookback_length defines the number of past timesteps the training pipeline will present to the model for each example: get_batch slices the dataset into windows of this length, the temporal mixer stages and any causal triangular unit operate over that many positions, and the per-step representations that NoGraphMixer.forward receives will have that time dimension length. In other words, lookback_length is an architectural/data-shaping hyperparameter that fixes the temporal receptive field the MixerBlock and StockMixer composition reason over during both forward passes and validation, and it therefore determines the tensor shapes and any autoregressive ordering applied by the temporal components. Compared to epochs, learning_rate, and alpha, which are training hyperparameters controlling optimization and regularization, lookback_length is a structural hyperparameter that sets how much historical context the forecasting engine uses.
# file path: src/train.py
epochs = 100The variable epochs is a high-level training hyperparameter that determines how many full passes the training loop in train.py will make over the dataset; the orchestration uses epochs to drive the outer loop that repeatedly calls get_batch, runs forward/backward passes through MixerBlock compositions like NoGraphMixer and StockMixer, accumulates gradients, applies optimizer steps, and invokes validate at the scheduled intervals. Setting epochs to 100 fixes the total number of these full dataset iterations for this run, so it controls overall training duration, how often model checkpoints and validation windows occur, and indirectly how many times the model will see each example. Conceptually epochs plays the same role as learning_rate and alpha as a runtime hyperparameter that shapes training dynamics, but unlike lookback_length which modifies the model’s input shape and the mixers’ temporal behavior, epochs only governs how long the optimizer will train the existing model architecture.
# file path: src/train.py
valid_index = 756valid_index is the integer cutoff that partitions the temporal dataset used by the training orchestration: it marks the boundary between the indices reserved for training-sampled windows and the later indices reserved for validation. get_batch uses that cutoff when it constructs batch_offsets so the training loop only draws sliding windows that start before valid_index, which ensures the MixerBlock construction and the forward passes through NoGraphMixer and StockMixer see only training examples during optimization. In practice that same split semantics is mirrored by test_index for the held-out test split, and best_valid_loss is tracked separately during validate; together these variables control the data flow through the data-to-model pipeline so lookback_length, stock_num and the market-specific dataset selected via data_path and market_name produce the correct training versus validation examples.
# file path: src/train.py
test_index = 1008test_index is a fixed integer configuration that tells the training orchestration which temporal slice of the market dataset to treat as the test fold when prepare-and-evaluate routines run. get_batch and validate use the value to compute the windowed ranges they read from the dataset_path (which itself is constructed from data_path and market_name) so that the temporal windows fed into NoGraphMixer and StockMixer have a consistent start position; the lookback_length and stock_num determine how that chosen index is expanded into a multi-timestep, multi-asset tensor for the forward pass. Conceptually it plays the same role as valid_index — both are fold selectors that pin down where validation and test examples come from — but test_index points at the held-out test period (the numeric value differs). It is different in intent from epochs, which controls how many training iterations are performed, and from best_test_perf, which is a runtime slot for storing the best observed metric; test_index is purely a deterministic data-splitting configuration used by the data-to-model pipeline and the validate routine.
# file path: src/train.py
fea_num = 5fea_num is the small, top-level configuration that fixes how many indicator channels each asset carries into the data-to-model pipeline. Together with stock_num and lookback_length already discussed, fea_num determines the per-example input dimensionality that get_batch produces and that MixerBlock construction and the forward passes through NoGraphMixer and StockMixer will expect: it tells the channel/indicator mixer how many feature dimensions to project and fuse for each stock at each timestep. Conceptually it is the same kind of constant as learning_rate, epochs, and steps in that it’s declared at the top of the training script, but unlike those training hyperparameters fea_num is a structural parameter describing input shape and therefore directly shapes tensor dimensions and the sizes of the dense projections inside the mixer primitives.
# file path: src/train.py
market_num = 20The assignment sets market_num to a fixed integer (20) that the training orchestration uses as the numeric market identifier or count when assembling relation-aware inputs and market-specific parameters. In the data-to-model pipeline it plays a different role than market_name: market_name is the human-readable label used to construct dataset_path so get_batch and validate open the right files, whereas market_num is the numeric configuration value that downstream components use to index or size market-level relation structures, embeddings, or relation-source lookups before the tensors are handed to MixerBlock, NoGraphMixer, and StockMixer. Conceptually it is the same kind of scalar configuration as fea_num and stock_num — fea_num fixes the number of feature channels and stock_num fixes the universe size — but here market_num fixes the market-related dimension or identifier that relation-aware preprocessing and validation routines rely on when preparing batches and building relation matrices.
# file path: src/train.py
steps = 1steps is a small, top-level training hyperparameter that controls how many forward/backward passes the training orchestrator will group together before performing an optimizer update. In the training loop that pulls examples from get_batch and runs them through MixerBlock, NoGraphMixer, and StockMixer, steps determines whether the optimizer updates model parameters after every batch (the current value of one means an immediate update) or waits to accumulate gradients over multiple microbatches before stepping. Like epochs, learning_rate, and alpha, steps is a scalar configuration used by train.py to shape the optimization schedule rather than to change model architecture; it therefore affects the effective batch-size and stability of updates produced from the dataset slices defined by data_path, market_name, relation_source, stock_num, and lookback_length, but it does not alter the forward-pass logic used during validate.
# file path: src/train.py
learning_rate = 0.001learning_rate is the scalar hyperparameter that sets the step size the optimizer will use when updating model parameters during training; in the training orchestration it determines how aggressively gradient signals produced by the forward passes through NoGraphMixer and StockMixer (with inputs prepared by get_batch) are converted into parameter updates by the optimizer. Its numeric setting of 0.001 is the learning-rate value the script exposes at top level so the subsequent optimizer construction uses that same value when instantiating torch.optim.Adam over model.parameters(), tying the gradient-descent dynamics of every training step to this single configurable variable. Compared with epochs, which controls how many full passes over the dataset the loop will execute, and alpha, which acts as a separate scaling hyperparameter used for regularization or loss weighting, learning_rate specifically governs update magnitude per optimizer step and therefore directly affects convergence speed and stability across the training/validation cycles orchestrated by the script.
# file path: src/train.py
alpha = 0.1alpha is a small scalar hyperparameter (set to one tenth) that the training orchestration exposes as a global configuration for weighing a secondary quantity during training and validation. In the StockMixer-master_cleaned_cleaned pipeline it plays the same role as the nearby top-level assignments like learning_rate, epochs, and steps — it’s a simple tunable constant the training loop reads — but unlike epochs and steps which are integer loop controls or learning_rate which controls optimizer step size, alpha is explicitly a fractional mixing/weighting coefficient. Practically, the training and validation routines (the code that prepares batches with get_batch, runs forward passes through MixerBlock/NoGraphMixer/StockMixer, and computes losses in the training loop and validate) will use alpha to scale or interpolate some secondary term (for example a regularization term, auxiliary loss, or a representation blending factor) so that that term contributes one tenth relative to the primary signal unless the value is tuned otherwise.
# file path: src/train.py
scale_factor = 3scale_factor is a top-level architectural hyperparameter that determines how much the model expands its internal projection widths relative to the raw input dimensionality. In the training orchestration it doesn’t change how get_batch slices data or which market folder is used (those are governed by data_path and market_name), nor does it change the universe size or temporal window set by stock_num and lookback_length, but it is consulted when the MixerBlock, NoGraphMixer, and StockMixer are constructed so their dense projection matrices and hidden-layer widths are sized appropriately. Conceptually it multiplies the base feature-derived dimension (for example the per-stock feature count set by fea_num) to produce the hidden dimension used inside the channel/temporal/stock mixing layers, thereby controlling representational capacity and parameter count. Like learning_rate and epochs, it is a global configuration value declared up front, but unlike those optimizer/training-run settings it directly affects model shape rather than training dynamics or schedule. During the forward pass the projections and intermediate activations produced by NoGraphMixer.forward and subsequent StockMixer stages will follow sizes influenced by this multiplier, so it propagates into the model’s weight shapes and the computational footprint observed in both training and validate.
# file path: src/train.py
dataset_path = ‘../dataset/’ + market_nameThe dataset_path variable constructs the concrete filesystem location the training orchestration will read from by combining the project’s base dataset directory with the market_name identifier so get_batch and validate load the market-specific files the model expects. In the data-to-model pipeline this ensures that NoGraphMixer, StockMixer and the MixerBlock construction receive inputs from the correct market folder (the same market_name that was set to NASDAQ), rather than from the generic dataset root defined by data_path. Unlike market_num, which is a numeric configuration describing how many markets or partitions exist, dataset_path is about where on disk to find the actual examples; it also works together with stock_num and lookback_length by pointing to data that must be formatted to the expected number of asset channels and temporal window length so the batching and forward passes produce tensors matching the mixers’ expected shapes.
# file path: src/train.py
if market_name == “SP500”:
data = np.load(’../dataset/SP500/SP500.npy’)
data = data[:, 915:, :]
price_data = data[:, :, -1]
mask_data = np.ones((data.shape[0], data.shape[1]))
eod_data = data
gt_data = np.zeros((data.shape[0], data.shape[1]))
for ticket in range(0, data.shape[0]):
for row in range(1, data.shape[1]):
gt_data[ticket][row] = (data[ticket][row][-1] - data[ticket][row - steps][-1]) / \
data[ticket][row - steps][-1]
else:
with open(os.path.join(dataset_path, “eod_data.pkl”), “rb”) as f:
eod_data = pickle.load(f)
with open(os.path.join(dataset_path, “mask_data.pkl”), “rb”) as f:
mask_data = pickle.load(f)
with open(os.path.join(dataset_path, “gt_data.pkl”), “rb”) as f:
gt_data = pickle.load(f)
with open(os.path.join(dataset_path, “price_data.pkl”), “rb”) as f:
price_data = pickle.load(f)When market_name equals the SP500 case, the orchestrator loads a pre-aggregated multi-dimensional numpy array that already contains per-ticker end-of-day features and then trims the time axis to a later window by selecting columns starting at a fixed time index
# file path: src/train.py
trade_dates = mask_data.shape[1]trade_dates is obtained by reading the time-axis length from mask_data so the training orchestration knows how many discrete trading days are present in the loaded market slice. mask_data is the dataset-provided mask that get_batch and validate load from the dataset_path to indicate which asset-date entries are valid, and pulling its second dimension gives the temporal extent that the rest of the pipeline must honor. The value is used downstream to size and slice input tensors that feed NoGraphMixer and StockMixer, to drive loops in validation and batching, and to configure temporal-mixing operations so they align with the actual number of dates instead of a hardcoded constant. Unlike the static hyperparameters such as market_num, data_path, or fea_num, trade_dates is a runtime-derived dimension that ensures the model’s temporal projections and loss computations match the dataset’s real time length.
# file path: src/train.py
model = StockMixer(
stocks=stock_num,
time_steps=lookback_length,
channels=fea_num,
market=market_num,
scale=scale_factor
).to(device)The line constructs a StockMixer instance configured to the dataset dimensions and training hyperparameters—passing stock_num as the number of assets, lookback_length as the temporal window, fea_num as the per-asset feature channels, market_num as the market identifier, and scale_factor to control internal projection sizing—and immediately places that model on the selected compute device. StockMixer itself assembles the project’s three mixing stages: a MultTime2dMixer that performs channel and temporal fusion (including a separate small scale mixer used as an auxiliary temporal summary), a 1D convolutional temporal compressor, linear heads that collapse channel and time axes into per-stock signals, and a NoGraphMixer that implements cross-asset mixing; together these pieces implement the indicator, temporal, and stock mixing primitives at the heart of the forecasting engine. In runtime data flow, batches produced by get_batch are fed into StockMixer’s forward path where inputs are temporally compressed by the convolution, combined and mixed by MultTime2dMixer (concatenating original, mixed, and scaled summaries), reduced along channels by the channel projection, passed through the stock mixer to model cross-asset interactions, and then run through time projections whose outputs are summed to produce the final prediction. Moving the instance to device ensures all parameters and buffers are resident on the correct GPU/CPU so the training loop, validate, optimizer steps, and gradient computations operate on that hardware.
# file path: src/train.py
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)The training orchestration instantiates a PyTorch Adam optimizer and gives it the model’s parameter iterator so the optimizer becomes responsible for updating every trainable weight inside model (which includes the mixer submodules like NoGraphMixer and StockMixer). The optimizer is configured to use the learning_rate hyperparameter you saw earlier, so that scalar directly sets the step size Adam uses when converting the gradients produced by the forward/backward passes (with inputs from get_batch) into parameter updates. Adam maintains running estimates of first and second moments for each parameter to adaptively scale those updates, and in the training loop the optimizer will be invoked to apply the accumulated gradients — note that the steps hyperparameter controls how many forward/backward passes are accumulated before the optimizer is stepped. Epochs govern how many times that cycle repeats, alpha is a separate loss-weighting hyperparameter and not part of optimizer configuration, and scale_factor affects the number of parameters Adam will manage because it changes the model’s internal projection widths.
# file path: src/train.py
best_valid_loss = np.infThe variable best_valid_loss is initialized to positive infinity as a numeric sentinel that the training orchestrator in src/train.py uses to track the lowest scalar validation loss seen so far. Because the training loop prepares batches with get_batch, runs forward passes through NoGraphMixer and StockMixer, and computes a scalar loss for validation, each computed finite validation loss is compared against this sentinel so the very first validation measurement becomes the initial baseline and any strictly smaller loss will register as an improvement. That numeric sentinel is used in the control flow inside validate to decide when to record the best-performing snapshot and associated metrics; it complements best_valid_perf and best_test_perf, which are set to None because they are intended to hold richer performance artifacts rather than a raw scalar. The value therefore provides a predictable starting point for the optimizer- and hyperparameter-driven training dynamics (see steps, learning_rate, alpha, scale_factor) and works together with valid_index to manage when and how validation comparisons are made.
# file path: src/train.py
best_valid_perf = Nonebest_valid_perf is initialized to a sentinel value that marks “no validation performance recorded yet” before any calls to validate produce a concrete metric. Within the training orchestration that uses get_batch to prepare inputs and runs forward passes through NoGraphMixer and StockMixer (and then computes losses and calls validate on the held-out split identified by valid_index), validate returns a scalar performance measure that the loop will compare against this stored value to decide whether to update the saved best model state or log an improvement. Setting best_valid_perf to None signals that there is no baseline to compare to on the first validation pass; this mirrors best_test_perf which is initialized the same way, and contrasts with best_valid_loss which is initialized to a numeric infinity because loss is a lower-is-better quantity and therefore needs an upper numeric bound as the starting baseline.
# file path: src/train.py
best_test_perf = NoneThis line initializes a sentinel named best_test_perf to indicate that no test-set performance has yet been observed during the training/validation lifecycle. As training progresses, batches prepared by get_batch and fed through the model primitives such as NoGraphMixer and StockMixer will produce validation and test metrics via validate; those metrics are compared against best_test_perf to decide whether the current checkpoint represents an improvement and should replace the stored best result. It mirrors best_valid_perf, which tracks the same idea for the validation set, and contrasts with best_valid_loss that starts at numpy infinity because loss is a minimization target; starting best_test_perf as None signals absence of a baseline (and therefore requires a presence check before numeric comparison) rather than initializing to an extreme numeric value. This sentinel therefore participates in the pipeline that turns gradient updates (governed by steps and learning_rate) and the model’s outputs (influenced by alpha and scale_factor and fed from dataset_path) into an ongoing record of the best test performance seen so far.
# file path: src/train.py
batch_offsets = np.arange(start=0, stop=valid_index, dtype=int)batch_offsets constructs a contiguous NumPy array of integer time-start indices running from zero up to but not including valid_index. In the training orchestration this supplies an explicit set of temporal offsets that the pipeline can iterate, shuffle, or slice deterministically when preparing inputs for get_batch; get_batch’s own default offset selection draws from the same range, so using batch_offsets makes it straightforward to enumerate every permissible starting position without risking out-of-bounds slices. Because get_batch slices feature, mask, price and ground-truth windows using an offset plus the lookback horizon and the steps hyperparameter, bounding offsets by valid_index ensures those downstream slices remain valid, and specifying an integer dtype produces indices that are directly usable for NumPy/Torch indexing and for forming the deterministic validation or batching loops used by validate.
# file path: src/train.py
def validate(start_index, end_index):
with torch.no_grad():
cur_valid_pred = np.zeros([stock_num, end_index - start_index], dtype=float)
cur_valid_gt = np.zeros([stock_num, end_index - start_index], dtype=float)
cur_valid_mask = np.zeros([stock_num, end_index - start_index], dtype=float)
loss = 0.
reg_loss = 0.
rank_loss = 0.
for cur_offset in range(start_index - lookback_length - steps + 1, end_index - lookback_length - steps + 1):
data_batch, mask_batch, price_batch, gt_batch = map(
lambda x: torch.Tensor(x).to(device),
get_batch(cur_offset)
)
prediction = model(data_batch)
cur_loss, cur_reg_loss, cur_rank_loss, cur_rr = get_loss(prediction, gt_batch, price_batch, mask_batch,
stock_num, alpha)
loss += cur_loss.item()
reg_loss += cur_reg_loss.item()
rank_loss += cur_rank_loss.item()
cur_valid_pred[:, cur_offset - (start_index - lookback_length - steps + 1)] = cur_rr[:, 0].cpu()
cur_valid_gt[:, cur_offset - (start_index - lookback_length - steps + 1)] = gt_batch[:, 0].cpu()
cur_valid_mask[:, cur_offset - (start_index - lookback_length - steps + 1)] = mask_batch[:, 0].cpu()
loss = loss / (end_index - start_index)
reg_loss = reg_loss / (end_index - start_index)
rank_loss = rank_loss / (end_index - start_index)
cur_valid_perf = evaluate(cur_valid_pred, cur_valid_gt, cur_valid_mask)
return loss, reg_loss, rank_loss, cur_valid_perfvalidate runs a gradient-free evaluation sweep over a contiguous range of validation times and turns per-window model outputs into averaged loss numbers and a performance object that the rest of the training loop can consume. It begins by allocating three NumPy matrices to collect per-stock predicted values, ground-truths and masks for each time step between start_index and end_index, then enters a torch.no_grad context so no gradients are recorded. The function iterates over a sequence of offsets chosen so each get_batch call (which you already saw earlier) yields a lookback window plus the prediction horizon aligned to the validation interval; for each offset it converts the get_batch outputs to tensors on the device, runs the StockMixer model to produce predictions, and hands prediction, ground truth, base price and mask into get_loss (which returns a scalar loss, a regression loss, a pairwise rank loss, and a per-stock return-like array). validate accumulates the scalar losses (extracting Python floats), writes the per-stock scalar prediction, ground-truth and mask for the first horizon into the corresponding column of the collection matrices, and continues until all offsets in the requested interval are processed. After the loop it averages the accumulated losses by the number of evaluated windows (using end_index minus start_index), calls evaluate to compute concrete performance metrics from the collected prediction/ground-truth/mask arrays, and finally returns the mean loss, mean reg_loss, mean rank_loss and the evaluate performance dictionary. The routine therefore ties together get_batch, StockMixer, get_loss and evaluate to produce validation numbers consistent with the training orchestration and the hyperparameters you’ve already seen such as steps and alpha.
# file path: src/evaluator.py
import numpy as np
import pandas as pdThe file imports numpy and pandas because evaluate is a pure numerical/analysis routine that works on in-memory arrays produced by the model and dataset loader. numpy provides the core array representation and vectorized numeric operations used to compute the mean-squared error, apply the binary mask, perform arg-sorting for ranking, and compute norms and other linear-algebraic quantities; pandas is used to wrap columns of those arrays into DataFrame objects so the evaluator can compute per-column correlations (the information coefficient) and perform column-oriented ranking/selection operations more conveniently. Compared with other modules that also pull in os, tqdm, random, torch, dataset loaders or pickle to handle filesystem access, progress reporting, randomness, model execution, and I/O, the evaluate imports are deliberately minimal because validate orchestrates the forward passes and data I/O elsewhere; evaluate only needs tools for numeric aggregation and simple column-wise statistics. This fits into the overall StockMixer-master_cleaned_cleaned architecture where the mixers and get_batch produce numeric prediction and ground-truth arrays (and masks), and evaluate consumes those arrays to produce aggregated loss and ranking-based performance metrics; earlier top-level hyperparameters like steps, learning_rate, alpha, scale_factor and dataset_path that we discussed are configured and used by the training/validation orchestrator but are not required inside evaluate, which focuses solely on numeric metric computation via numpy and pandas.
# file path: src/evaluator.py
def evaluate(prediction, ground_truth, mask, report=False):
assert ground_truth.shape == prediction.shape, ‘shape mis-match’
performance = {}
performance[’mse’] = np.linalg.norm((prediction - ground_truth) * mask) ** 2 / np.sum(mask)
df_pred = pd.DataFrame(prediction * mask)
df_gt = pd.DataFrame(ground_truth * mask)
ic = []
mrr_top = 0.0
all_miss_days_top = 0
bt_long = 1.0
bt_long5 = 1.0
bt_long10 = 1.0
irr = 0.0
sharpe_li5 = []
prec_10 = []
for i in range(prediction.shape[1]):
ic.append(df_pred[i].corr(df_gt[i]))
rank_gt = np.argsort(ground_truth[:, i])
gt_top1 = set()
gt_top5 = set()
gt_top10 = set()
for j in range(1, prediction.shape[0] + 1):
cur_rank = rank_gt[-1 * j]
if mask[cur_rank][i] < 0.5:
continue
if len(gt_top1) < 1:
gt_top1.add(cur_rank)
if len(gt_top5) < 5:
gt_top5.add(cur_rank)
if len(gt_top10) < 10:
gt_top10.add(cur_rank)
rank_pre = np.argsort(prediction[:, i])
pre_top1 = set()
pre_top5 = set()
pre_top10 = set()
for j in range(1, prediction.shape[0] + 1):
cur_rank = rank_pre[-1 * j]
if mask[cur_rank][i] < 0.5:
continue
if len(pre_top1) < 1:
pre_top1.add(cur_rank)
if len(pre_top5) < 5:
pre_top5.add(cur_rank)
if len(pre_top10) < 10:
pre_top10.add(cur_rank)
top1_pos_in_gt = 0
for j in range(1, prediction.shape[0] + 1):
cur_rank = rank_gt[-1 * j]
if mask[cur_rank][i] < 0.5:
continue
else:
top1_pos_in_gt += 1
if cur_rank in pre_top1:
break
if top1_pos_in_gt == 0:
all_miss_days_top += 1
else:
mrr_top += 1.0 / top1_pos_in_gt
real_ret_rat_top = ground_truth[list(pre_top1)[0]][i]
bt_long += real_ret_rat_top
gt_irr = 0.0
for gt in gt_top10:
gt_irr += ground_truth[gt][i]
real_ret_rat_top5 = 0
for pre in pre_top5:
real_ret_rat_top5 += ground_truth[pre][i]
irr += real_ret_rat_top5
real_ret_rat_top5 /= 5
bt_long5 += real_ret_rat_top5
prec = 0.0
real_ret_rat_top10 = 0
for pre in pre_top10:
real_ret_rat_top10 += ground_truth[pre][i]
prec += (ground_truth[pre][i] >= 0)
prec_10.append(prec / 10)
real_ret_rat_top10 /= 10
bt_long10 += real_ret_rat_top10
sharpe_li5.append(real_ret_rat_top5)
performance[’IC’] = np.mean(ic)
performance[’RIC’] = np.mean(ic) / np.std(ic)
sharpe_li5 = np.array(sharpe_li5)
performance[’sharpe5’] = (np.mean(sharpe_li5)/np.std(sharpe_li5))*15.87
performance[’prec_10’] = np.mean(prec_10)
return performanceevaluate takes the in-memory arrays that validate assembled for a contiguous validation sweep — prediction, ground_truth and mask — and turns those per-window, per-stock numbers into a small performance dictionary that the training loop can consume. It first enforces that prediction and ground_truth have the same shape, then computes a global mean-squared-error by measuring the squared L2 difference between prediction and ground_truth after applying the mask and normalizing by the total valid count. To produce ranking and directional metrics it converts the masked prediction and ground truth matrices into pandas DataFrames so column-wise correlations are easy to compute. The core work happens in a loop over the second axis (the validation windows): for each window it computes the information coefficient as the column correlation between predicted and actual returns, then builds top-1, top-5 and top-10 sets for both ground truth and prediction by ranking across stocks while skipping entries excluded by the mask threshold. Using those sets it accumulates a reciprocal-rank style metric (MRR) that records how deep the top ground-truth stock appears in the predicted top-1, counts days where no valid top-1 exists, and sums realized returns for the predicted top-1, top-5 and top-10 (using ground_truth values at the predicted indices) so the code can report simple backtest aggregates. It also collects per-window top-5 returns into sharpe_li5 and computes precision@10 as the fraction of predicted top-10 with non-negative realized returns. After the loop it reduces the collected lists into final aggregates: mean IC, a risk-adjusted RIC (mean IC divided by its standard deviation), a scaled sharpe5 computed from the per-window top-5 returns, and mean precision@10, and returns those values in the performance dictionary back to validate for use by the rest of the training/validation lifecycle.
# file path: src/train.py
def get_batch(offset=None):
if offset is None:
offset = random.randrange(0, valid_index)
seq_len = lookback_length
mask_batch = mask_data[:, offset: offset + seq_len + steps]
mask_batch = np.min(mask_batch, axis=1)
return (
eod_data[:, offset:offset + seq_len, :],
np.expand_dims(mask_batch, axis=1),
np.expand_dims(price_data[:, offset + seq_len - 1], axis=1),
np.expand_dims(gt_data[:, offset + seq_len + steps - 1], axis=1))get_batch prepares a single training/validation window for the pipeline by slicing the global time-series arrays into the pieces the model and loss/evaluation routines expect. If no offset is provided it picks a random start index between zero and valid_index so training can sample varied windows; when validate calls get_batch it supplies a concrete cur_offset to deterministically walk the validation period. It sets the input sequence length from lookback_length and then extracts three aligned slices: the multi-channel per-stock input sequence from eod_data covering the lookback window, a scalar base price per stock taken from price_data at the last timestep of that input window, and the ground-truth target per stock taken from gt_data at the forecast horizon after the lookback. For validity masking it extracts mask_data across the whole span that covers both the input window and the forecast horizon and then reduces that per-stock time vector with a minimum operation so any missing timestep in the combined window produces a zero mask for that stock; the mask is expanded to a column vector to match the shapes expected downstream. All returned arrays are shaped so validate can immediately convert them to torch tensors, feed the input slice into StockMixer, and pass the base_price, ground-truth and mask into get_loss and evaluate; the design ensures the base price aligns with the model’s last observed input and the ground-truth aligns with the intended forecast horizon.
# file path: src/train.py
for epoch in range(epochs):
print(”epoch{}##########################################################”.format(epoch + 1))
np.random.shuffle(batch_offsets)
tra_loss = 0.0
tra_reg_loss = 0.0
tra_rank_loss = 0.0
for j in range(valid_index - lookback_length - steps + 1):
data_batch, mask_batch, price_batch, gt_batch = map(
lambda x: torch.Tensor(x).to(device),
get_batch(batch_offsets[j])
)
optimizer.zero_grad()
prediction = model(data_batch)
cur_loss, cur_reg_loss, cur_rank_loss, _ = get_loss(prediction, gt_batch, price_batch, mask_batch,
stock_num, alpha)
cur_loss = cur_loss
cur_loss.backward()
optimizer.step()The epoch loop iterates over the configured number of epochs and prints a progress marker for each pass. At the start of each epoch it randomizes batch_offsets to present time-window start indices in a different order, which prevents the model from always seeing minibatches in the same temporal sequence. tra_loss, tra_reg_loss, and tra_rank_loss are initialized to accumulate per-epoch totals for the primary training loss, the regularization component, and the ranking component respectively. The inner loop runs over the range of valid start indices derived from valid_index, lookback_length and steps so every drawn window has the required lookback history and prediction horizon. For each start index get_batch returns four arrays (data_batch, mask_batch, price_batch, gt_batch); those arrays are converted to torch.Tensor and moved to device so the subsequent computations execute on the chosen device. The optimizer gradients are cleared, the model produces a prediction from data_batch, and get_loss consumes prediction together with gt_batch, price_batch, mask_batch, stock_num and alpha to produce cur_loss, cur_reg_loss, cur_rank_loss and an auxiliary value. The code treats cur_loss as the scalar objective, backpropagates it to accumulate gradients, and then calls optimizer.step to update model parameters. This implements the standard per-batch training cycle driven by the hyperparameters declared elsewhere (epochs at L20, lookback_length at L19 that constrains windowing, and learning_rate at L26 that governs optimizer update magnitude) and produces the batch-level signals that will later be evaluated by validate and used to update best_valid_perf / best_test_perf.
# file path: src/train.py
tra_loss += cur_loss.item()
tra_reg_loss += cur_reg_loss.item()
tra_rank_loss += cur_rank_loss.item()
tra_loss = tra_loss / (valid_index - lookback_length - steps + 1)
tra_reg_loss = tra_reg_loss / (valid_index - lookback_length - steps + 1)
tra_rank_loss = tra_rank_loss / (valid_index - lookback_length - steps + 1)
print(’Train : loss:{:.2e} = {:.2e} + alpha*{:.2e}’.format(tra_loss, tra_reg_loss, tra_rank_loss))After the per-offset training loop has accumulated the three scalar components produced by get_loss into tra_loss, tra_reg_loss, and tra_rank_loss using tensor-to-scalar extraction, these three accumulators are converted into per-window averages by dividing each by the count of time-start offsets that were processed; that count is computed the same way the validation routine determines its window count, using valid_index together with lookback_length and steps to derive how many training windows were seen. The final step emits a one-line summary that prints the averaged overall training loss and its two constituent parts so you can quickly see the total training objective decomposed into the regularization term and the ranking term (the print labels show the relationship between the total loss and the reg/rank components, with rank intended to be scaled by alpha elsewhere in the loop). This mirrors validate’s pattern of accumulating scalar losses across time windows and then normalizing by the number of windows before reporting a summarized metric.
# file path: src/train.py
val_loss, val_reg_loss, val_rank_loss, val_perf = validate(valid_index, test_index)
print(’Valid : loss:{:.2e} = {:.2e} + alpha*{:.2e}’.format(val_loss, val_reg_loss, val_rank_loss))The code invokes validate with the current validation window bounds and unpacks its four return values into val_loss, val_reg_loss, val_rank_loss, and val_perf. Remember the validate function we covered earlier: it runs a gradient-free sweep over the validation time range and returns averaged scalar losses plus a performance object produced by evaluate. Here val_loss is the overall averaged validation loss, val_reg_loss is the averaged regularization (or reconstruction-like) component, val_rank_loss is the averaged ranking component, and val_perf is the aggregate performance summary used elsewhere in the training loop. Immediately after calling validate, the script prints a one-line diagnostic that shows the total validation loss in compact scientific notation and displays how that total decomposes into the regularization term plus the ranking term (the latter intended to be scaled by the training alpha), so the operator can see the magnitude of each contribution at a glance.
# file path: src/train.py
test_loss, test_reg_loss, test_rank_loss, test_perf = validate(test_index, trade_dates)
print(’Test: loss:{:.2e} = {:.2e} + alpha*{:.2e}’.format(test_loss, test_reg_loss, test_rank_loss))Here the training script invokes validate with test_index and trade_dates to run a gradient-free evaluation sweep over the test time window; validate (as explained earlier) pulls batches via get_batch, runs them through model, accumulates the averaged total loss plus its two components (regularization and ranking), and returns those three scalars along with a test_perf object summarizing downstream metrics. Immediately after validate returns, the script prints a compact diagnostic line that shows the aggregated test loss in scientific notation and exposes how that loss decomposes into the regularization term plus the ranking term (shown with the alpha multiplier notation) so you can see each component’s contribution to the final objective. This mirrors the same validate usage pattern used for the validation partition but applied to the test partition defined by test_index and trade_dates, producing the final numeric summary that the rest of the training/monitoring logic (e.g., the best_valid_perf / best_test_perf tracking) can interpret.
# file path: src/train.py
if val_loss < best_valid_loss:
best_valid_loss = val_loss
best_valid_perf = val_perf
best_test_perf = test_perfWhen validate returns val_loss, val_perf, and test_perf for the current evaluation window, the training loop compares val_loss against best_valid_loss and, when the new validation loss is smaller, replaces the stored best_valid_loss with the new val_loss and records the associated performance objects by assigning best_valid_perf to val_perf and best_test_perf to test_perf. This implements the straightforward model-selection checkpointing pattern: keep the best-seen validation loss as the selection criterion and snapshot the corresponding validation and test performance so downstream reporting and any selection logic use the metrics from the model that achieved the best validation outcome. This update step complements the initial sentinels set earlier (best_valid_loss started at the infinity sentinel and best_valid_perf and best_test_perf started as empty sentinels), so the first improving validation pass will populate those placeholders and subsequent passes only replace them on further improvement.
# file path: src/train.py
print(’Valid performance:\n’, ‘mse:{:.2e}, IC:{:.2e}, RIC:{:.2e}, prec@10:{:.2e}, SR:{:.2e}’.format(val_perf[’mse’], val_perf[’IC’],
val_perf[’RIC’], val_perf[’prec_10’], val_perf[’sharpe5’]))
print(’Test performance:\n’, ‘mse:{:.2e}, IC:{:.2e}, RIC:{:.2e}, prec@10:{:.2e}, SR:{:.2e}’.format(test_perf[’mse’], test_perf[’IC’],
test_perf[’RIC’], test_perf[’prec_10’], test_perf[’sharpe5’]), ‘\n\n’)After validate returns the two summary dictionaries val_perf and test_perf, these lines print a compact, human-readable report of the key metrics the training loop and evaluate produce so an engineer can monitor progress on the console. They pull the same metric fields that evaluate constructs — mean squared error, the information coefficient (IC), the rank-IC variant (RIC), the top-10 precision, and the five-period Sharpe proxy stored under sharpe5 — and render each as a short numeric string in exponential notation with two decimal places so large and small values are readable at a glance. The first print labels and shows the validation metrics and the second prints the test metrics, with a blank-line spacer after the test output for readability; this gives an immediate side-by-side status update that the rest of the training loop (which tracks best_valid_perf and best_test_perf) can be interpreted against. In short, evaluate computes the numbers and validate aggregates them over windows, and these lines simply format and emit those aggregated performance summaries to the console so operators can watch model improvement over epochs.
# file path: src/load_data.py
import numpy as np
import os
from tqdm import tqdmFor load_data, these three imports provide the lightweight tools needed to turn raw files into the numeric arrays the forecasting engine consumes. Numpy is the numerical backbone used to allocate and manipulate the feature, label and adjacency arrays that will be normalized and packaged for the model; this connects directly to validate and other evaluation code that operate on in-memory NumPy arrays produced by the loader. Os supplies the filesystem utilities used to locate, enumerate and sanity-check end‑of‑day time series and relation files so the loader can build dataset shards and adjacency structures from whatever files live on disk. Tqdm is used to wrap long file- or row-processing loops so dataset assembly reports progress while parsing many assets or long histories. Compared with the similar import lists in other modules, which pull in heavier dependencies like torch, pandas or pickle because they perform model computation or richer DataFrame manipulation, these imports are deliberately minimal because load_data’s role is file I/O and numeric array construction rather than model execution or advanced tabular transforms.
# file path: src/load_data.py
def load_EOD_data(data_path, market_name, tickers, steps=1):
eod_data = []
masks = []
ground_truth = []
base_price = []
for index, ticker in enumerate(tqdm(tickers)):
single_EOD = np.genfromtxt(
os.path.join(data_path, market_name + ‘_’ + ticker + ‘_1.csv’),
dtype=np.float32, delimiter=’,’, skip_header=False
)
if market_name == ‘NASDAQ’:
single_EOD = single_EOD[:-1, :]
if index == 0:
print(’single EOD data shape:’, single_EOD.shape)
eod_data = np.zeros([len(tickers), single_EOD.shape[0],
single_EOD.shape[1] - 1], dtype=np.float32)
masks = np.ones([len(tickers), single_EOD.shape[0]],
dtype=np.float32)
ground_truth = np.zeros([len(tickers), single_EOD.shape[0]],
dtype=np.float32)
base_price = np.zeros([len(tickers), single_EOD.shape[0]],
dtype=np.float32)
for row in range(single_EOD.shape[0]):
if abs(single_EOD[row][-1] + 1234) < 1e-8:
masks[index][row] = 0.0
elif row > steps - 1 and abs(single_EOD[row - steps][-1] + 1234) \
> 1e-8:
ground_truth[index][row] = \
(single_EOD[row][-1] - single_EOD[row - steps][-1]) / \
single_EOD[row - steps][-1]
for col in range(single_EOD.shape[1]):
if abs(single_EOD[row][col] + 1234) < 1e-8:
single_EOD[row][col] = 1.1
eod_data[index, :, :] = single_EOD[:, 1:]
base_price[index, :] = single_EOD[:, -1]
return eod_data, masks, ground_truth, base_priceload_EOD_data is the CSV ingest and preprocessing routine that turns per‑ticker end‑of‑day files into the four core arrays the forecasting engine expects: a features tensor, a per‑time validity mask, a target (ground truth) return series computed over the requested lookback horizon, and a base price series. For each ticker it reads the ticker’s CSV into a NumPy array, trims a final row for the NASDAQ case, and on the first ticker uses that file’s shape to allocate eod_data (shape: number of tickers × time × feature_dims_minus_one), masks (number of tickers × time), ground_truth (number of tickers × time) and base_price (number of tickers × time) with float32 storage; it also prints the single file shape for debugging. As it walks each row it treats the sentinel missing value of −1234 in the last column as an invalid time step and flips the corresponding mask entry to zero; when a valid price exists at the current row and at the row steps back it computes a relative return over that horizon and stores it into ground_truth, otherwise that target remains zero. Any individual cell equal to the −1234 sentinel is replaced with a small numeric fill of 1.1 to avoid propagating NaNs in the feature matrix. After per‑row processing it slices off the first CSV column (presumably non‑feature metadata) into eod_data and stores the last column into base_price so the model receives features, masks, labels, and a reference price series. Compared with build_SFM_data, which only extracts a single price series and fills missing values by backfilling or short rolling averages, load_EOD_data constructs a multi‑feature tensor, explicit validity masks, and step‑based return targets suitable for the mixer blocks and the evaluation routines (such as validate) to consume.
# file path: src/load_data.py
def load_graph_relation_data(relation_file, lap=False):
relation_encoding = np.load(relation_file)
print(’relation encoding shape:’, relation_encoding.shape)
rel_shape = [relation_encoding.shape[0], relation_encoding.shape[1]]
mask_flags = np.equal(np.zeros(rel_shape, dtype=int),
np.sum(relation_encoding, axis=2))
ajacent = np.where(mask_flags, np.zeros(rel_shape, dtype=float),
np.ones(rel_shape, dtype=float))
degree = np.sum(ajacent, axis=0)
for i in range(len(degree)):
degree[i] = 1.0 / degree[i]
np.sqrt(degree, degree)
deg_neg_half_power = np.diag(degree)
if lap:
return np.identity(ajacent.shape[0], dtype=float) - np.dot(
np.dot(deg_neg_half_power, ajacent), deg_neg_half_power)
else:
return np.dot(np.dot(deg_neg_half_power, ajacent), deg_neg_half_power)load_graph_relation_data reads a saved relation tensor from disk and turns it into the graph matrix the mixer stack expects for cross-asset aggregation. It first loads the relation_encoding array and prints its shape for logging. It then reduces that 3D encoding to a 2D connectivity map by summing the relation channels and marking entries that are all-zero as absent; present relations are converted into a binary adjacency matrix. From that adjacency matrix it computes a per-node degree vector by summing across the adjacency axis, then replaces each degree entry with its reciprocal and takes the square root to produce the D^{-1/2} factors. Those factors are placed on a diagonal matrix and used to form the symmetric normalization D^{-1/2} A D^{-1/2}. Finally, the function returns either the normalized adjacency or the normalized Laplacian depending on the lap flag: when lap is true it returns the identity minus the normalized adjacency, otherwise it returns the normalized adjacency itself. Conceptually this complements load_EOD_data: load_EOD_data prepares per-ticker time series and masks, while load_graph_relation_data prepares the structural graph input used by the stock-mixing stage; it also differs from load_relation_data by producing a normalized matrix for graph propagation rather than returning the raw relation_encoding and an attention mask. The implementation follows a simple branch to select Laplacian versus adjacency and a loop that converts degree entries into their reciprocal square-root form before forming the diagonal normalizer.
# file path: src/load_data.py
def load_relation_data(relation_file):
relation_encoding = np.load(relation_file)
rel_shape = [relation_encoding.shape[0], relation_encoding.shape[1]]
mask_flags = np.equal(np.zeros(rel_shape, dtype=int),
np.sum(relation_encoding, axis=2))
mask = np.where(mask_flags, np.ones(rel_shape) * -1e9, np.zeros(rel_shape))
return relation_encoding, maskload_relation_data reads a precomputed relation tensor from the supplied relation_file into relation_encoding and then builds a companion pairwise mask that the forecaster can use when combining information across assets. It infers the pairwise grid size from the first two dimensions of relation_encoding (the per-ticker by per-ticker footprint), then identifies which asset pairs have no relation by summing the relation channels and checking where that sum is zero; those positions become mask_flags. Using mask_flags it produces mask as an additive logit mask that assigns a large negative constant for absent relations and zero for present relations so that, when applied to attention or softmax-style weighting in the mixing stages, nonexistent edges get effectively zero weight. The function returns the original multi-channel relation_encoding and the N-by-N additive mask. This is similar to load_graph_relation_data in that both load the same .npy relation tensor and detect empty pair entries by summing across the channel axis, but differs in intent and output: load_graph_relation_data constructs a normalized adjacency or Laplacian matrix for graph-based propagation, whereas load_relation_data preserves the full relation_encoding and supplies an additive mask suitable for suppressing absent relations during the model’s mixing/attention operations.
# file path: src/load_data.py
def build_SFM_data(data_path, market_name, tickers):
eod_data = []
for index, ticker in enumerate(tickers):
single_EOD = np.genfromtxt(
os.path.join(data_path, market_name + ‘_’ + ticker + ‘_1.csv’),
dtype=np.float32, delimiter=’,’, skip_header=False
)
if index == 0:
print(’single EOD data shape:’, single_EOD.shape)
eod_data = np.zeros([len(tickers), single_EOD.shape[0]],
dtype=np.float32)
for row in range(single_EOD.shape[0]):
if abs(single_EOD[row][-1] + 1234) < 1e-8:
if row < 3:
for i in range(row + 1, single_EOD.shape[0]):
if abs(single_EOD[i][-1] + 1234) > 1e-8:
eod_data[index][row] = single_EOD[i][-1]
break
else:
eod_data[index][row] = np.sum(
eod_data[index, row - 3:row]) / 3
else:
eod_data[index][row] = single_EOD[row][-1]
np.save(market_name + ‘_sfm_data’, eod_data)build_SFM_data constructs and persists a compact, per‑ticker end‑of‑day matrix that the SFM mixers consume by scanning each ticker’s CSV, extracting the final price column, and assembling those scalars into a two‑dimensional array shaped by number of tickers by number of time steps. For the first ticker it uses the CSV shape to allocate the output array and prints that shape for a quick sanity check; then for every ticker it walks each row and checks for the dataset’s missing‑value sentinel (the negative constant used across the codebase). When a missing sentinel is found for an early row it searches forward in the same file to pull the next available valid price, while for later rows it imputes a short three‑period moving average from the three previously filled entries; when a price is valid it is copied directly into the output matrix. After processing all tickers the function saves the dense numpy array to disk under a market‑specific SFM filename so downstream dataset builders and the model can load a gap‑free per‑ticker price series. This routine is a simplified, single‑channel counterpart to load_EOD_data: load_EOD_data produces multi‑feature tensors plus masks, ground truth returns and base prices for training, whereas build_SFM_data produces a compact price matrix with inlined imputation intended for the SFM preprocessing pipeline.
Use the link below to download source code
