

Emotion-Driven Finance: Enhancing Sentiment Analysis and Market Prediction through Investor Emotions
Leveraging Advanced NLP and Machine Learning Techniques with the StockEmotions Dataset for Superior Financial Insights

If you prefer listening over reading, you can now listen to the article. You can also download the source code using the link provided at the end.
Understanding investor emotions has emerged as a pivotal factor in financial sentiment analysis and stock market prediction, offering deeper insights into market dynamics beyond traditional numerical data. This article delves into the integration of nuanced investor emotions into financial analytics, underscoring their significant role in shaping market behavior and investment decisions. To facilitate this, we developed a comprehensive dataset, meticulously curated from StockTwits, a prominent financial social media platform. This dataset encompasses over 10,000 English comments, each annotated with both binary financial sentiments — bullish and bearish — and twelve fine-grained emotion categories inspired by behavioral finance and psychological theories. Our annotation pipeline employs a sophisticated multi-step process that synergizes human expertise with advanced pre-trained language models, ensuring high-quality and contextually accurate emotional labels.
Leveraging this dataset, we implemented a series of advanced machine learning models to perform financial sentiment classification and multivariate time series forecasting. Our experiments reveal that emotion-enhanced models, particularly those utilizing DistilBERT, significantly outperform traditional baselines in sentiment classification, achieving an average F1-score of 0.81. Furthermore, in predicting the S&P 500 index, models incorporating emotional features alongside textual and numerical data demonstrated superior accuracy, evidenced by a notable reduction in Mean Squared Error (MSE). These findings highlight the profound impact of investor emotions on market predictions, suggesting that incorporating emotional intelligence into financial models can enhance forecasting accuracy and provide a more holistic understanding of market trends.
The implications of this research extend to the realms of behavioral finance and investment strategy development. By acknowledging and quantifying investor emotions, financial analysts and investors can better anticipate market movements, tailor investment strategies, and mitigate risks associated with emotional volatility. This integration of emotional data fosters a more informed and resilient approach to financial decision-making, paving the way for innovative advancements in financial technology and market analysis.
Introduction
In recent years, the convergence of Natural Language Processing (NLP) and finance has revolutionized the way market dynamics are analyzed and understood. NLP techniques enable the extraction and interpretation of vast amounts of textual data from diverse sources such as social media platforms, financial news, and analyst reports. This integration facilitates the identification of patterns and sentiments that influence investor behavior and, consequently, stock market movements. As financial markets become increasingly interconnected and influenced by real-time information dissemination, the ability to accurately gauge investor sentiment and emotions has become paramount for both academics and industry practitioners aiming to predict market trends and make informed investment decisions.
Understanding investor sentiment and emotions is critical in deciphering the complexities of stock market dynamics. Emotions such as optimism, fear, and anxiety can significantly impact trading volumes and price volatility, often leading to market anomalies that are not explained solely by fundamental financial indicators. Behavioral finance, a field that blends psychological theories with economic behavior, underscores the profound effect of investor emotions on market outcomes. By analyzing the sentiments expressed by investors, it is possible to gain insights into market sentiment shifts, identify potential investment opportunities, and mitigate risks associated with emotional-driven market fluctuations.
Despite the recognized importance of investor emotions, existing financial sentiment datasets exhibit several limitations that hinder the advancement of research and practical applications in this domain. Many of these datasets are characterized by their small size, which restricts the ability to train robust machine learning models capable of capturing the nuanced emotional states of investors. Additionally, the lack of emotional granularity in these datasets often reduces sentiment analysis to binary classifications — such as bullish or bearish — thereby oversimplifying the rich spectrum of emotions that influence investor behavior. This deficiency not only limits the depth of sentiment analysis but also impedes the development of sophisticated models that can accurately reflect the multifaceted nature of investor emotions.
Addressing these challenges necessitates a more nuanced approach to capturing investor emotions, one that goes beyond basic sentiment classification to encompass a wide range of emotional states. There is a clear need for comprehensive datasets that provide fine-grained annotations of investor emotions, enabling more detailed and accurate sentiment analysis. Such datasets would empower researchers to explore the intricate relationships between specific emotions and market movements, thereby enhancing the predictive power of financial models.
In response to this need, we present the development of a novel dataset designed to capture fine-grained investor emotions with unprecedented detail. This dataset is meticulously curated from StockTwits, a prominent financial social media platform, and encompasses over 10,000 English comments annotated with both binary financial sentiments and twelve distinct emotion categories. By leveraging advanced annotation pipelines that combine human expertise with machine learning techniques, this dataset offers a robust foundation for conducting in-depth financial sentiment analysis and improving stock market prediction models.
The applicability of this dataset extends to various downstream tasks, including sentiment classification and multivariate time series forecasting. Through rigorous analysis and experimentation, we demonstrate how integrating detailed emotional annotations enhances the performance of machine learning models in accurately classifying sentiments and predicting market trends. This article is structured to first review the existing literature and highlight the gaps addressed by our work. It then details the methodology behind dataset creation and annotation, followed by comprehensive data analysis. Subsequent sections delve into the modeling approaches and experimental results, culminating in a discussion of the findings and their implications for the field of behavioral finance and investment strategy development.
By bridging the gap between nuanced emotional analysis and financial market prediction, this work contributes to the advancement of emotionally intelligent financial analytics, offering valuable insights for both academic research and practical investment applications.
Literature Review
The integration of Natural Language Processing (NLP) within the financial sector has garnered substantial attention in recent years, driven by the exponential growth of textual data generated from diverse sources such as social media, financial news, and analyst reports. Previous studies have demonstrated the efficacy of NLP techniques in extracting and quantifying financial sentiments, which in turn influence market predictions and investment strategies. For instance, Bollen, Mao, and Zeng (2011) pioneered the use of Twitter data to construct a public mood index, revealing significant correlations between social media sentiments and the Dow Jones Industrial Average. Similarly, Cortis et al. (2017) leveraged NLP to analyze sentiment from financial news articles, enhancing the predictive accuracy of stock price movements. These studies typically employ methodologies such as sentiment lexicons, machine learning classifiers, and deep learning models to interpret and quantify sentiments, underscoring the pivotal role of NLP in financial analytics.
Key findings from existing research highlight that incorporating sentiment analysis into financial models can substantially improve forecasting performance. Techniques ranging from traditional machine learning algorithms like Support Vector Machines (SVM) and Naïve Bayes to advanced deep learning architectures such as Long Short-Term Memory (LSTM) networks and Transformer-based models like BERT have been employed to capture and predict market sentiments. For example, Sawhney et al. (2020) demonstrated that combining sentiment scores derived from news articles with historical price data using LSTM models enhances the prediction of stock returns. Additionally, pre-trained language models have shown superior performance in understanding contextual nuances in financial texts, thereby providing more accurate sentiment classifications compared to rule-based or lexicon-based approaches.
Emotion classification in NLP extends beyond basic sentiment analysis by identifying a spectrum of emotions expressed in textual data. Traditional sentiment analysis typically categorizes text into binary classes — positive or negative — thereby offering a limited perspective on the underlying emotional states. In contrast, multi-class emotion classification aims to detect a diverse array of emotions such as joy, fear, anger, and sadness, providing a richer and more granular understanding of textual sentiments. Approaches to emotion detection often involve supervised learning techniques, where models are trained on annotated datasets to recognize specific emotional cues. Recent advancements have seen the application of deep learning models, including Convolutional Neural Networks (CNNs) and Transformer-based architectures, which excel in capturing complex emotional expressions and contextual dependencies within text.
Behavioral finance provides a theoretical foundation for understanding the impact of investor psychology and emotions on market behavior. The field integrates psychological insights into economic models to explain anomalies that traditional financial theories, such as the Efficient Market Hypothesis, cannot adequately address. Prominent theories in behavioral finance, including Prospect Theory (Kahneman and Tversky, 1979) and the Disposition Effect (Shefrin and Statman, 1985), illustrate how emotions like overconfidence, fear, and regret can lead to irrational investment decisions and market inefficiencies. Empirical studies have shown that investor emotions can drive significant market phenomena such as bubbles and crashes, emphasizing the necessity of incorporating emotional analysis into financial models to better predict and understand market dynamics.
Despite the advancements in NLP and behavioral finance, existing financial sentiment datasets exhibit notable limitations that impede the development of more sophisticated models. Datasets sourced from platforms like StockTwits and Twitter are prevalent in financial sentiment analysis research. For example, StockTwits provides a focused environment for financial discussions, yet many of its datasets are limited in size and often lack comprehensive emotional annotations. Twitter-based datasets, while large in volume, typically rely on binary sentiment labels and may suffer from noise and irrelevance due to the platform’s informal nature. Furthermore, these datasets frequently lack the granularity required to capture the multifaceted emotions that influence investor behavior, thereby restricting the depth of sentiment analysis.
The primary gaps identified in previous works revolve around the insufficient emotional depth and limited dataset sizes. Most financial sentiment datasets prioritize sentiment polarity over nuanced emotional states, thereby overlooking the rich spectrum of investor emotions that can provide deeper insights into market movements. Additionally, the scarcity of large-scale, emotion-annotated datasets hinders the training of robust machine learning models capable of capturing intricate emotional patterns. Addressing these gaps necessitates the development of comprehensive datasets that encompass a wide range of emotional annotations and are sufficiently large to support advanced modeling techniques. By doing so, future research can leverage more detailed emotional insights to enhance the accuracy and reliability of financial sentiment analysis and market prediction models.
Dataset Creation
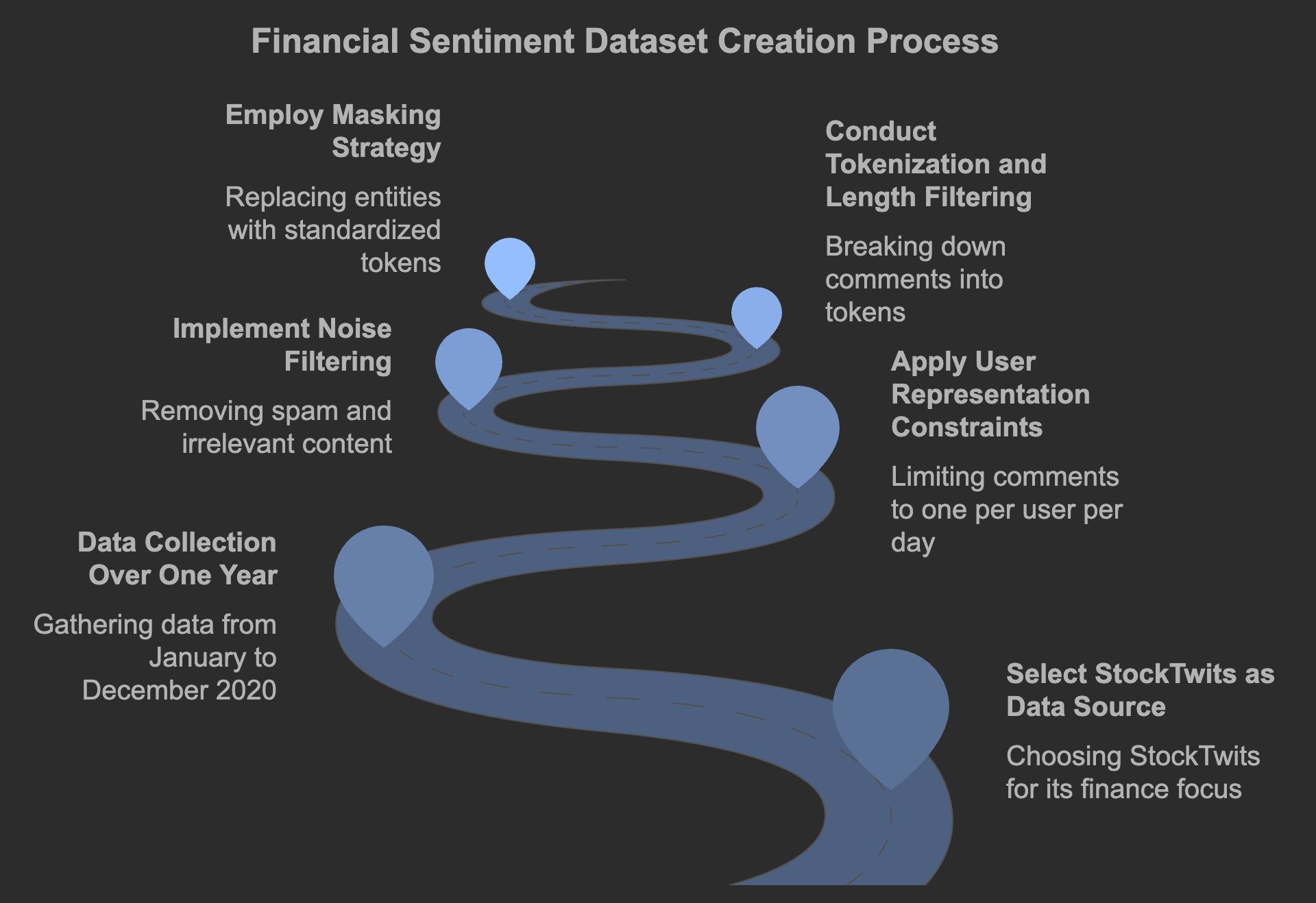
The foundation of any robust financial sentiment analysis and market prediction model lies in the quality and comprehensiveness of its underlying dataset. To address the limitations of existing financial sentiment datasets, we embarked on the creation of a novel dataset meticulously curated from StockTwits, a specialized social media platform dedicated to financial discussions. StockTwits serves as a vibrant hub where investors, traders, and financial enthusiasts converge to share insights, opinions, and real-time information about various financial instruments. Unlike more generalized platforms such as Twitter, StockTwits is inherently focused on finance, making it an ideal source for collecting relevant and concentrated financial discourse.
The selection of StockTwits as the primary data source was driven by several compelling factors. Firstly, StockTwits hosts a highly active and engaged user base that consistently generates a substantial volume of content centered around stock market discussions. This active participation ensures a steady influx of data, providing a rich repository of investor sentiments and emotions. Secondly, the platform’s structure, which incorporates features like cashtags (e.g., $TSLA) and predefined sentiment labels (bullish or bearish), facilitates the extraction of targeted financial information. These inherent features not only streamline the data collection process but also enhance the relevance and accuracy of the collected data for subsequent analysis.
Data collection for the dataset spanned a full calendar year, from January 1, 2020, to December 31, 2020. This timeframe was strategically chosen to capture a period marked by unprecedented market volatility and emotional turbulence due to the COVID-19 pandemic. The global health crisis induced significant fluctuations in financial markets, making it a fertile ground for studying the interplay between investor emotions and market dynamics. Over the course of the year, we amassed a substantial volume of data, comprising more than 10,000 English-language comments. These comments were sourced from discussions surrounding over 80% of the S&P 500 companies by market capitalization, ensuring broad coverage across major financial instruments and sectors. This extensive coverage not only enhances the dataset’s representativeness but also ensures that the findings derived from the analysis are generalizable across various market segments.
The raw data collected from StockTwits underwent a rigorous preprocessing pipeline to ensure its suitability for sentiment and emotion analysis. A critical aspect of this preprocessing involved user representation. To mitigate potential biases and ensure a fair representation of diverse investor perspectives, we imposed a restriction of one comment per user per day. This approach prevents overrepresentation of highly active users, thereby maintaining the dataset’s balance and enhancing its overall reliability.
Noise in social media data, such as advertising, spam, and irrelevant content, poses significant challenges to accurate sentiment analysis. To address this, we implemented a filtering mechanism that systematically removed advertising or commercial content. This was achieved by identifying and excluding comments from commercial usernames and detecting specific text patterns indicative of promotional content. By applying these heuristics, we ensured that the dataset predominantly comprised genuine investor sentiments and discussions, thereby enhancing the quality and relevance of the data.
Tokenization and length filtering constituted another essential step in the preprocessing pipeline. Utilizing the Natural Language Toolkit (NLTK), we tokenized each comment to break down the text into manageable units of analysis. To retain meaningful context and eliminate noise from excessively short or repetitive comments, we enforced a minimum threshold of four unique tokens per comment. Additionally, to ensure compatibility with advanced language models like BERT, we set an upper limit of 512 tokens per comment. This length filtering is crucial as it balances the need for contextual richness with computational efficiency, ensuring that the dataset remains both informative and manageable for downstream tasks.
A significant challenge in processing social media data is the presence of specific entities such as cashtags (e.g., $TSLA), hashtags (e.g., #market), and URLs, which can obscure the underlying sentiment and emotion. To address this, we employed a masking strategy where these entities were replaced with standardized tokens — [CTAG] for cashtags, [HTAG] for hashtags, and [URL] for website links. This normalization process not only preserves the structural integrity of the comments but also ensures that the models focus on the substantive content rather than being distracted by these entities. Furthermore, any comments composed solely of masked tokens were excluded from the dataset, as they lack meaningful textual information necessary for sentiment and emotion analysis.
Emojis play a pivotal role in conveying emotions and sentiments in social media communications. Recognizing their importance, we adopted a strategy to retain comments containing at least one emoji, ensuring that the emotional nuances expressed through these symbols are preserved. To facilitate accurate emotion detection, emojis were converted to their textual equivalents using established emoji dictionaries. For instance, a smiling face emoji would be translated to the word “happy,” thereby enabling the models to interpret the emotional context effectively. This conversion is essential as it bridges the gap between symbolic and textual representations of emotions, allowing for more precise sentiment and emotion classification.
The comprehensive preprocessing steps culminated in a refined dataset that is both rich in emotional annotations and free from significant noise or biases. By meticulously curating the data through user representation constraints, noise filtering, tokenization, masking, and emoji handling, we ensured that the dataset is well-suited for advanced financial sentiment analysis and market prediction tasks. The resulting dataset not only addresses the shortcomings of existing financial sentiment datasets in terms of size and emotional granularity but also sets a new standard for quality and comprehensiveness in financial NLP research.
Annotation Pipeline
The accuracy and reliability of any dataset, particularly one designed to capture nuanced emotions, are fundamentally dependent on the robustness of its annotation process. To ensure that our dataset authentically represents the diverse spectrum of investor emotions, we implemented a meticulous multi-step annotation pipeline that integrates human expertise with advanced machine learning techniques. This comprehensive approach not only enhances the quality of the annotations but also ensures scalability and consistency across the dataset.
Multi-Step Annotation Process
The annotation pipeline was structured into several interconnected stages, each designed to refine and validate the emotional labels applied to the dataset.
Seed Dataset Creation
The first phase involved the creation of a seed dataset, which comprised approximately 30% of the final dataset. This subset was carefully selected to ensure a balanced representation of the two primary financial sentiment classes — bullish and bearish. Achieving this balance was crucial for training a reliable classification model. Three seasoned financial experts were tasked with manually annotating this seed dataset. Their expertise ensured that the annotations were not only accurate but also contextually relevant to the financial domain.
To measure the consistency and reliability of the annotations, we calculated the inter-annotator agreement using the Cohen Kappa score, achieving a commendable score of 0.79. This high level of agreement indicated that the annotators had a shared understanding of the emotion categories and were applying them consistently across the dataset. Such a strong agreement is indicative of the clarity and effectiveness of the defined emotion taxonomy, laying a solid foundation for subsequent automated labeling processes.
Model Training
With the seed dataset in place, the next step involved training a BERT-based multi-class classification model. BERT (Bidirectional Encoder Representations from Transformers) is renowned for its ability to understand context in text data, making it an ideal choice for emotion classification. The model was fine-tuned on the manually annotated seed dataset, enabling it to learn the intricate patterns and nuances associated with each of the twelve defined emotion classes. This fine-tuning process adjusted BERT’s pre-trained parameters to better suit the specific task of emotion detection within financial texts, ensuring that the model could accurately differentiate between subtle emotional expressions.
Automated Labeling
Once the BERT model was sufficiently trained, it was employed to automate the labeling of the remaining 70% of the dataset. This phase involved applying the trained model to unlabeled comments, thereby generating initial emotion labels at scale. To capture temporal variations and ensure that the dataset reflected the dynamic nature of investor emotions over time, we implemented a strategy to maintain proportional representation across different months. This temporal stratification was essential for capturing shifts in investor sentiment that may correspond to significant market events or broader economic trends, thereby enhancing the dataset’s comprehensiveness and relevance.
Human Validation
Despite the high performance of the BERT model, human oversight remained indispensable to ensure the accuracy of the automated labels. In this phase, human annotators reviewed a subset of the model-generated labels, particularly focusing on instances where the model exhibited lower confidence or where the text contained ambiguous emotional cues. Annotators were responsible for either accepting the model’s labels or revising them to better reflect the true emotional context. This human-in-the-loop approach not only corrected potential errors but also provided additional annotated data, which was used to further fine-tune and improve the BERT model. Through iterative refinement, the model’s labeling accuracy was progressively enhanced, ensuring that the final dataset maintained high standards of quality and reliability.
Emotion Taxonomy Development
A critical component of the annotation pipeline was the development of a comprehensive emotion taxonomy. Drawing inspiration from behavioral finance and psychological studies, we defined twelve fine-grained emotion classes, including optimism, excitement, anxiety, and disgust. This taxonomy was meticulously crafted to capture the multifaceted emotional states that influence investor behavior, moving beyond the simplistic binary sentiment labels of positive and negative.
The twelve emotion classes were selected to provide a detailed and nuanced understanding of investor sentiments. For instance, optimism and excitement are often associated with bullish sentiments, reflecting positive expectations about market performance. Conversely, emotions such as anxiety and disgust may correlate with bearish sentiments, indicating concerns or negative outlooks. By defining these specific emotion categories, we aimed to capture the diverse emotional landscape that drives investment decisions and market dynamics.
In comparison to traditional binary sentiment labels, our multi-class emotion classification offers enhanced granularity and depth. Binary sentiment analysis, while useful, often fails to capture the complexity of human emotions, reducing the rich spectrum of investor sentiments to overly simplistic categories. In contrast, multi-class emotion classification allows for a more detailed and accurate representation of emotional states, facilitating deeper insights into how specific emotions influence market behavior. This enhanced granularity not only improves the precision of sentiment analysis but also enables more sophisticated modeling of the relationships between emotions and financial outcomes.
Data Quality Validation
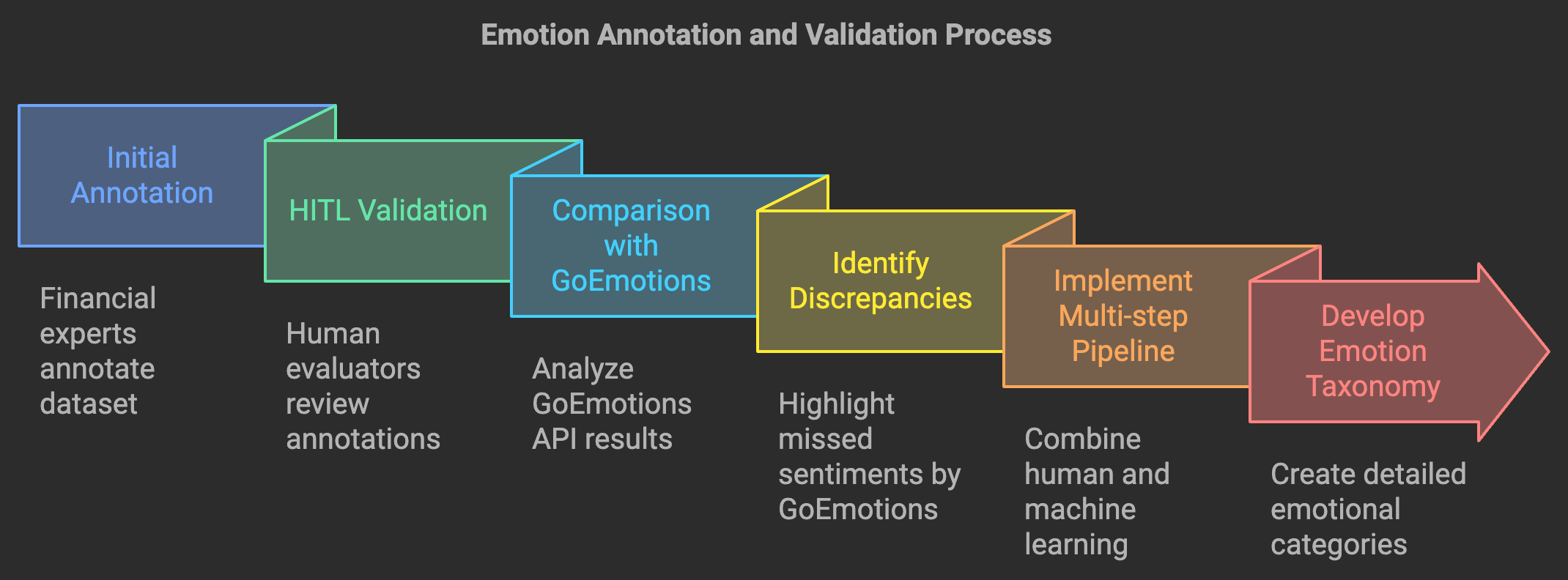
Ensuring the quality and reliability of the annotated dataset is paramount for the effectiveness of subsequent financial sentiment analysis and market prediction models. To validate the integrity and accuracy of our emotion annotations, we employed a rigorous Human-in-the-Loop (HITL) validation process, which involved a comparative analysis with existing emotion detection models and comprehensive strategies to maintain high-quality annotations throughout the dataset.
A critical aspect of our validation process was the comparison of our custom annotation approach with established emotion detection models, specifically the GoEmotions API developed by Demszky et al. (2020). GoEmotions is a widely recognized model that classifies text into 27 emotion categories or neutral. We applied the GoEmotions API to our StockEmotions dataset to assess its performance in the financial context. Remarkably, over 50% of the comments in our dataset were labeled as neutral by GoEmotions. This high rate of neutral classifications suggested that general emotion detection models may struggle to accurately capture the nuanced emotions expressed in financial discussions, which often contain domain-specific terminology and context.
To further investigate these findings, we enlisted the expertise of three human evaluators who were not involved in the initial annotation process. These evaluators meticulously reviewed a representative sample of comments that were labeled as neutral by GoEmotions. Their assessments revealed that a significant portion of these comments indeed conveyed clear emotional sentiments, such as optimism, anxiety, or excitement, which GoEmotions had failed to recognize. This discrepancy underscored the limitations of general-purpose emotion detection models in specialized domains like finance and validated the superiority of our custom annotation pipeline in capturing the true emotional landscape of investor communications.
To maintain the integrity of the dataset, several measures were implemented throughout the annotation process. Firstly, the multi-step annotation pipeline, which combines human expertise with machine learning, ensured that each comment was subjected to thorough scrutiny and contextual understanding. By involving financial experts in the initial annotation and subsequent validation stages, we minimized the risk of misclassification and ensured that the emotional labels accurately reflected the sentiments expressed by investors.
Additionally, we developed robust strategies to handle ambiguous or complex emotional expressions inherent in financial texts. Financial discussions often involve multifaceted emotions that can be challenging to categorize, such as sarcasm, irony, or mixed sentiments. To address this, our emotion taxonomy was designed with fine-grained categories that capture a wide range of emotional states, enabling annotators to more precisely label ambiguous expressions. Furthermore, during the human validation phase, annotators were provided with detailed guidelines and examples to aid in the consistent interpretation of complex emotional cues, thereby enhancing the overall quality and reliability of the annotations.
Data Analysis
A comprehensive analysis of the dataset is essential to uncover underlying patterns and insights that inform the relationship between investor sentiments, emotions, and market behaviors. This section delves into the descriptive statistics, emotion correlation analysis, and emoji usage within the dataset, highlighting key findings and their implications for financial sentiment analysis.
Descriptive Statistics
The dataset comprises a balanced distribution of financial sentiments, with 55% of the comments classified as bullish and 45% as bearish. This near-even split ensures that the analysis captures both optimistic and pessimistic investor perspectives, providing a robust foundation for sentiment classification and market prediction models. Within these sentiment classes, the distribution of emotions reveals significant imbalances. The most prevalent emotions include optimism (16%) and excitement (14%), which are commonly associated with bullish sentiments, reflecting positive expectations and enthusiasm about market performance. Conversely, emotions such as depression (2%) and panic (3%) are notably underrepresented, often linked to bearish sentiments and indicative of investor anxiety and fear during market downturns.
The average length of comments in the dataset is approximately 19.2 tokens per utterance, suggesting that the majority of investor expressions are concise yet informative. This brevity is characteristic of social media communications, where users convey sentiments and opinions succinctly. Additionally, the dataset showcases a diverse array of 761 unique emojis, underscoring the multifaceted ways in which emotions are expressed visually alongside textual content. The integration of emojis adds an extra layer of emotional depth, enhancing the ability of models to accurately interpret investor sentiments.
Emotion Correlation Analysis
Understanding how different emotions co-occur provides valuable insights into the complex emotional landscape of investor behavior. A correlation heatmap constructed from the dataset reveals several notable patterns. Strong positive correlations are observed between optimism and excitement, indicating that positive market sentiments often coexist with high enthusiasm and confidence among investors. Similarly, emotions such as anxiety and confusion show a positive correlation, reflecting periods of uncertainty and stress during volatile market conditions.
Conversely, negative correlations emerge between emotions like anger and belief, suggesting that heightened frustration may undermine investors’ confidence or conviction in their investment decisions. These inverse relationships highlight the dynamic interplay between different emotional states and their impact on market behavior. Additionally, the analysis identifies a prevalence of teasing within the comments, which is frequently labeled as either ambiguous or disgust. This trend underscores the nuanced and sometimes contradictory ways in which emotions are expressed, particularly in response to others’ investment losses or market events.
Emoji Analysis
Emojis serve as powerful tools for conveying emotions in a compact and visually engaging manner. An exploration of the most frequently used emojis in the dataset reveals that six emojis consistently rank within the top ten across both positive and negative sentiments. For instance, the 😂 (face with tears of joy) emoji is employed not only to express amusement and excitement but also to convey disgust and frustration, depending on the context. Similarly, the 🚀 (rocket) emoji is predominantly associated with bullish sentiments and excitement about stock performance, yet it can also imply skepticism or mockery when used sarcastically.
This dual functionality of emojis exemplifies their role in expressing complex and multifaceted emotions that may not be easily captured through text alone. The ability of emojis to convey multiple emotional states enhances the richness of sentiment analysis, allowing models to interpret subtler emotional cues embedded within investor communications. Moreover, the diverse use of emojis in the dataset highlights the importance of incorporating visual emotional indicators into sentiment analysis models to achieve a more comprehensive understanding of investor sentiments.
Insights and Implications
The detailed data analysis underscores the intricate relationship between investor sentiments, emotions, and market behaviors. The imbalance in emotion distribution suggests that while positive emotions like optimism and excitement are more frequently expressed, negative emotions such as anxiety and depression, though less common, play a critical role in market downturns and volatility. The strong correlations between specific emotions provide actionable insights for developing more nuanced sentiment classification models that can capture the complex emotional dynamics influencing market trends.
Furthermore, the multifaceted use of emojis highlights the necessity of integrating visual emotional cues into financial sentiment analysis frameworks. By leveraging both textual and visual data, models can achieve a more accurate and holistic understanding of investor emotions, ultimately enhancing the predictive power of financial analytics tools.
Modeling and Experiments
To demonstrate the practical utility of the StockEmotions dataset, we conducted comprehensive experiments focusing on two primary tasks: financial sentiment analysis and multivariate time series forecasting. These tasks were meticulously designed to leverage the rich emotional annotations and multimodal data embedded within the dataset, thereby showcasing its effectiveness in enhancing financial analytics.
Financial Sentiment Analysis
The financial sentiment analysis task was bifurcated into two distinct classifications: binary classification of financial sentiment and multi-class classification of twelve emotion categories. The binary classification aimed to categorize each comment as either bullish or bearish, reflecting positive or negative market sentiments, respectively. This foundational task serves as a critical indicator widely utilized in financial analytics. Concurrently, the multi-class classification sought to assign each comment to one of twelve finely-grained emotion categories, such as optimism, excitement, anxiety, and disgust. This granular approach provides a more nuanced understanding of investor sentiments, surpassing traditional binary sentiment analysis by capturing the complex emotional states that influence market behavior.
To ensure the robustness of our models, the dataset was divided into training, validation, and testing sets in the proportions of 80%, 10%, and 10%, respectively. This stratified splitting maintained the balance of sentiment classes and preserved the distribution of emotion categories across all subsets, thereby facilitating unbiased performance evaluations. The training set was utilized for model learning, the validation set for hyperparameter tuning and model selection, and the testing set for assessing the final model performance, thereby preventing overfitting and ensuring generalizability.
A diverse array of baseline models was employed to establish performance benchmarks for both classification tasks. Traditional machine learning approaches, including Logistic Regression, Naïve Bayes, and Support Vector Machines (SVM), were implemented to provide foundational performance metrics. These models were chosen for their simplicity and effectiveness in text classification tasks. Complementing these were neural network architectures such as Gated Recurrent Units (GRU) and Bidirectional GRU (Bi-GRU), which are adept at capturing temporal dependencies in sequential data. However, the standout performance was observed with pre-trained language models, specifically DistilBERT, BERTbase, and RoBERTabase. These models leverage advanced transformer architectures to understand contextual nuances in text, making them exceptionally suited for sentiment and emotion classification in financial texts.
The models were trained using the training set, with hyperparameters fine-tuned based on performance on the validation set. The primary evaluation metric for both sentiment and emotion classification tasks was the F1-score, which balances precision and recall, offering a comprehensive measure of model performance. Given the imbalanced distribution of emotion classes, techniques such as weighted loss functions and data augmentation were employed to mitigate bias towards more frequent classes. Weighted loss functions assigned higher penalties to misclassifications of minority classes, while data augmentation involved synthetically generating samples for underrepresented emotions to enhance model learning.
The results unequivocally demonstrated the superiority of pre-trained language models over traditional machine learning and neural network approaches. DistilBERT emerged as the top performer, achieving an impressive average F1-score of 0.81 for financial sentiment classification, surpassing all baseline models. In the multi-class emotion classification task, DistilBERT also led with an F1-score of 0.42, closely followed by BERTbase. These findings underscore the efficacy of leveraging pre-trained language models for nuanced sentiment and emotion analysis in financial texts, highlighting their ability to capture intricate emotional expressions that simpler models may overlook.
Multivariate Time Series Forecasting
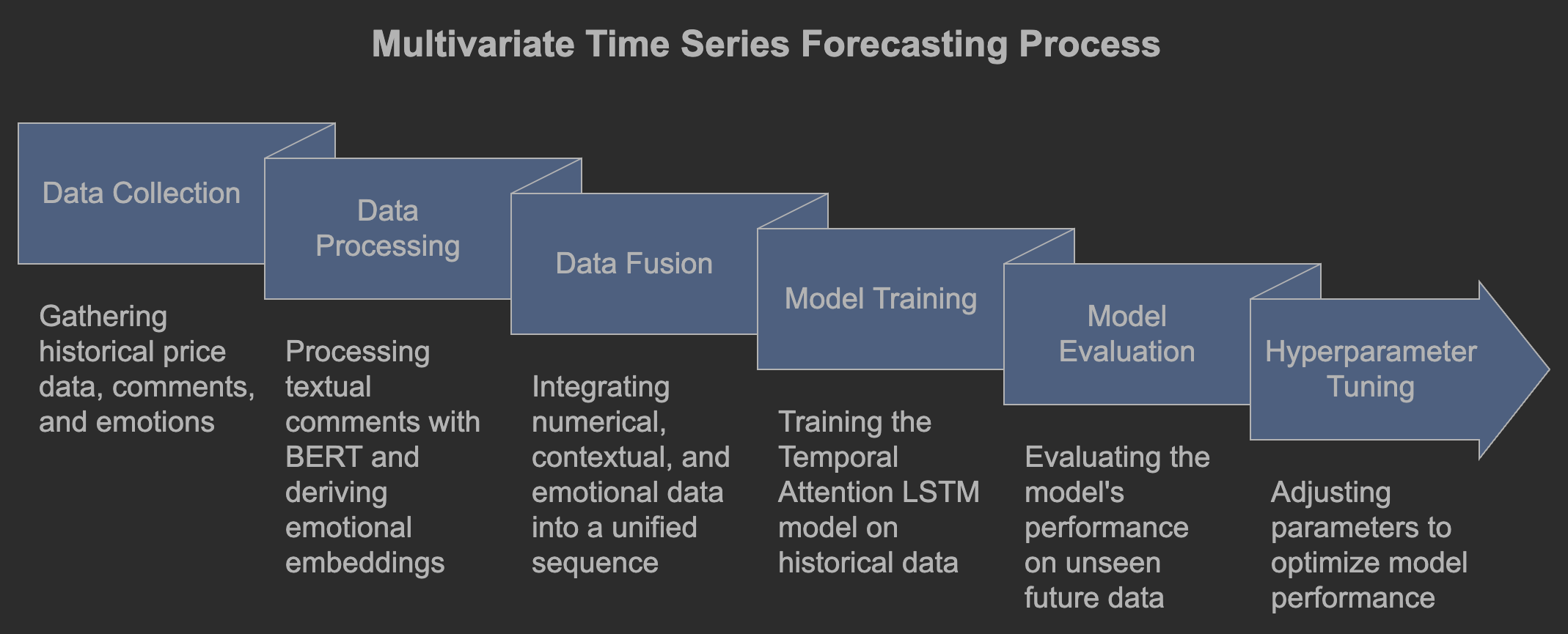
The multivariate time series forecasting task aimed to predict the S&P 500 index by integrating historical price data, textual comments, and emotion features derived from the StockEmotions dataset. This task was designed to evaluate whether incorporating emotional insights alongside traditional numerical data could enhance the accuracy of market predictions. To address this, we developed a Temporal Attention Long Short-Term Memory (LSTM) model that seamlessly integrates multiple data modalities.
The model architecture comprised three primary components: numerical data from historical stock prices, contextual information from textual comments processed through BERT for sentence embeddings, and emotional embeddings derived using GloVe (Global Vectors for Word Representation). These modalities were fused into a unified sequence, with the Temporal Attention mechanism enabling the model to focus on the most relevant parts of the input data. The LSTM component was responsible for capturing temporal dependencies and interactions between the numerical, contextual, and emotional features, thereby enhancing the model’s predictive capabilities.
The experimental setup involved splitting the dataset into training and testing sets based on temporal sequences: the training set included data from January 1, 2020, to September 3, 2020, while the testing set spanned September 4, 2020, to December 31, 2020. This temporal division ensured that the model was trained on historical data and evaluated on future, unseen data, simulating real-world forecasting scenarios. We experimented with various hyperparameters, including rolling window sizes of 2, 3, 5, 10, 15, 20, 25, and 30 days, hidden sizes of 25, 50, and 100 units, and training epochs of 100, 150, 200, and 250. These hyperparameters were systematically varied to identify the optimal configuration for minimizing prediction error.
The primary evaluation metric for forecasting accuracy was Mean Squared Error (MSE), which quantifies the average squared difference between predicted and actual S&P 500 index values. Lower MSE values indicate higher prediction accuracy. The Temporal Attention LSTM model demonstrated significant improvements in forecasting accuracy when integrating multiple data modalities. The best-performing configuration achieved an MSE of 0.83 × 10⁻³ with a rolling window size of 5 days, outperforming models that relied solely on numerical data or a combination of numerical and textual data. This performance enhancement highlights the added value of incorporating emotional features into time series forecasting models, suggesting that investor emotions play a critical role in market dynamics.
Implementation Details
The integration of multimodal data required careful preprocessing to ensure that numerical, textual, and emotional data were properly aligned and synchronized. Historical price data was normalized to facilitate efficient training, while textual comments and emotion embeddings were processed through their respective models (BERT and GloVe) to generate meaningful feature representations. This preprocessing was crucial for maintaining temporal alignment and ensuring that each modality contributed appropriately to the model’s predictive capabilities.
Training protocols were meticulously designed to maximize computational efficiency and model performance. The Temporal Attention LSTM was trained using batch processing with appropriate learning rates and optimization algorithms, such as the Adam optimizer, to ensure stable convergence. Computational considerations included leveraging GPU acceleration to handle the intensive training requirements of deep learning models, particularly given the integration of BERT-based embeddings and the temporal complexity of the LSTM architecture. This ensured that the models were trained efficiently without compromising on performance.
Results
The Temporal Attention LSTM model demonstrated significant improvements in forecasting accuracy when integrating multiple data modalities. The best-performing configuration achieved an MSE of 0.83 × 10⁻³ on the S&P 500 index, utilizing a rolling window size of 5 days. This performance surpassed models that relied solely on numerical data, which recorded higher MSE values, indicating less accurate predictions. Furthermore, models that incorporated both textual and emotional features exhibited superior accuracy compared to those using only numerical and textual data, highlighting the added value of emotional insights in enhancing market prediction models.
These results affirm the hypothesis that integrating investor emotions with traditional financial indicators can substantially improve the accuracy of stock market forecasts. The Temporal Attention LSTM effectively leveraged the complementary strengths of numerical trends, contextual sentiment, and emotional depth, providing a more holistic and informed basis for predicting market movements. This enhancement in predictive accuracy underscores the critical role that investor emotions play in shaping market dynamics, thereby validating the importance of incorporating emotional data into financial forecasting models.
Results and Discussion
The empirical evaluations conducted on the StockEmotions dataset yielded significant insights into the efficacy of incorporating investor emotions into financial sentiment analysis and stock market forecasting. This section presents the results of the financial sentiment analysis and multivariate time series forecasting tasks, followed by an in-depth discussion of the implications derived from these findings.
Financial Sentiment Analysis Results
Sentiment Classification
In the binary classification task, where the goal was to categorize comments as either bullish or bearish, the performance of the baseline models varied significantly. Traditional machine learning approaches such as Logistic Regression, Naïve Bayes, and Support Vector Machines (SVM) achieved moderate F1-scores, reflecting their basic capability to distinguish between positive and negative sentiments. However, the pre-trained language models, particularly DistilBERT, demonstrated a marked improvement, achieving the highest average F1-score of 0.81. This performance surpassed that of both traditional machine learning models and simpler neural network architectures like GRU and Bi-GRU, underscoring the superior contextual understanding and nuanced sentiment detection capabilities of transformer-based models.
Emotion Classification
In the multi-class classification task, DistilBERT also led the performance metrics, securing an F1-score of 0.42. This was closely followed by BERTbase, which achieved an F1-score of 0.40. While these scores indicate a moderate level of accuracy, they highlight the challenge posed by the imbalanced distribution of emotion classes within the dataset. Emotions such as optimism and excitement were more frequently detected, whereas rare emotions like panic and depression presented substantial detection difficulties. The lower performance on these less common classes underscores the inherent challenges in training models on imbalanced datasets, where the scarcity of certain emotion labels can lead to significant prediction biases.
Comparative Analysis and Implications
The comparative analysis unequivocally demonstrates the superiority of pre-trained language models over traditional machine learning and basic neural network approaches in both sentiment and emotion classification tasks. The enhanced performance of DistilBERT, in particular, highlights the importance of leveraging advanced transformer-based architectures that excel in capturing contextual and semantic nuances in textual data. These findings have profound implications for nuanced sentiment analysis in finance, suggesting that incorporating sophisticated language models can substantially improve the accuracy and reliability of sentiment detection, thereby enabling more informed investment decisions and market predictions.
Multivariate Time Series Forecasting Results
Performance Metrics
In the multivariate time series forecasting task, the objective was to predict the S&P 500 index by integrating historical price data, textual comments, and emotion features. The Temporal Attention LSTM model, which combined these multimodal inputs, achieved the best performance with a Mean Squared Error (MSE) of 0.83 × 10⁻³ using a rolling window size of 5 days. This result was a significant improvement over models that utilized only numerical data, which recorded higher MSE values, and models that combined numerical and textual data without incorporating emotion features.
Comparison and Added Value of Emotion Features
When comparing the different model configurations, it was evident that the inclusion of emotion features provided substantial enhancements in predictive accuracy. Models that integrated price index data with both textual and emotional features outperformed those relying solely on numerical or numerical plus text data. This demonstrates the added value of emotion features in capturing the underlying investor sentiments that drive market movements. By embedding emotional insights into the forecasting model, the Temporal Attention LSTM was able to leverage the nuanced emotional states of investors, leading to more accurate and reliable market predictions.
Impact of Emotion Features
The incorporation of emotion features significantly enhanced the model’s predictive capabilities. Emotions such as optimism and excitement were found to contribute positively to forecasting accuracy, aligning with bullish market trends and positive investor sentiment. Conversely, emotions like anxiety and disgust, although less frequent, provided critical indicators of market downturns and investor apprehensions. These findings highlight the importance of specific emotions in influencing market dynamics, suggesting that certain emotional states are more predictive of market movements than others. By capturing these emotional nuances, the model can better anticipate shifts in market trends, thereby offering a more comprehensive and informed basis for investment strategies.
Correlation Insights
The correlation analysis between different emotion classes revealed intriguing patterns that further illuminate the relationship between investor emotions and market behavior. Strong positive correlations were identified between optimism and excitement, indicating that these emotions often co-occur and collectively contribute to positive market sentiment. This synergy suggests that periods marked by high optimism and excitement are likely to experience bullish market trends, driven by confident and enthusiastic investor behavior.
Conversely, negative correlations were observed between emotions such as anger and belief, implying that heightened frustration or dissatisfaction may undermine investor confidence and belief in market stability. This inverse relationship underscores the complex interplay between different emotional states, where certain emotions can counteract or diminish the influence of others on market dynamics. Additionally, the prevalence of teasing within the comments was notable, often labeled as either ambiguous or disgust. This dual labeling reflects the nuanced and sometimes contradictory nature of investor communications, where teasing can simultaneously express frustration and amusement, depending on the context.
Emoji Usage Insights
Emojis play a pivotal role in conveying complex emotions within financial communications, serving as visual cues that complement textual expressions. The analysis of emoji usage within the dataset revealed that six emojis consistently ranked within the top ten across both positive and negative sentiments. For instance, the 😂 (face with tears of joy) emoji was used to express amusement and excitement, but also to convey frustration and disbelief in different contexts. Similarly, the 🚀 (rocket) emoji predominantly signified bullish sentiments and excitement about stock performance, yet it could also imply skepticism or irony when used sarcastically.
This dual functionality of emojis highlights their ability to encapsulate multifaceted emotional states, thereby enriching the sentiment analysis process. The integration of emojis into the dataset not only enhances the emotional depth captured by the models but also poses unique challenges for accurate interpretation. Sentiment analysis models must be adept at discerning the contextual meanings of emojis to avoid misclassification and ensure precise emotion detection. The nuanced use of emojis in financial communications underscores the necessity of incorporating visual emotional indicators into sentiment analysis frameworks to achieve a more comprehensive and accurate understanding of investor sentiments.
Conclusion
The results from both the financial sentiment analysis and multivariate time series forecasting tasks substantiate the critical role of investor emotions in financial analytics. The superior performance of pre-trained language models, particularly DistilBERT, in sentiment and emotion classification underscores the importance of advanced NLP techniques in capturing the nuanced emotional states of investors. Furthermore, the significant improvement in forecasting accuracy achieved by integrating emotion features into the Temporal Attention LSTM model highlights the added value of emotional insights in predicting market trends.
