

Enhancing Child Safety: Innovative Approaches to Detecting Explicit Content Online
Exploring automated technologies to identify and mitigate the spread of child sexual abuse materials through the collaborative efforts of law enforcement and tech companies.

Important information for paid subscribers at the end of this article.
Children around the world are at risk from CSAM. These materials must be found and stopped by police and tech companies. Reviewers typically review content manually, but an automated system can speed up the process and protect reviewers from harmful images. In this study, methods are examined for detecting explicit content, which is crucial for identifying illegal content. Three approaches are explored: an all-in-one classifier, a person detection classifier, and a private body part detector. Images from an online tool for reporting illegal content are used for testing. All tests are conducted on a secure server due to restrictions on data access.
The links to the documents are below. Arxiv.org/pdf/2406.14131 You can read the abstract at the following link: https://arxiv.org/abs/2406.14131.
This paper, titled “Detecting sexually explicit content in the context of child sexual abuse materials (CSAM): end-to-end classifiers and region-based networks,” was authored by Weronika Gutfeter, Joanna Gajewska, and Andrzej Pacut. They are affiliated with the Research and Academic Computer Network (NASK) in Warsaw, Poland. For more information, you can visit [www.nask.pl](http://www.nask.pl).
When additional neutral samples and adult pornography are included, the end-to-end classifier achieves 90.17% accuracy. It is true that detection-based methods are less accurate and cannot operate independently, but they do offer assistance. In models trained without direct access to data, human-focused methods yield more distinct results.
Researchers discuss how explicit images are classified as part of a larger project to find child sexual abuse materials. Experts prefer the term CSAM over child pornography, as it emphasizes the harm done to children. The development of an effective CSAM detector is challenging for a number of reasons.
Training and evaluation data are not available to all agencies, which is the main problem. Adult content models are used in some methods, but they are not sufficient. Pornography is also difficult to define since it differs from country to country. It was based on data provided by NASK-Dyżurnet experts. A classification system was proposed for identifying CSAM based on content analysis. Researchers tested three methods: a neural network, a silhouette classifier, and a body part detector. Due to data sensitivity, only false positives related to neutral or adult content could be displayed. Pornography and CSAM (child sexual abuse material) are detected in different ways. Microsoft’s PhotoDNA uses metadata or hashes to create a database of illegal files. Modified images and new data, however, can fool these blacklists. To enhance detection, machine learning models have been proposed. There are some models that target nudity, but that alone does not prove that an image is illegal. In particular, it is crucial to identify private body parts, such as genitalia and the anal region. Porn detection systems use these detectors to determine whether genital activity is taking place or if they are simply exposed.
Classification models can be used to detect pornographic or harmful content. Models such as these, which are typically deep neural networks, categorize images into different categories. In addition to detecting CSAM, they can determine if an image falls under other categories such as adult pornography or erotica. A binary classification (CSAM or not) or a NSFW classification (safe or unsafe for work) can be applied to images. Additionally, some models may separate images into CSAM, adult pornography, or neutral categories. Alternatively, some models only distinguish between nude and neutral images. Due to their complex decision-making process, these end-to-end models can be difficult to understand.
Organize this problem into smaller tasks to solve it. There are two parts to one model: one finds children and the other finds pornographic material. The final result is obtained by combining these parts. There is also another model with two steps: first, a neural network determines whether an image is pornographic. A support vector machine (SVM) determines whether it is adult porn or CSAM. It is more flexible to use multiple modules. It is effective to separate the task into finding children and identifying sexual content.
NASK-Dyurnet, an automatic CSAM detection system, is used by NASK-Dyurnet, a public agency. To determine the legality of images, videos, and text, experts collect and assess them. As a result of user reports, the agency developed a system for labeling the data.
An annotation process consists of two steps. First, images are labeled with CSAM classes, such as adult pornography or child erotism, and extra tags provide further information about sexual activity. To add additional details, boxes are drawn around people or body parts and their age, gender, and activity are noted. It is only applicable to a portion of the NASK-Dyurnet dataset due to its time-consuming nature.
There are two datasets in the dataset: DN-A and DN-C. Images and bounding boxes are included in DN-A. Sexual activity is not always shown in DN-C since it only has images. DN-A is the only subject of this study.
Legal restrictions restrict access to DN data. A direct link to the network is available only to members of the NASK-Dyurnet team. Despite being prohibited from viewing illegal images, authors can analyze combined results on a separate server. It is possible for legal images to contain nudity and explicit content involving adults and children. The distribution of samples is uneven across categories, according to NASK-Dyżurnet experts. CSAM (in the presence of a minor) has less than 50 samples, while “child erotism” has around 250. There is also a bias in terms of gender and age in the images. Approximately 75% of bounding boxes feature females, 45% feature female minors, and only 3% feature male minors. To address this imbalance, Researchers developed our own classification plan and included age and gender information in cross-validation tests.
For training and evaluation, the dataset DN is divided into DN-A and DN-C. It is difficult to classify neutral samples. 2203 samples are classified as sexual activity, 2715 as sexual posing, and 2770 as neutral (1206 with warnings). The DN-C contains 11578 samples: 972 are classified as sexual activity, 4152 as sexual posing, and 6454 as neutral (1887 with warnings). As some sexual posing images may contain sexual activity, DN-C has limited annotations. DN-C neutral labels are reliable and are used exclusively for pretraining. In order to detect illegal images, the system determines if they are CSAMs. By identifying minors and pornographic content, this is accomplished. Based on different body parts, age estimation models are used to predict a person’s age. The purpose of this study is to identify sexually explicit content on the Internet. A classifier is used to separate explicit images from non-explicit ones, and age estimation is combined to create CSAM detection.
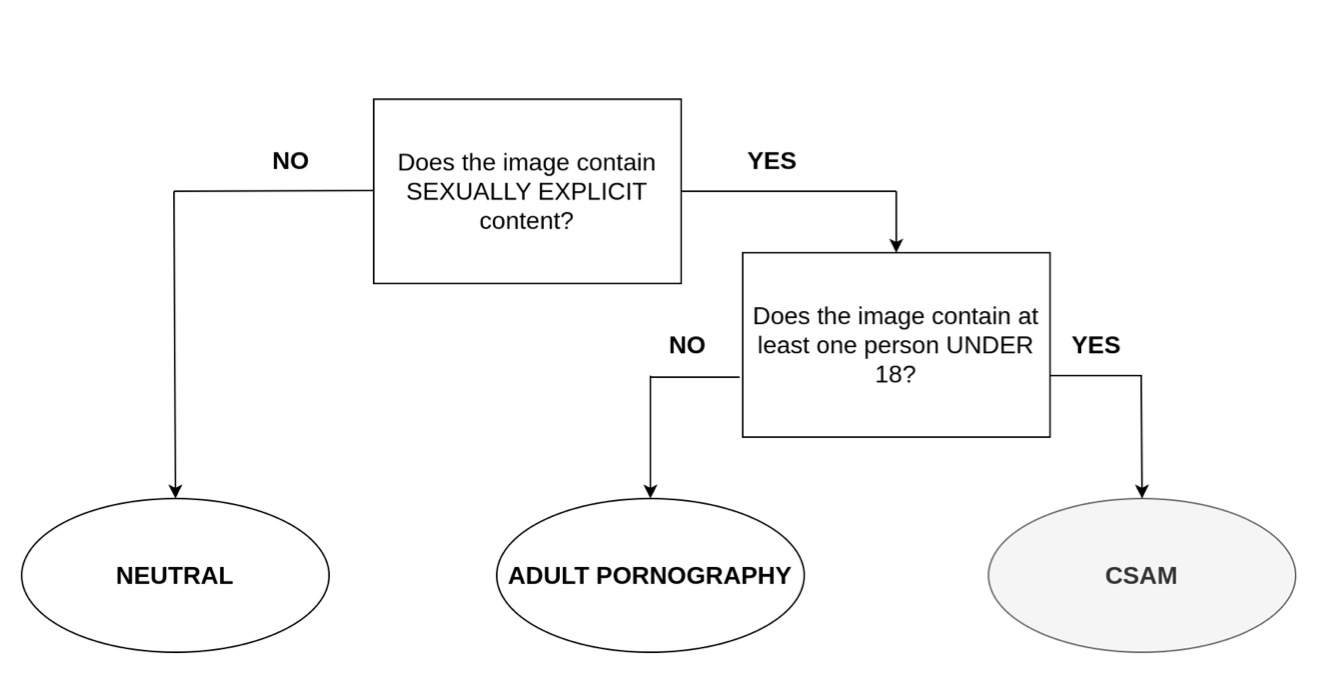
Image from research paper https://arxiv.org/abs/2406.14131.
A two-step process is shown in the figure. A model checks whether an image is sexually explicit first. Another model checks if any of the people in it are under 18. Then it is considered CSAM. Adult pornography is considered if it isn’t. The image is classified as neutral if the first check is negative.
Identifying SE and NS content or SE classification is challenging. Using expert annotations on analyzed data, Researchers gather insights. DN data will be aligned with other sources of pornographic images, even if they do not have specific classifications. Pornography-2K, for instance, categorizes images as “pornographic” or “non-pornographic,” while others categorize them as “safe” or “unsafe.” Researchers propose a new set of labels. According to the analysis, there are two types of sexual content: sexual activity and sexual posing. Intimate physical interactions are part of sexual activity. In sexual posing, someone poses suggestively while naked. Unlike neutral nudity photos, sexual posing photos show private parts and suggestive poses. Both training and evaluation datasets are equally balanced.
A sexual activity image is classified as SE, a sexual posing image is classified as SE, and a neutral image is classified as NS. A total of 29% of the images in the DN-A dataset depict sexual activity, and 35% depict sexual posing. Some of the remaining images may contain debatable content. A large percentage of the neutral images could be considered pornographic, possibly because they were gathered from online sources. The COPINE scale is used in this system. The terms “Explicit Erotic Posing” and “Explicit Sexual Activity” are equivalent. The categories below L6 in COPINE are neutral. In the final figure, images with sexual content (SE) are distinguished from those without (NS). SE is divided into two categories: sexual activity and posing. NS samples can include nudity and mild erotica samples.
Researchers use end-to-end models to classify sexually explicit content. Researchers need deep neural networks with a final layer that matches the three categories. Using a 3-channel RGB image as input, they predict the most likely category label. For this task, Researchers consider multiple convolutional networks, including ResNet-50, ResNet-101, EfficientNetV2-S, and EfficientNetV2-M. A pre-trained ImageNet model is used to initialize all models.
CSAM detects inputs into three groups, but binary classification would also work. For binary classification, a hierarchical cross-entropy loss function is used. There are two parts to this loss function. First, the content is classified into two categories: sexually explicit (SE) and non-sexual (NS). In the second part, sexual activity is classified into three categories: sexual posing, sexual activity, and neutral. As a result of testing, the parameter α is set to 0.5.
The model is evaluated using the DN-A dataset. Due to the lack of direct access to the data, some labels may be incorrect. A 10-fold cross-validation is performed to account for this. Each time, approximately 20% of the data is allocated for validation. A fold is based on DN categories determined by NASK-Dyurnet experts according to gender and age. Both male and female samples are included in each subset. By calculating Euclidean distance between features, near duplicates are eliminated.
Results of model comparison are displayed in the table. For SE and NS samples, “SE accuracy” represents the correct prediction count. Each group in the three-category set has a TPR for correctly predicted samples. There is ongoing research on the SEN-EM model, which has no size limitations, and the smaller SEN-ES model has also shown high accuracy.
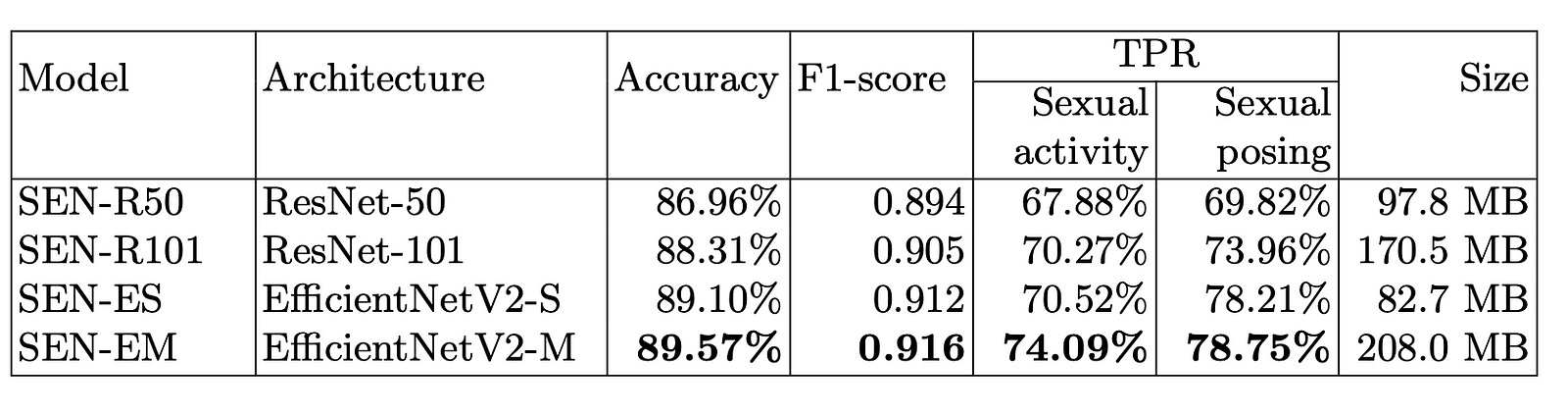
Image from research paper https://arxiv.org/abs/2406.14131.
Based on the DN-A dataset, the table displays outcomes for various models. The metrics measured include binary accuracy for SE (sexual explicit) and NS (non-explicit), F1-score, and TPR (true positive rate) for sexual activity and posing. The SEN-R50 (ResNet-50) has an accuracy of 86.96% with an F1-score of 0.894 and a TPR of 67.88% for sexual activity, and 69.82% for sexual posing. It has a size of 97.8 MB. SEN-R101 (ResNet-101) achieved 88.31% accuracy, 0.905 F1-score, 70.27% true positive rate for sexual activity, and 73.96% true positive rate for sexual posing. SEN-ES (EfficientNetV2-S) achieved an accuracy of 89.10%, an F1-score of 0.912, a TPR of 70.52% for sexual activity detection, a TPR of 78.21% for sexual posing detection, and a size of 82.7 MB. SEN-EM (EfficientNetV2-M): 89.57% accuracy, 0.916 F1 score, 74.09% TPR for sexual activity, 78.75% TPR for sexual posing, and 208.0 MB file size.
There are drawbacks to working with limited data. It is difficult for scientists to verify images for errors, and analyzing results becomes difficult. In addition, curating the dataset is difficult, and bias is primarily estimated by analyzing tags. Tests on the DN-A dataset indicated that neutral image samples needed to be included in the training set. Several samples from the COCO dataset are incorrectly labelled, including images with people holding food, objects near mouths, and beds, as well as images of hands and fingers. In order to improve results, Researchers include additional samples from external sources in the training set. Our experiments use images from the COCO dataset, which consists of over 120,000 images in 91 categories. Persons are represented by the ID 1 category. Compared to SE samples, neutral data is easier to find. Researchers gather SE samples by adding adult pornography images from the Pornography-2K dataset, which also includes video frames. As well as neutral images depicting people on a beach, young children, and contact sports, this dataset also contains neutral images labelled as “not pornographic difficult.”.
Pornography-2K has a problem with its neutral samples since some pornographic frames are not considered sexually explicit. Researchers addressed this by including labels that indicate body parts, specifically frames displaying genitalia or anal areas. In this study, a subset of images was deemed pornographic. A portion of the DN dataset with weak labels, called DN-C, was also initially used, but was not included in the primary training process.
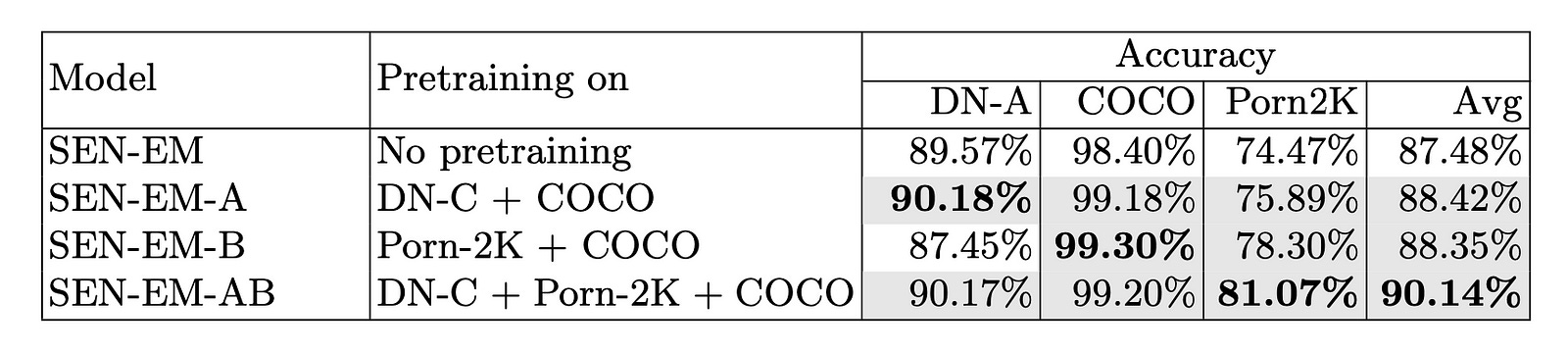
Image from research paper https://arxiv.org/abs/2406.14131.
The first step is to collect more samples of data. Our training process consists of two steps. First, Researchers train with external data from COCO, Pornography-2K, or DN-C. DN-A images are used in step two to fine-tune the model. The results are enhanced by this additional training. The accuracy results of DN-A dataset are compared to those of COCO and Pornography-2K test sets in Table 3. SEN-EM-A and SEN-EM-AB pretrained models outperform the baseline SEN-EM model. SEN-EM-AB has the highest average accuracy. DN-A accuracy decreases when using pornographic materials from Pornography-2K (creating the SEN-EM-B model). The reason may be due to the fact that adult content datasets and NASK-Dyrnet data are very different, or because video training repeats frames. Only training in Pornography-2K and COCO decreases DN-A accuracy from 89.57% to 70.99%, with little change in Pornography-2K test accuracy. As a result, DN-A is a superior source for learning SE classifications.
SE classifiers with additional pretraining on external databases are shown in Table 3. Cells in grey indicate values that are superior to the baseline model SEN-EM without pretraining. With no pretraining, SEN-EM scores 89.57% on DN-A, 98.40% on COCO, and 74.47% on Porn2K, with an average of 87.48%. SEN-EM-A scores 90.18% on DN-A, 99.18% on COCO, and 75.89% on Porn2K, with an average of 88.42% on DN-C and COCO. Pretrained on Porn2K and COCO, SEN-EM-B achieves 87.45% on DN-A, 99.30% on COCO, and 78.30% on Porn2K, with an average of 88.35%. In pretrained tests on DN-C, Porn2K, and COCO, SEN-EM-AB achieved 90.17% on DN-A, 99.20% on COCO, and 81.07% on Porn2K, with an average of 90.14%. People’s positions in images should be matched with key features in SE classification. As a result, the classification will be able to identify patches showing naked individuals, posing, or engaging in sexual activities. The classification can be expanded and diversified by adding additional labels related to people in the future. Instead of using an end-to-end classifier, this study recommends using a person detector. Two stages are involved in the recommended method: it first detects all people in the image, and then it applies the classifier to each one. All the detected people’s information is combined and the label with the highest value is selected. Labels range from neutral (1) to sexual activity (3), and if one person is marked as sexual, the entire image is labeled as sexual.
Faster-RCNN, SSD, and YOLO are region-proposal networks that can be used to detect people. Models from PyTorch and mmdetection (YoloX-L) were tested against DN-A ground-truth bounding boxes. Because pornographic images differ from the usual training images, they are challenging for detection algorithms. It is difficult to capture images of intercourse or sexual activity because they often lack a full body silhouette and have occluded bodies. It is easier to detect images of individuals posing sexually since they are alone and clearly visible. Based on the COCO benchmark, Table 4 shows the detection results for the three algorithms using average precision at IOU=0.5.

Image from research paper https://arxiv.org/abs/2406.14131.
The next step is to merge detection and classification. For classification, Researchers use the SEN-EM-AB model. Data from detected patches is used to count the number of correctly classified images. Researchers compare our end-to-end classifier with ground-truth detection coordinates in Table 5. End-to-end classifiers are more effective than patch-based detection. There may be important features outside the detected areas, or the detector might miss important components. When compared to an end-to-end classifier, patch-based aggregation improves recall for the sexual activity class.
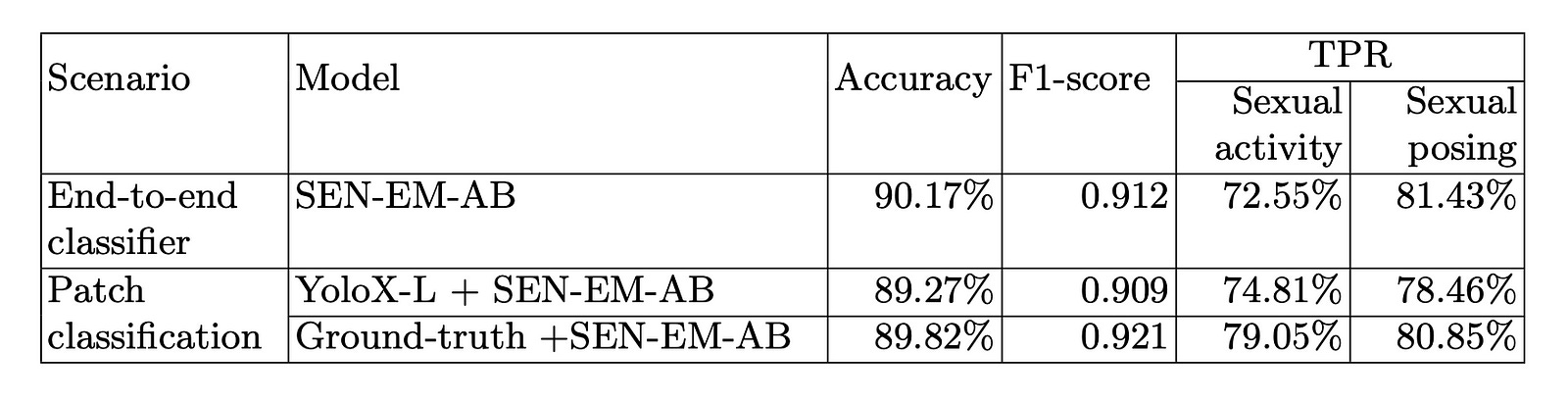
Image from research paper https://arxiv.org/abs/2406.14131.
Three models are shown in Table 4 for person detection accuracy on the DN-A dataset: SSD, FasterRCNN (ResNet-50), and YoloX-L. A model’s average precision (AP) and average recall (AR) are evaluated. SSDs achieved an AP of 0.819, AR of 0.941, and a size of 136.0 MB. The FasterRCNN achieved an AP of 0.843, an AR of 0.947, and a size of 167.1 MB. An AP of 0.845, AR of 0.914, and size of 217.3 MB were achieved by YoloX-L.
The SE classification results based on patches from the person detector are shown in Table 5. SEN-EM-AB classifier had an accuracy rate of 90.17%. A 0.912 F1-score was also achieved, with a 72.55% true positive rate for sexual activity and an 81.43% true positive rate for sexual posing. In patch classification, YoloX-L + SEN-EM-AB achieved 89.27% accuracy with a 0.909 F1-score, 74.81% TPR for sexual activity, and 78.46% TPR for sexual posing. In this study, ground-truth + SEN-EM-AB classification was 89.82% accurate. 0.921 was the F1-score. The true positive rate (TPR) for sexual activity was 79.05%, and the TPR for sexual posing was 80.85%.
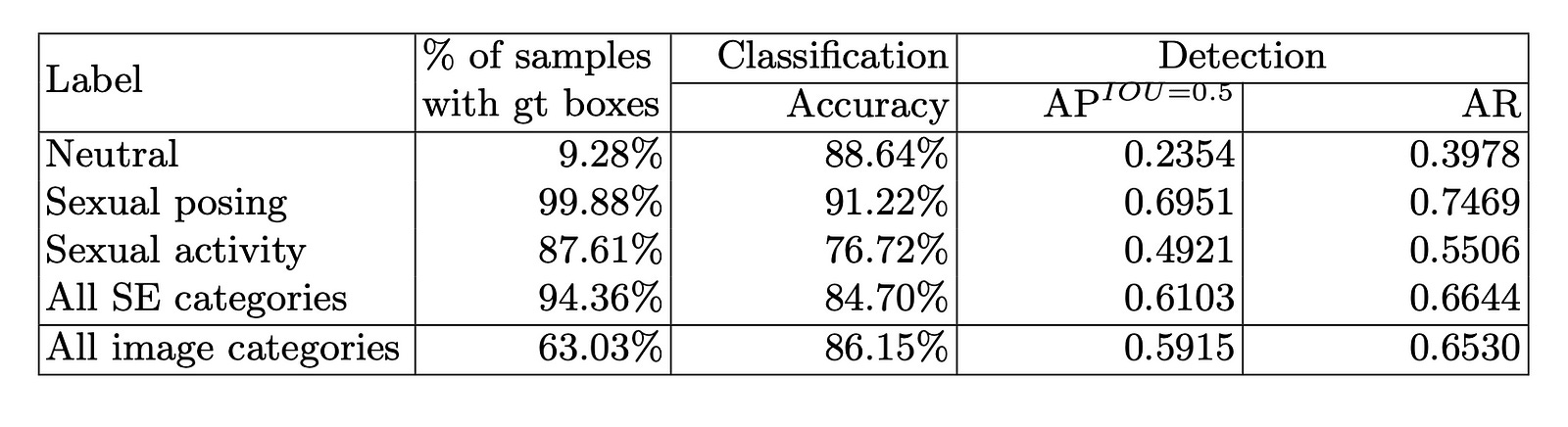
Image from research paper https://arxiv.org/abs/2406.14131.
In order to determine if an image is sexual, it is not enough to detect visible genitalia. Images such as children bathing or people on a nude beach show intimate body parts without any sexual content. In order to distinguish between illegal sexual images and legal erotic images, it is important to identify private body parts. Body part detectors detect nudity in images by scanning for intimate body parts. Anal areas and male and female genitalia are identified using the DN-A dataset and YoloX-L model. This system is evaluated using average precision (AP) and average recall (AR) at IOU=0.5, as well as its classification accuracy. Its main goal is to detect intimate body parts. To emphasize distinctions, Table 6 displays evaluation results for three SE categories.
Because sexual activity pictures often lack clear genitalia, the model’s accuracy is lowest. In contrast, it performs better with pictures of sexual posing, which usually include visible genitalia. Over 9% of neutral images include visible body parts, indicating moderate accuracy. Moreover, more than 12% of sexual activity pictures show explicit actions without visible genitalia. A proper classification requires more than just detecting private parts.
Due to their small size, it is difficult to detect private body parts in pictures. In regular images, it can be difficult to avoid mistakes. It is possible for private parts to resemble armpits, lips, or fingers. With an accuracy of 91.22%, the detector is effective at detecting sexual poses and accurately predicting nudity.
Based on the DN-A dataset, Table 6 shows the accuracy of detecting body parts and classifying explicit content. Images that are neutral are: 9.28% of respondents have ground-truth boxes Classification accuracy of 88.64% The AP is 0.2354 The AR is 0.3979. 99.88% of sexual posing photos have labeled boxes, 91.22% accuracy in classification, AP = 0.6951, AR = 0.7469. 87.61% of the boxes have been authenticated, with a classification accuracy of 76.72%, an AP of 0.4921, and an AR of 0.5506. There are ground-truth boxes in 94.36 % of sexual categories. With an AP of 0.6103 and an AR of 0.6644, the classification accuracy is 84.70%. Category-wise, 63.03% have ground-truth boxes, and 86.15% have accurate classification, with an AP of 0.5915 and an AR of 0.6530.
Using neural networks to identify and categorize inappropriate images, including people and private body parts, is discussed in the article. Models were tested using real-world data, assessed by experts. Our goal is to leverage their expertise in developing an automated system that minimizes the need for human reviewers.
Images are categorized into three types: sexual activity, sexual posing, and neutral. In order to ensure an equal number of samples in each group, Researchers analyzed data. The system successfully differentiates between these groups in tests. Detecting body parts, for instance, identifies sexual poses in which private parts are visible.
DN, COCO, & Pornography-2K neutral samples were examined because Researchers had limited data. Increased training data, particularly neutral samples, enhances accuracy and reduces false positives. Additionally, Researchers collected additional adult pornography samples, which differ from DN data in terms of the definition of sexual content. The majority of adult pornography consists of video content, which often contains close-up frames that appear explicit when viewed in context, but are unclear when viewed individually.
Although the classifier had a high accuracy, it performed better when used with detectors for human shapes & body parts. False positives are highlighted in paper. The COCO dataset images were incorrectly labeled as SE by a model trained only on DN-A, but this was resolved by using additional datasets. There were false positives in the DN-A dataset, where small body parts like armpits, lips, or fingers were incorrectly classified as intimate.
Using detectors for human shapes and body parts improves the clarity and accuracy of the classification system.
