

Exploring How Small Errors in Code Can Trigger Catastrophic Events Across Industries
The Hidden Perils of Software Bugs: Lessons from Real-World Failures

In today’s digital age, software is integral to daily life, influencing entertainment, finance, healthcare, and national defense. Its pervasive presence underscores the necessity for reliability; however, even minor bugs can lead to significant consequences. This article explores real-world instances where software bugs have resulted in surprising, costly, and sometimes tragic outcomes. By examining these cases, we illustrate how seemingly small errors can escalate into major global issues, affecting not just individual users but entire industries and societies.
The Cost of Software Bugs
Software bugs vary in severity, from minor glitches that annoy users to severe failures compromising safety and security. The financial implications are substantial. According to the Systems Sciences Institute at IBM, fixing an error after product release can be four to five times more expensive than addressing it during the design phase and up to 100 times more costly if identified during maintenance. This highlights the importance of early detection and robust testing processes in the Software Development Life Cycle (SDLC).
Understanding Software Bugs
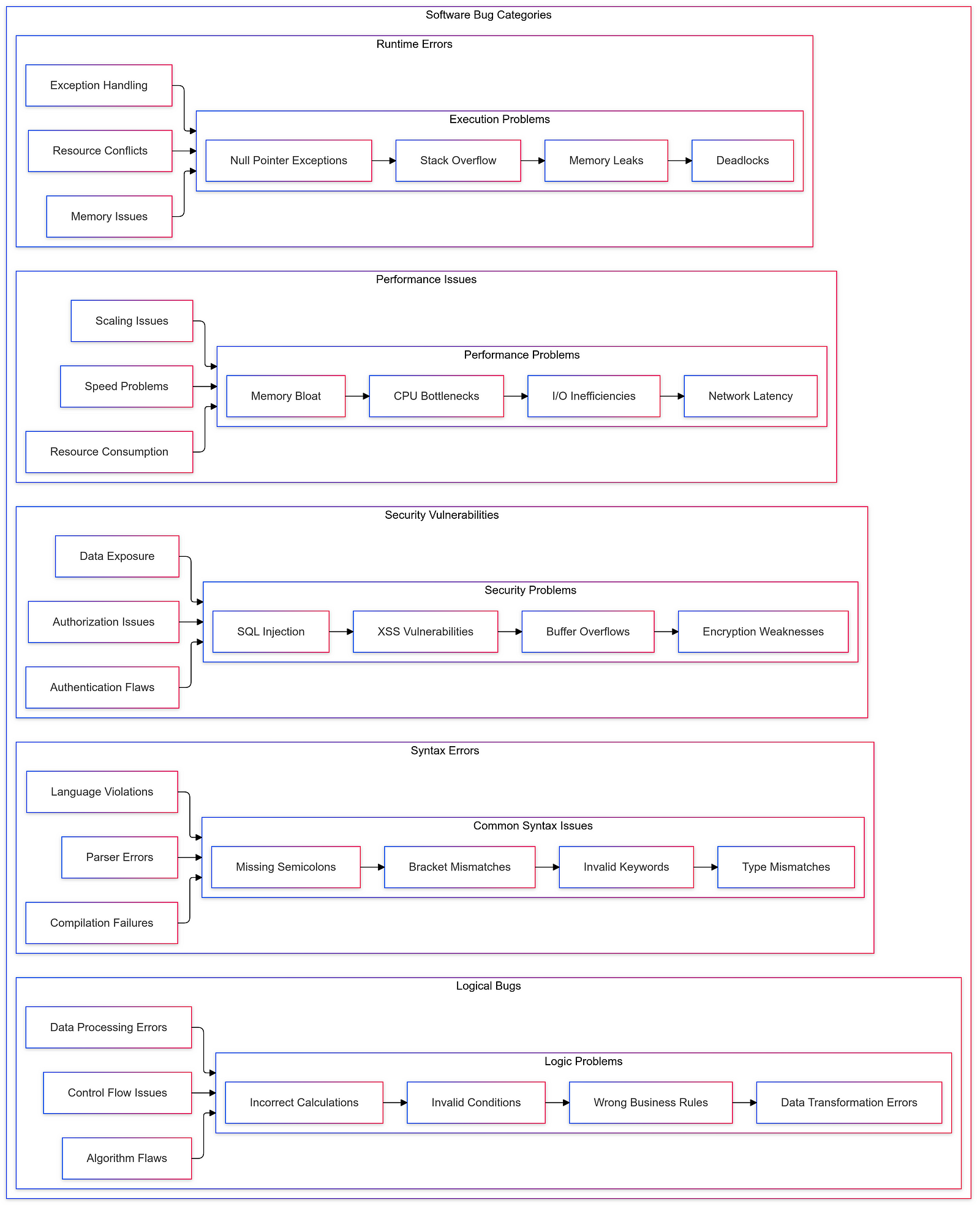
Software bugs can be categorized into several types based on their nature and impact:
Syntax Errors: Simple mistakes such as typos or incorrect punctuation that prevent code from compiling.
Logical Bugs: Errors where the code runs without crashing but produces incorrect results due to flawed logic.
Runtime Errors: Issues that arise during program execution, often due to unexpected inputs or conditions.
Performance Bugs: Problems that cause applications to run slower than intended or consume excessive resources.
Security Bugs: Vulnerabilities that expose systems to unauthorized access or data breaches.
Understanding these categories helps developers prioritize testing efforts and focus on areas that could lead to significant failures if left unchecked.
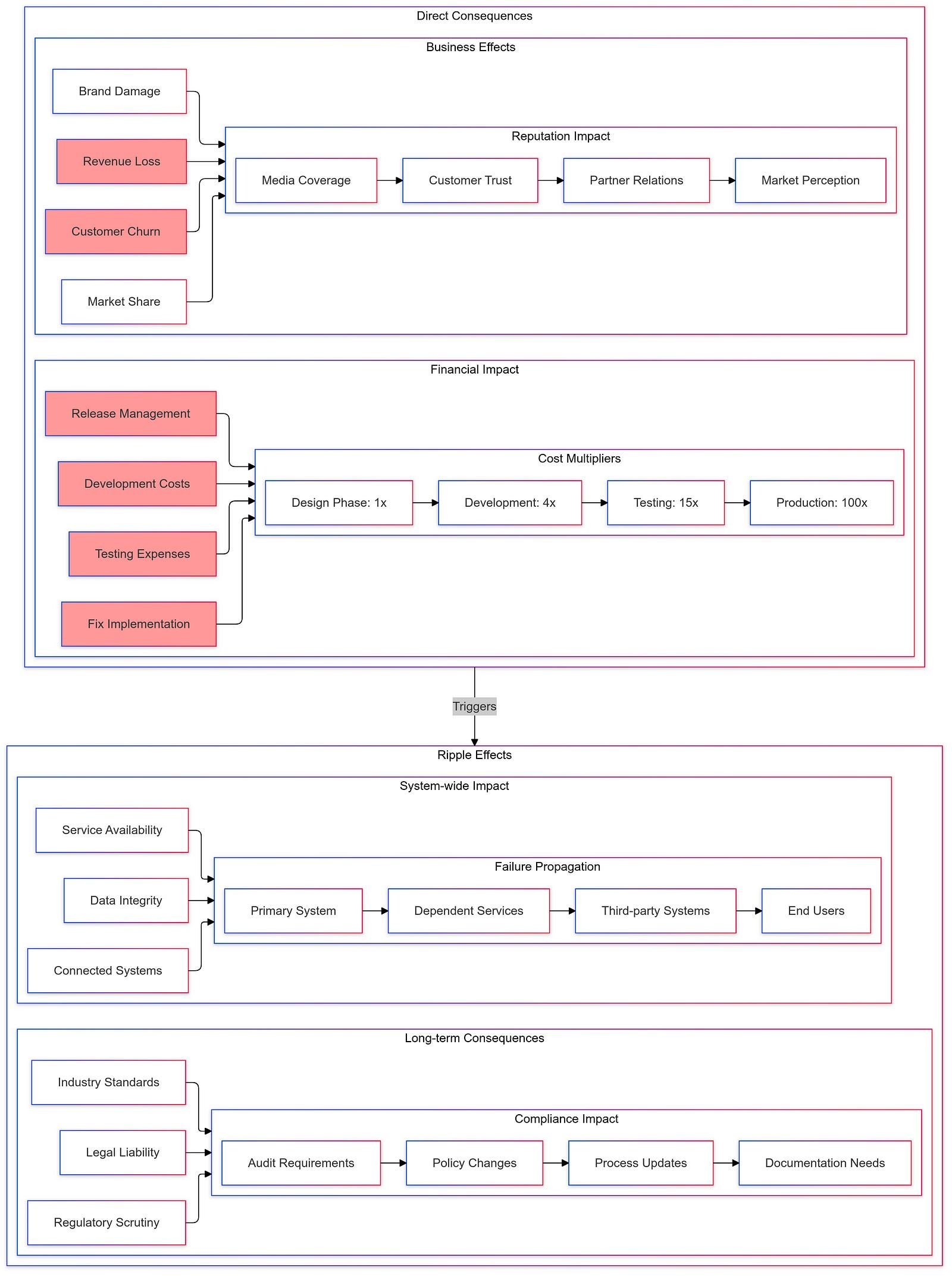
The Ripple Effect of Software Bugs
The impact of software bugs extends beyond immediate financial losses; they can also lead to long-term damage to brand reputation and customer trust. Companies like Knight Capital and Toyota faced not only monetary repercussions but also extensive media scrutiny and legal challenges following their respective incidents.
Moreover, as software systems become increasingly interconnected — especially with the rise of IoT devices — the potential for cascading failures grows exponentially. A bug in one system can trigger failures across multiple platforms, leading to widespread disruptions.
The Gandhi Aggression Bug in Civilization
The Civilization series, developed by Sid Meier, has long captivated players with its intricate blend of strategy, diplomacy, and historical simulation. One of the most intriguing aspects of the game is how it assigns aggression levels to its leaders, which significantly influences their diplomatic behavior and interactions with players. Among these leaders, Mahatma Gandhi, known for his pacifist ideals in real life, has become infamous within the gaming community for his unexpected aggressiveness, particularly in the later stages of gameplay. This phenomenon stems from a coding oversight that transformed Gandhi into a hyper-aggressive leader, creating an ironic twist that has left a lasting legacy in gaming culture.
Aggression Levels in Civilization
In Civilization, each leader is assigned an aggression rating that dictates their likelihood of engaging in warfare and their general diplomatic demeanor. This rating typically ranges from 1 to 10 (or higher in some versions), with lower numbers indicating a more peaceful disposition. Gandhi was designed with the lowest aggression level possible, a score of 1, reflecting his historical reputation as a proponent of non-violence and diplomacy. This meant that Gandhi would rarely initiate conflict or declare war unless provoked.
However, the complexity of the game’s mechanics led to an unforeseen consequence when players adopted certain governmental forms. One such form is democracy, which was intended to promote peace among nations. In the original Civilization game released in 1991, adopting democracy would automatically reduce a leader’s aggression score by 2 points. For Gandhi, this reduction created a significant issue.
The Integer Underflow
When players transitioned to democracy while controlling Gandhi, his aggression score was reduced from 1 to -1 (1–2 = -1). In programming terms, particularly within the constraints of the game’s code using unsigned integers (which can only represent non-negative values), this negative score could not be processed correctly. Instead of reflecting a negative value, the game experienced an integer underflow — essentially looping back around to the maximum value representable by an 8-bit unsigned integer: 255.
This bug meant that rather than becoming less aggressive as intended, Gandhi’s aggression level skyrocketed to 255, making him one of the most aggressive leaders in the game. The irony was palpable; a character designed to embody peace now became a formidable nuclear threat capable of launching devastating attacks against other civilizations.
Gandhi as a Nuclear Threat
The implications of this bug were profound and amusing in equal measure. Players soon discovered that Gandhi would frequently engage in nuclear warfare despite his low initial aggression rating. This behavior stood in stark contrast to his historical persona and became a defining joke within the Civilization community. Players would often find themselves on the receiving end of nuclear strikes from Gandhi, leading to humorous anecdotes and memes about “Nuclear Gandhi,” who paradoxically wielded atomic weapons with reckless abandon.
As players progressed through the game and unlocked nuclear technology — typically available after transitioning to democracy — they would witness Gandhi transform from a peaceful leader into a hyper-aggressive adversary. This unexpected twist not only added an element of surprise but also highlighted how coding errors could lead to memorable gameplay experiences.
Resolution and Legacy
The developers at Firaxis Games were initially amused by this unintended consequence when it was brought to their attention. Rather than fixing what many viewed as a humorous quirk of the game, they chose to embrace it. In subsequent iterations of the Civilization series, elements of this “bug” were retained as Easter eggs or intentional design choices. For instance, in Civilization V, while Gandhi’s diplomatic approach remained generally peaceful compared to other leaders, he was still programmed with a notably high likelihood to use nuclear weapons when provoked.
This legacy has continued into newer titles like Civilization VI, where Gandhi features a hidden agenda known as “Nuke Happy.” This agenda not only emphasizes his propensity for nuclear warfare but also allows him to express admiration for other civilizations that develop similar capabilities while disdaining those that do not.
The story of “Nuclear Gandhi” serves as an example of how bugs can evolve into beloved features within video games. What began as a coding oversight transformed into an iconic aspect of gaming lore, illustrating the unpredictable nature of software development and player interaction with digital environments.
The Boeing 737 MAX Tragedy: A Cautionary Tale of Software Flaws and Design Oversights
The Boeing 737 MAX, once heralded as a technological advancement in aviation, became synonymous with tragedy and controversy following two catastrophic crashes that claimed 346 lives. At the heart of these disasters was the Maneuvering Characteristics Augmentation System (MCAS), a software feature designed to enhance the aircraft’s handling characteristics. However, a series of critical design flaws and operational failures in MCAS ultimately led to the fatal incidents, underscoring the importance of rigorous software development and safety protocols in the aviation industry.
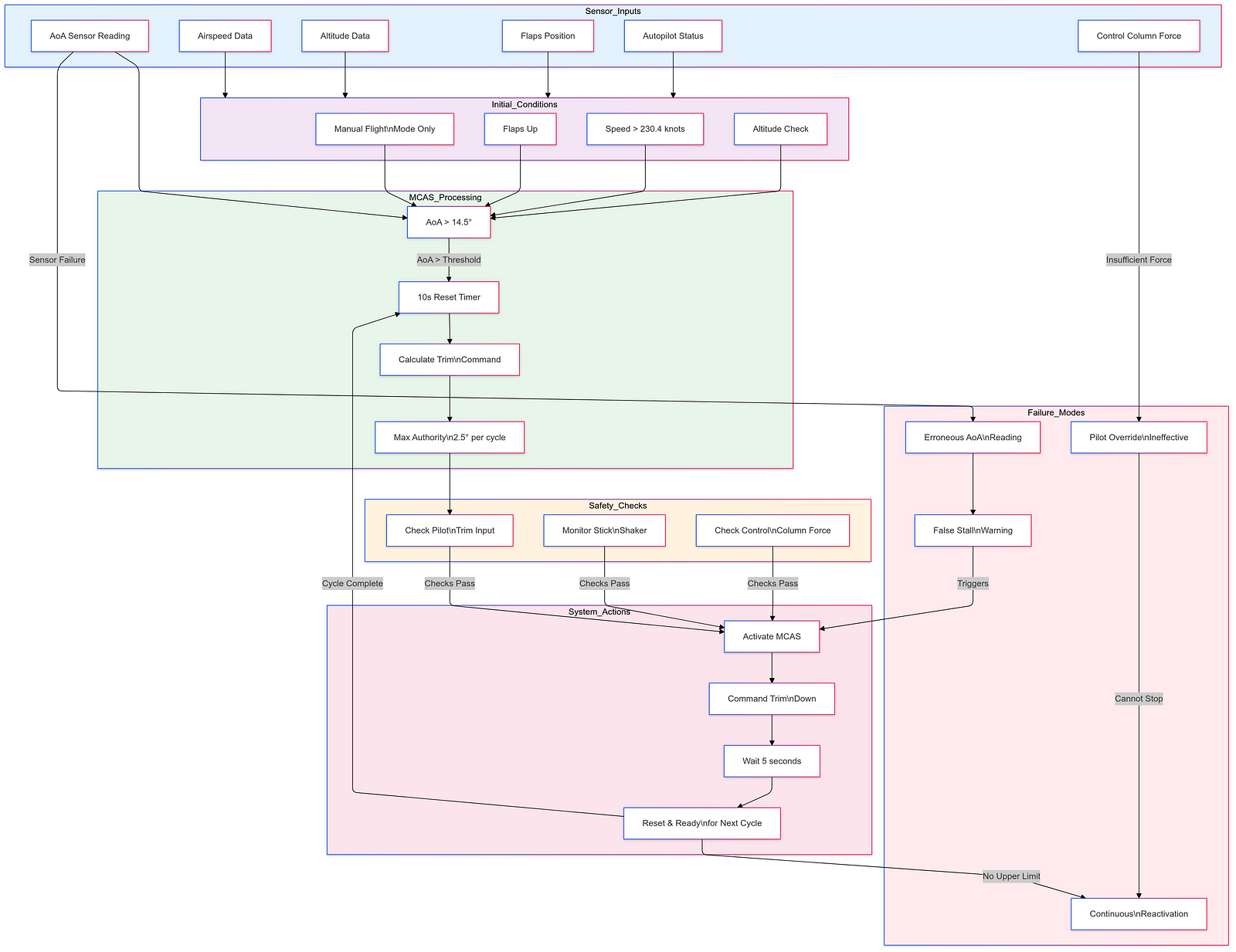
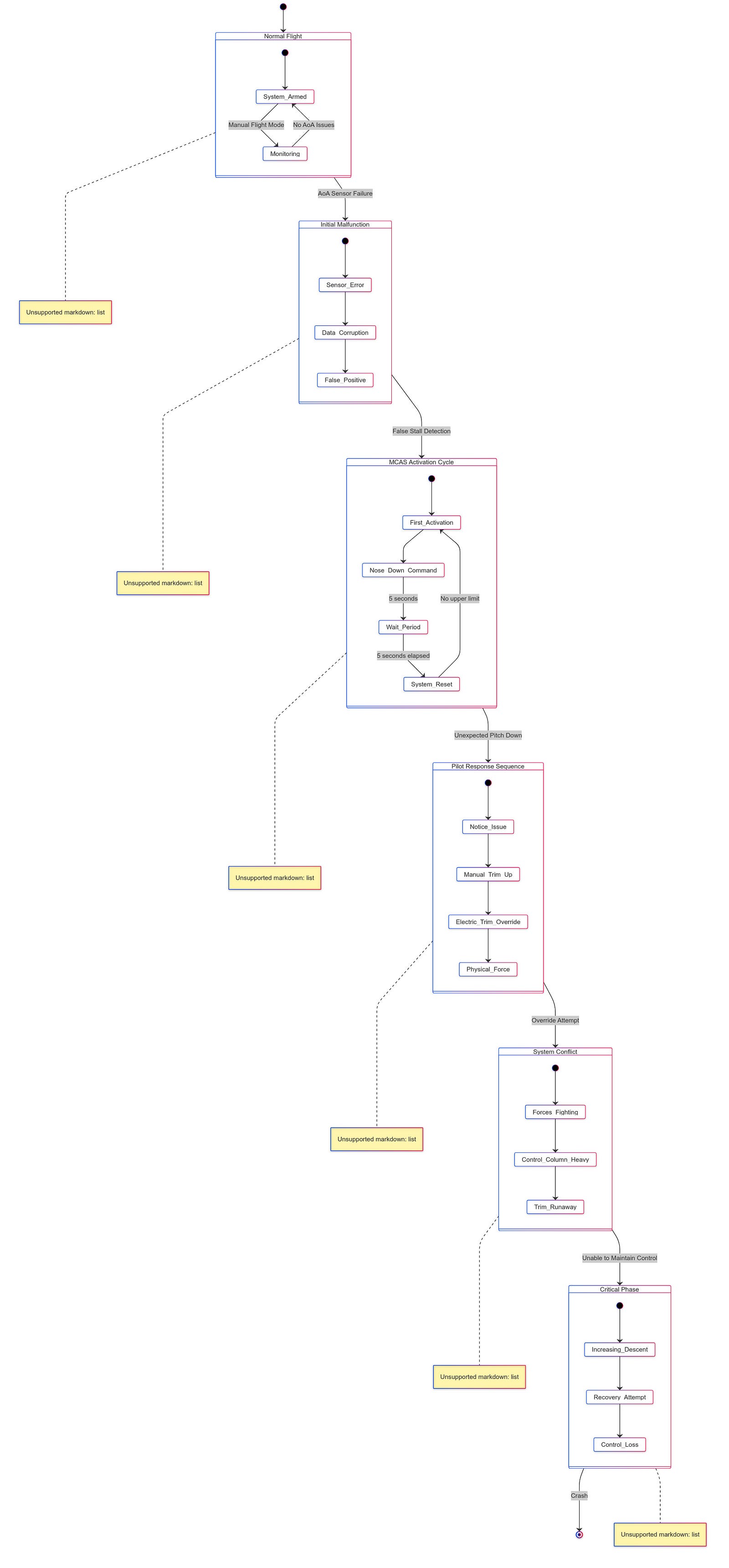
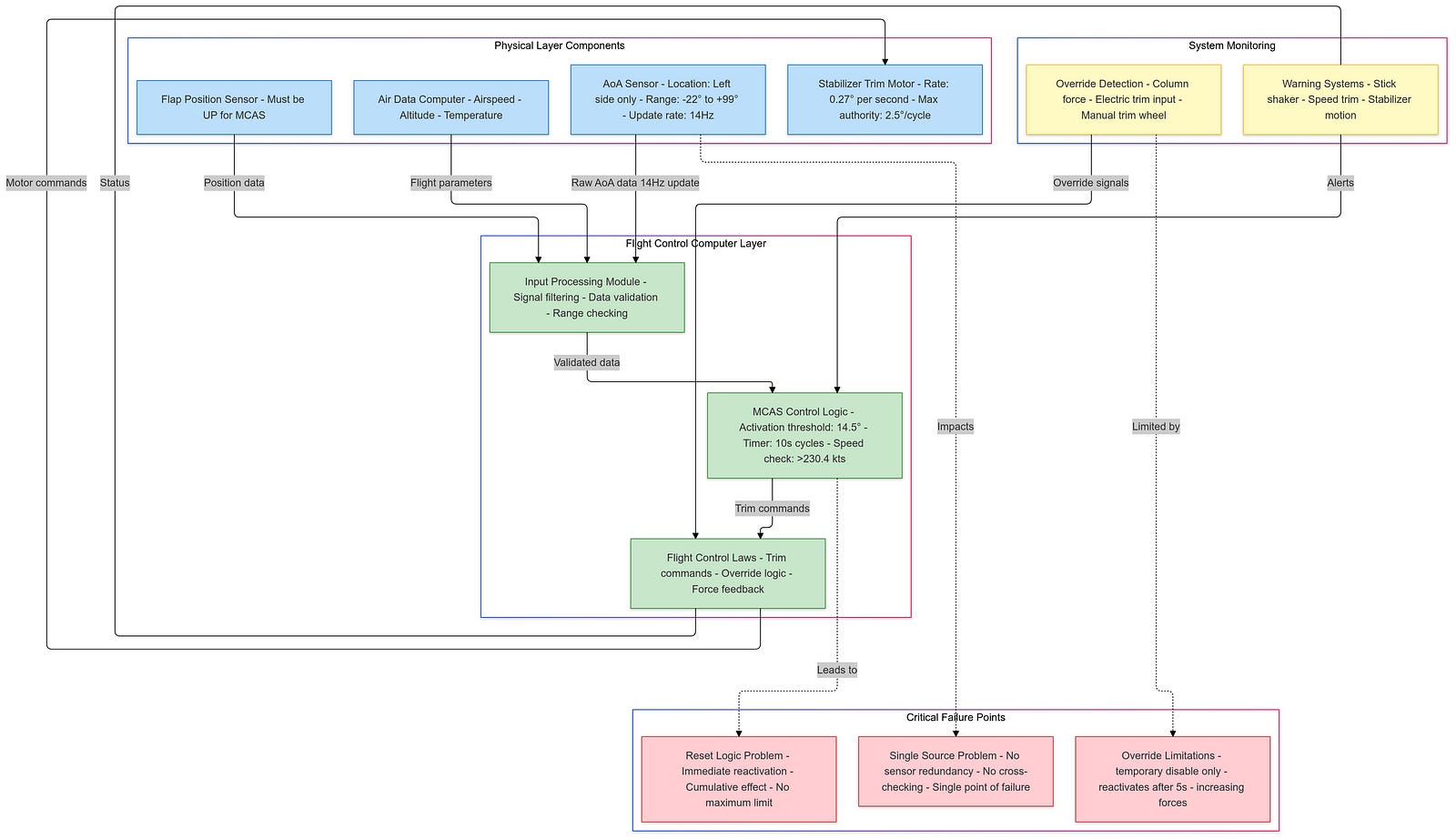
MCAS was introduced to mitigate the 737 MAX’s tendency to pitch up during certain flight conditions, particularly at low speeds. The system was designed to automatically push the nose of the aircraft down if it detected an imminent stall, using data from a single angle-of-attack (AoA) sensor. This reliance on a single sensor became a critical point of failure, as both crashes — Lion Air Flight 610 in October 2018 and Ethiopian Airlines Flight 302 in March 2019 — were attributed to erroneous readings from this sensor.
The design flaws within MCAS were multifaceted. Firstly, the system’s dependency on a single AoA sensor was a significant oversight, as it meant that if the sole sensor failed or provided incorrect data, MCAS could erroneously activate, pushing the aircraft into a nose-down position without pilot intervention. This lack of redundancy in a critical flight control system was a clear departure from standard aviation safety practices, which typically incorporate multiple redundancies to prevent catastrophic failures.
Additionally, pilots received insufficient training on how to handle situations involving MCAS activation. Initial training materials did not adequately cover the system’s functionality or potential malfunctions, leading to confusion during critical moments when pilots needed to regain control of their aircraft.
The operational failures further exacerbated the issues with MCAS. The AoA sensors used in the MAX were subject to failure due to environmental factors such as icing or physical damage, and maintenance teams often replaced sensors without fully understanding the underlying issues, which may have included wiring problems rather than sensor faults themselves. Moreover, the logic governing MCAS activation allowed it to make multiple adjustments in rapid succession without pilot input, potentially leading to a situation where pilots were unable to counteract MCAS commands effectively, resulting in a “death spiral” scenario where they lost control of the aircraft.
Even after the crashes, Boeing’s attempts to rectify MCAS through software updates, including limiting its authority and requiring input from both AoA sensors before activation, did not fully resolve the underlying issues related to responsiveness and pilot control during emergencies.
The technical failures associated with MCAS have had profound implications for Boeing as a company and for the aviation industry as a whole. The FAA faced intense scrutiny for its certification processes regarding the 737 MAX, with investigations revealing that safety issues had been overlooked during certification, raising questions about regulatory oversight and Boeing’s influence over safety assessments. Boeing’s reputation has suffered significantly, leading to loss of consumer trust and financial repercussions, including lawsuits from victims’ families and cancellations of orders for the MAX series as airlines reconsidered their fleet strategies.
Furthermore, reports of foreign object debris (FOD) found in fuel tanks of several MAX aircraft highlighted systemic issues within Boeing’s manufacturing processes and quality control measures, raising concerns about overall safety standards across all Boeing products.
The Boeing 737 MAX tragedy serves as a cautionary tale of the consequences of software flaws and design oversights in the aviation industry. It underscores the critical importance of incorporating redundancies, thorough testing, and comprehensive pilot training into the development and deployment of safety-critical systems. As the industry continues to embrace technological advancements, the lessons learned from this incident will be pivotal in shaping the future of aviation safety and ensuring that such tragedies are not repeated.
Microsoft Zune Freeze (2008)
In the mid-2000s, Microsoft launched the Zune as a direct competitor to Apple’s iPod, which had dominated the portable media player market since its introduction in 2001. The Zune was part of Microsoft’s broader strategy to establish a foothold in digital music and media consumption, leveraging its existing software ecosystem. Initially released in November 2006, the Zune aimed to differentiate itself through features such as wireless sharing, a subscription-based music service, and a social aspect that allowed users to share music with friends. Despite these innovations, the Zune struggled to capture significant market share against the established iPod brand, which was synonymous with digital music and had a loyal user base.The Zune’s launch was marked by considerable anticipation, as Microsoft sought to create an integrated experience that could rival Apple’s seamless ecosystem. However, the device faced challenges not only in terms of market competition but also in its software stability. The Zune’s software was designed to facilitate easy music sharing and access to a growing library of songs through the Zune Marketplace, but it was not without flaws.

Bug Description:
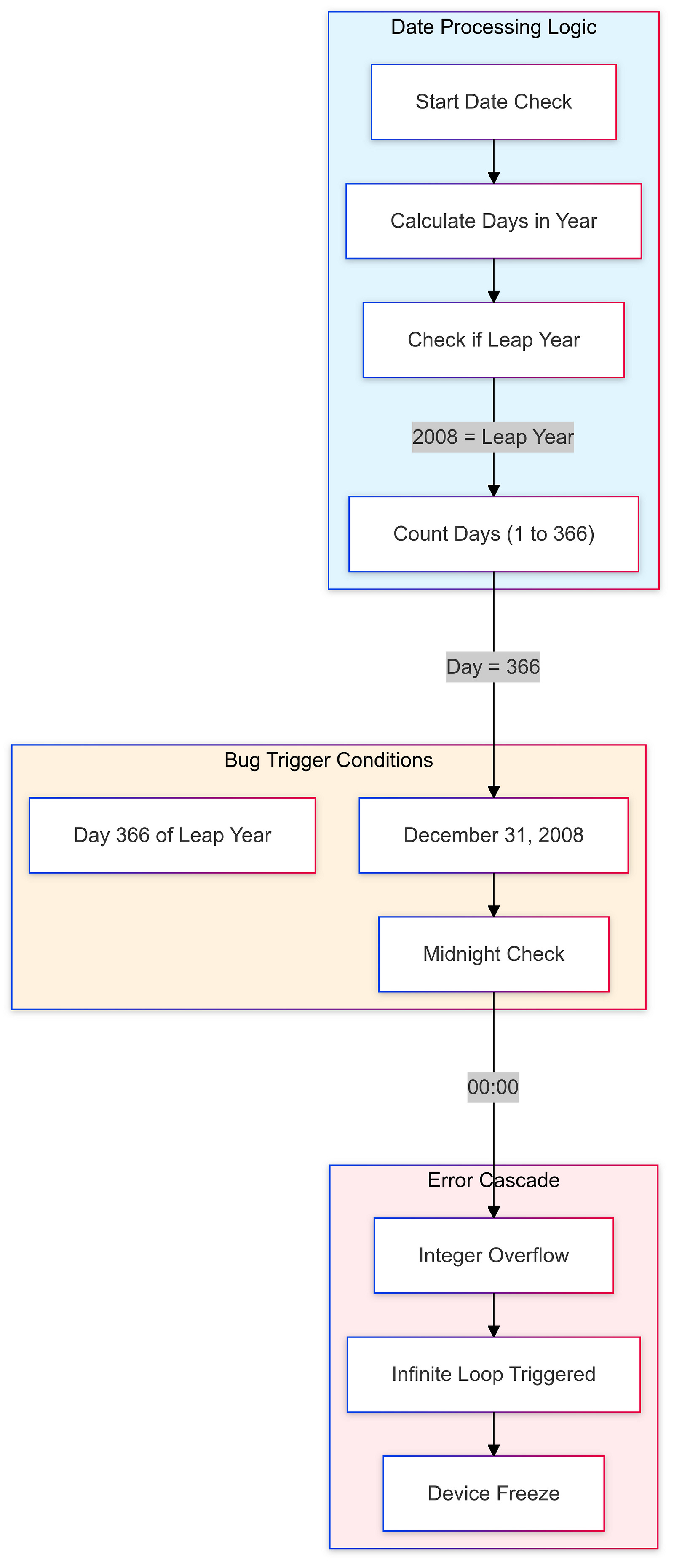
On December 31, 2008, a significant bug emerged that would become infamous in the history of technology mishaps: the “Zune freeze.” This issue was related to how the device’s firmware processed dates, particularly in relation to leap years. As the clock struck midnight on New Year’s Eve, every Zune device froze due to an error in handling the 366th day of the year. This bug rendered all units unresponsive, effectively locking users out of their devices until they performed a manual reset by removing the battery.The leap-year bug highlighted a critical oversight in Microsoft’s coding practices. The firmware failed to account for the additional day in leap years correctly, leading to widespread frustration among users. This incident not only disrupted the functionality of the devices but also raised questions about Microsoft’s quality assurance processes and their ability to deliver reliable software.
Impact:
The consequences of the Zune freeze were immediate and widespread. Every single Zune device worldwide experienced this failure simultaneously, creating a unique situation where users found themselves unable to access their music or use their devices on what many considered a celebratory occasion. The incident quickly gained media attention and became a topic of discussion across various platforms. Users took to social media and forums to express their frustrations, share their experiences, and seek solutions.The impact extended beyond just user inconvenience; it also tarnished Microsoft’s reputation in an already competitive market. The Zune had been struggling to gain traction against Apple’s iPod, and this incident served as a significant setback for Microsoft’s efforts to position itself as a serious contender in digital media. The freeze reinforced negative perceptions about Microsoft’s ability to produce consumer-friendly products and raised concerns about its software development practices.
Resolution:
In response to the backlash from users and media coverage surrounding the freeze incident, Microsoft quickly moved to address the issue. The company acknowledged the bug publicly and issued a statement explaining that they were working on a fix. While some users were able to resolve the problem temporarily by removing and reinserting their batteries, others had to wait for official guidance from Microsoft.Microsoft’s handling of this situation became a moment of embarrassment for the company. It underscored the importance of rigorous testing and quality assurance in software development — especially for products that rely heavily on accurate date and time functions. The incident served as a cautionary tale for developers about accounting for leap years and other edge cases in code.Ultimately, Microsoft released an update that corrected the bug shortly after New Year’s Day 2009. However, this mishap left an indelible mark on the Zune’s legacy. It became emblematic of broader issues within Microsoft at that time — issues related to product reliability and user experience that would haunt them as they continued to compete with Apple.The Zune freeze incident also sparked discussions within tech circles about software reliability and consumer expectations. Users began demanding more accountability from tech companies regarding product performance and reliability. This event highlighted how critical it is for companies like Microsoft to ensure their products are thoroughly tested before launch, particularly when competing against established brands known for their polished user experiences.In conclusion, while Microsoft’s Zune aimed to innovate within the digital music space by introducing features like wireless sharing and subscription services, it was ultimately marred by significant software failures such as the leap-year bug on December 31, 2008. This incident not only affected user trust but also illustrated broader lessons about software development practices that remain relevant today. As technology continues to evolve, ensuring robust performance across all scenarios — including leap years — remains essential for maintaining consumer confidence and satisfaction in an increasingly competitive landscape.
The Pentium FDIV Bug: A Cautionary Tale in Hardware Reliability
In the early 1990s, Intel’s Pentium microprocessor stood as a milestone in computing technology, promising enhanced performance and capabilities. As the ubiquitous processor powering personal computers and high-stakes computing environments, the Pentium’s reliability was paramount. The chip was essential for scientific research, engineering calculations, and financial modeling, where even the slightest errors could lead to significant financial losses or critical failures in R&D projects. The introduction of the Pentium, therefore, marked a significant advancement in the microprocessor industry, with users expecting flawless operation.
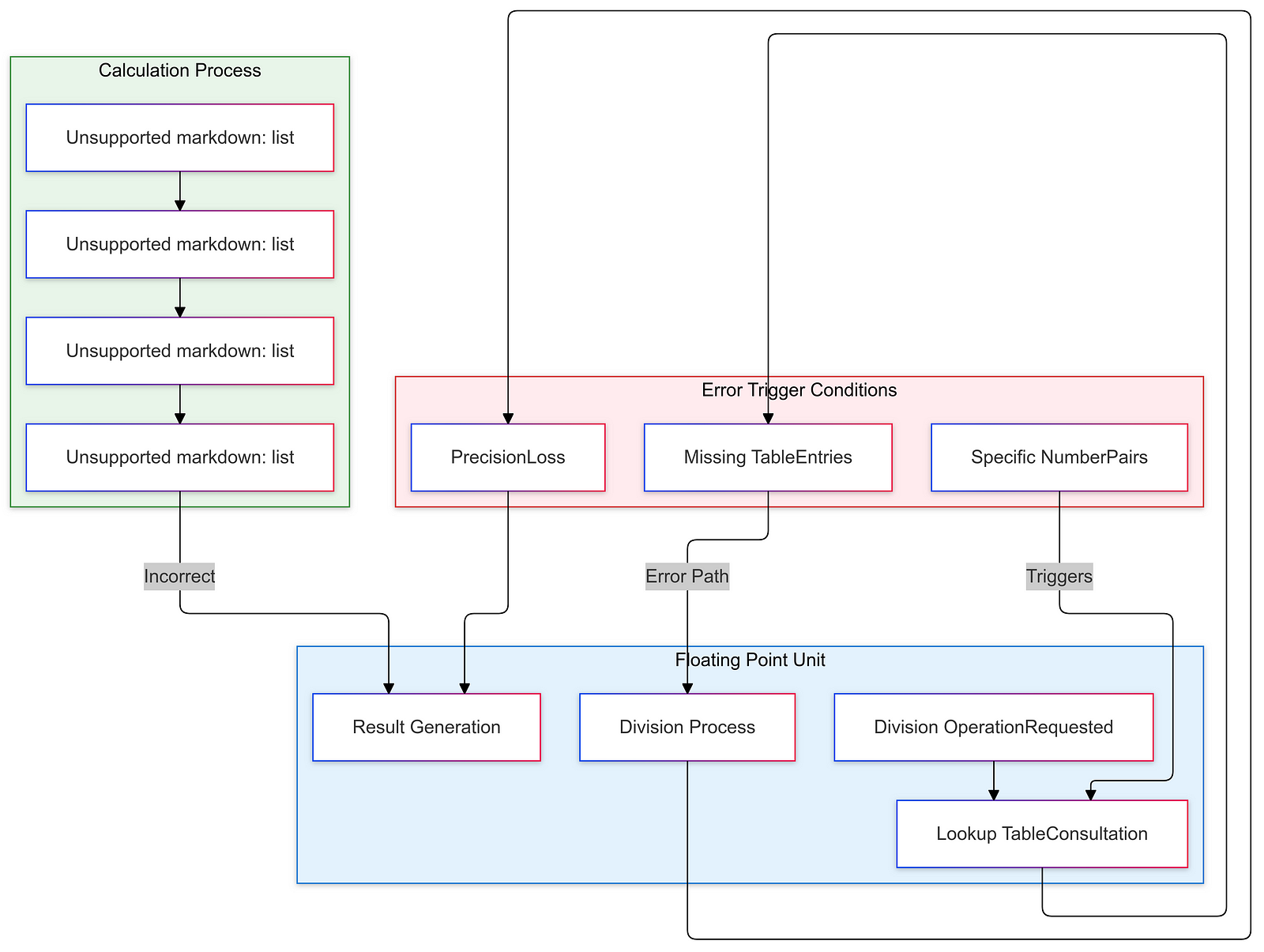
However, this promise was soon overshadowed by a severe flaw that would challenge Intel’s reputation and operational integrity. The Pentium FDIV bug emerged as a rare, yet critical, floating-point division error associated with the processor’s arithmetic logic unit (ALU). This error was traced back to missing entries in a lookup table used for floating-point calculations. Specifically, when the processor attempted to perform certain division operations, it would occasionally produce incorrect results.
The Pentium’s floating-point division unit was responsible for performing complex mathematical operations, such as those required in scientific and engineering applications. The FDIV bug manifested under specific conditions, primarily when dividing certain pairs of floating-point numbers. This led to inaccuracies that could be catastrophic in contexts requiring high precision, such as simulations, critical system designs, and financial modeling.
Intel initially downplayed the significance of this bug, asserting that it occurred infrequently and primarily affected complex mathematical computations. The company estimated the odds of encountering the error to be approximately 1 in 9 billion for typical consumer use cases. However, this assertion did not resonate well with users who relied on precise calculations for their work.
As reports began to surface from users, particularly in academia and engineering fields, detailing instances where the bug led to erroneous results, the situation escalated from a technical issue to a public relations crisis. The impact of the FDIV bug was profound despite its rarity. It primarily affected users engaged in scientific research and engineering calculations — fields where accuracy is non-negotiable.
For instance, researchers conducting simulations or engineers designing critical systems could find their results compromised by this flaw. The potential for incorrect outputs raised alarms across industries reliant on computational accuracy. Major corporations that relied on Intel processors began reassessing their dependency on these chips, fearing that similar flaws could emerge in future products.
The technical details of the FDIV bug reveal the importance of meticulous design and testing in microprocessor development. The issue was rooted in the processor’s floating-point division logic, which is a crucial component for many scientific and engineering applications. The problem arose due to missing entries in a lookup table used by the ALU during floating-point division operations.
Lookup tables are a common optimization technique in microprocessor design, as they can streamline complex calculations by providing precomputed results. However, the Pentium’s lookup table for floating-point division had a flaw, leading to incorrect results in certain cases. This highlights the complexity of modern processor design and the need for comprehensive testing to identify and address even the most obscure bugs.
The fallout from the FDIV bug extended beyond technical implications; it became a case study in crisis management for tech companies. Intel faced intense scrutiny from media outlets and industry analysts who questioned its transparency and responsiveness to consumer concerns. This situation exemplified how even a single hardware flaw could escalate into a full-blown crisis, affecting not just sales but also corporate reputation.
As news of the bug spread, it ignited widespread concern among consumers and businesses alike. Many users felt betrayed by Intel’s initial dismissal of the issue as minor, leading to a significant erosion of trust in the company’s commitment to quality and reliability. This erosion of trust was particularly damaging, as the Pentium was a mission-critical component in many industries, and users relied on Intel’s reputation for dependability.
In response to mounting pressure from customers and media scrutiny, Intel ultimately reversed its initial stance regarding the FDIV bug. In December 1994, after weeks of resistance, the company announced it would offer free replacements for affected Pentium chips. This decision came after significant public outcry and criticism of Intel’s handling of the situation; many viewed its earlier reluctance to acknowledge the problem as arrogant.
Intel’s CEO, Andrew Grove, publicly apologized for the company’s mishandling of the issue during a press conference. He acknowledged that Intel had underestimated consumer expectations and failed to recognize that even minor bugs could have severe implications for users relying on their technology for critical applications. The company committed to replacing millions of flawed chips at an estimated cost of up to $1 billion — a staggering figure that highlighted both the financial repercussions of hardware bugs and the importance of maintaining customer trust.
The logistics surrounding this recall were daunting. Intel had to coordinate with various PC manufacturers who had integrated Pentium chips into their systems. This involved not only replacing chips but also managing customer communications effectively to ensure users understood their options and rights regarding replacements.
Despite these challenges, Intel’s proactive approach helped mitigate some damage to its reputation over time. By taking responsibility and addressing consumer concerns directly, Intel managed to restore some level of trust among its customer base. However, the incident served as a cautionary tale about the potential consequences of hardware flaws in an increasingly competitive market.
The Pentium FDIV bug highlighted the importance of comprehensive testing and validation in microprocessor development. In the aftermath, Intel and the broader tech industry recognized the need for more rigorous quality assurance processes to identify and address even the most obscure bugs before they reach the market.
From a technical perspective, the FDIV bug underscored the complexity of modern processor design and the importance of meticulous attention to detail. The issue was rooted in the floating-point division logic, a critical component for many scientific and engineering applications. The problem arose due to missing entries in a lookup table used by the ALU during floating-point division operations.
Lookup tables are a common optimization technique in microprocessor design, as they can streamline complex calculations by providing precomputed results. However, the Pentium’s lookup table for floating-point division had a flaw, leading to incorrect results in certain cases. This highlights the need for comprehensive testing and validation, as even minor oversights in the design of such critical components can have far-reaching consequences.
In the aftermath of the FDIV bug, Intel and the broader industry implemented more rigorous testing protocols to identify and address hardware flaws before they reach the market. This included expanding test suites to cover a wider range of edge cases, such as rare floating-point division operations, as well as implementing more sophisticated simulation and emulation tools to uncover potential issues.
Additionally, the incident prompted greater transparency and communication between technology companies and their customers. Intel’s initial reluctance to acknowledge the FDIV bug and its potential impact ultimately backfired, leading to a significant erosion of trust. In response, Intel and other tech firms recognized the importance of proactive communication and customer engagement in addressing hardware issues, even if the problems are relatively rare.
The Pentium FDIV bug serves as a powerful example of how a single hardware flaw can have far-reaching consequences, both in terms of financial impact and reputational damage. The incident underscored the critical importance of reliability and accuracy in mission-critical computing applications, as well as the need for robust quality assurance processes and transparent communication with customers.
As the technology industry continues to push the boundaries of processor design and performance, the lessons learned from the Pentium FDIV bug remain highly relevant. Maintaining the trust of customers and users who rely on the integrity of computing systems is paramount, and tech companies must be vigilant in their efforts to identify and address even the most obscure hardware flaws before they can cause significant harm.
The FaceTime Eavesdropping Bug: A Technical Breakdown
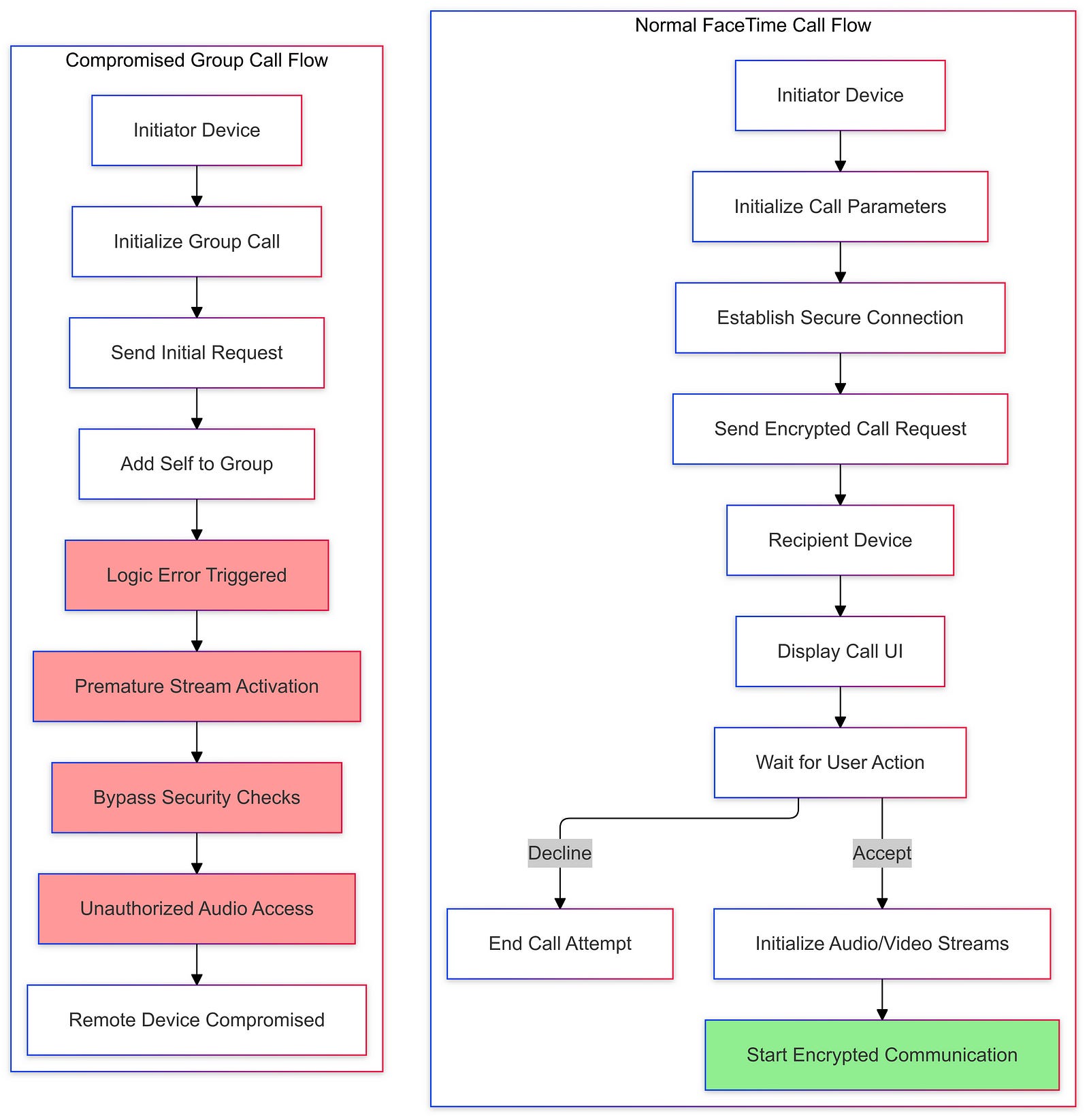
The FaceTime eavesdropping bug was a critical flaw in Apple’s popular video calling service that allowed users to exploit the group calling feature in a troubling manner. The technical details of this bug reveal a complex issue in the way the FaceTime app handled audio streams during group calls.
When a user added themselves to an ongoing group call, the system inadvertently began transmitting audio from the recipient’s device before they had accepted the call. This vulnerability arose due to a failure in the FaceTime app’s ability to properly validate and manage the audio streams from multiple participants.
Typically, in a group FaceTime call, the app would establish a secure, encrypted connection between the initiator and each participant. However, the bug introduced a vulnerability in this process, allowing the initiator to access the audio from the other participants without their knowledge or consent.
The root cause of the bug was a logic error in the FaceTime app’s group call implementation. The app failed to properly verify the user’s participation and obtain consent before enabling audio transmission. This allowed the initiator to bypass the necessary security checks and eavesdrop on the conversation.

To address the issue, Apple’s engineering team had to identify the specific logic flaw and implement a fix that would restore the intended security and privacy protections. This likely involved modifying the app’s call handling logic to ensure that audio streams are only enabled after proper participant verification and consent is obtained.
Additionally, Apple likely implemented more robust testing and validation procedures to detect such vulnerabilities in the future. This may have included expanding test cases to cover edge cases and unexpected user interactions, as well as implementing more stringent code reviews and static analysis tools to identify potential security risks.

The FaceTime eavesdropping bug highlighted the importance of rigorous testing and validation in the development of secure communication platforms. As communication tools become increasingly integrated into our daily lives, even minor vulnerabilities can have far-reaching consequences, undermining user trust in the security and privacy of their digital interactions.
Moving forward, the lessons learned from this incident will likely shape the way Apple and other tech companies approach the development and maintenance of secure communication tools, emphasizing the need for increased transparency, proactive vulnerability testing, and prompt response to reported issues.
The Chase ATM Glitch: A Breakdown of the Technical Vulnerabilities
In September 2024, a significant issue in the banking system at Chase ATMs came to light, sparking widespread media attention and public outrage. This incident involved a viral trend that promised users the ability to withdraw large sums of money immediately after depositing fake checks. The core of the problem stemmed from a failure in the ATM software to enforce proper waiting periods for the clearance of deposited checks.
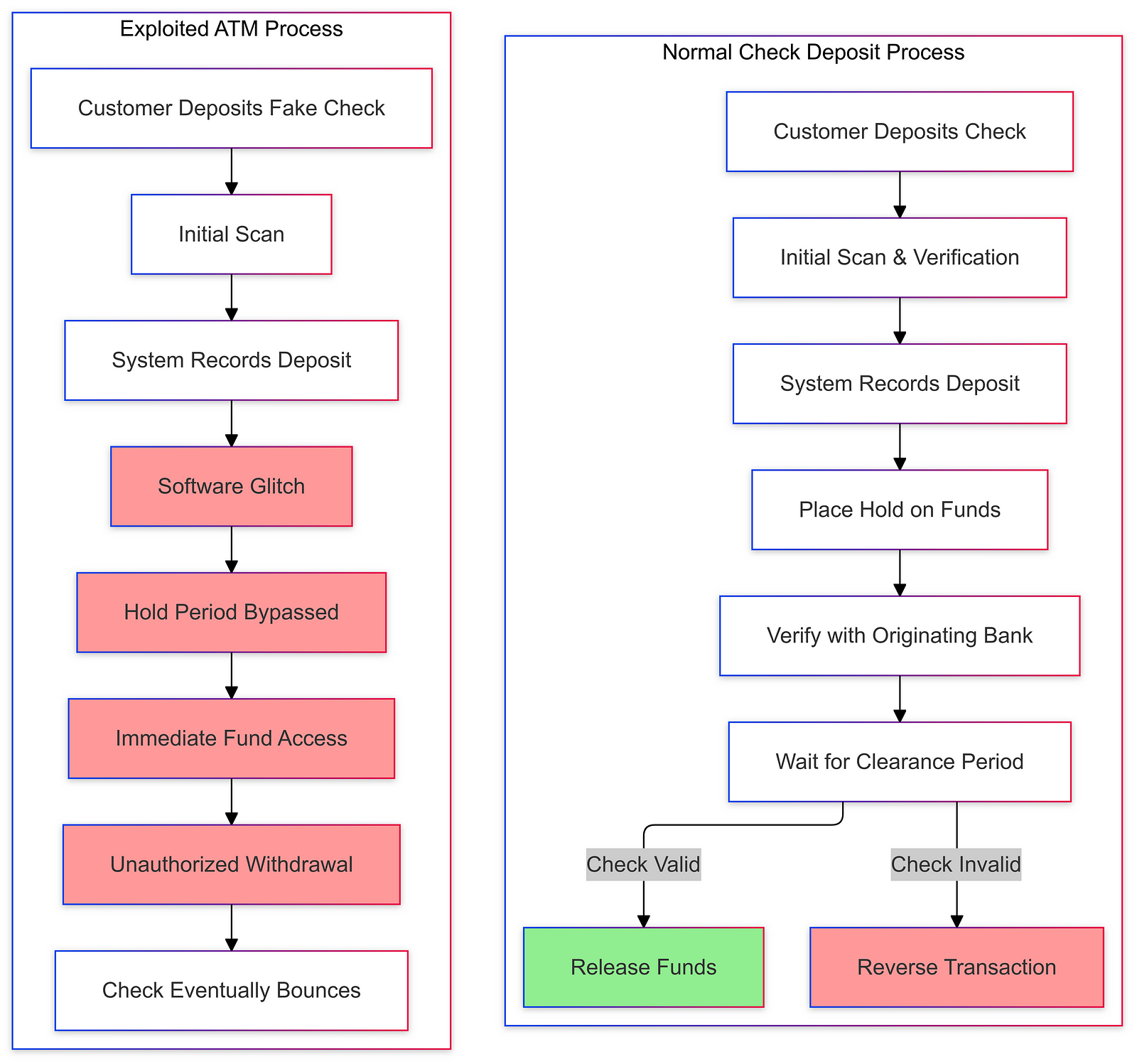
Typically, banks hold deposited checks for a certain period to ensure that the funds are available and legitimate. However, in this case, the ATM systems at Chase allowed users to withdraw funds immediately after depositing checks that would later bounce. This loophole exploited the banking practice of making a portion of deposited funds available before full verification.
The root cause of this glitch was a flaw in the software running on the Chase ATMs. The ATM’s check processing program failed to properly implement the necessary safeguards to prevent the immediate withdrawal of funds for uncleared deposits. This software vulnerability allowed users to circumvent the standard banking protocols and access cash that they did not rightfully have access to.
Typically, when a check is deposited, the banking system undergoes a multi-step process to verify the legitimacy of the funds. This includes communicating with the originating bank, confirming the availability of the balance, and placing a temporary hold on the deposited funds until the check clears. However, the Chase ATM software failed to enforce this process correctly, enabling users to bypass these essential security measures.
The technical failure occurred in the ATM’s check clearing module, which is responsible for managing the deposit and withdrawal of funds. This module should have been programmed to place a hold on the deposited funds, preventing their immediate withdrawal until the check had been fully cleared. However, a flaw in the code allowed the module to erroneously release the funds to the user, even though the underlying check was fraudulent.

This vulnerability was likely the result of inadequate testing and quality assurance procedures within the ATM software development lifecycle. The Chase engineering team responsible for maintaining the ATM systems should have implemented more rigorous testing scenarios to identify and address potential security weaknesses, particularly around edge cases involving check deposits and withdrawals.
Additionally, the bank’s overall system architecture and integration between the ATM software and the broader banking infrastructure may have contributed to the issue. If the communication between the ATM and the bank’s central systems was not properly designed and secured, it could have allowed for the exploitation of this vulnerability.
To resolve the problem, Chase Bank quickly patched the system vulnerabilities that enabled this exploit. This likely involved updating the check clearing module to enforce stricter verification and hold procedures, ensuring that deposited funds are not immediately available for withdrawal until their legitimacy is confirmed.
Furthermore, Chase likely conducted a comprehensive review of its ATM software and banking systems to identify and address any other potential weaknesses that could be exploited. This may have included implementing more robust logging and monitoring mechanisms to detect suspicious activity, as well as improving the overall security and resilience of the bank’s technology infrastructure.
The Chase ATM glitch serves as a cautionary tale about the importance of rigorous software development practices, particularly in the financial sector, where the consequences of security vulnerabilities can be severe. As technology continues to advance and banking systems become more interconnected, it is crucial for financial institutions to prioritize the security and reliability of their software to protect both their customers and their own operations from exploitation.
The AT&T Network Crash: A Case Study in Software Reliability
On January 15, 1990, AT&T’s long-distance network, a crucial component of American telecommunications, experienced a catastrophic failure that disrupted services nationwide. At the time, AT&T was the dominant provider of long-distance telephone services in the United States, handling over 70% of the nation’s traffic and routing approximately 115 million calls daily through its advanced electronic switching systems.
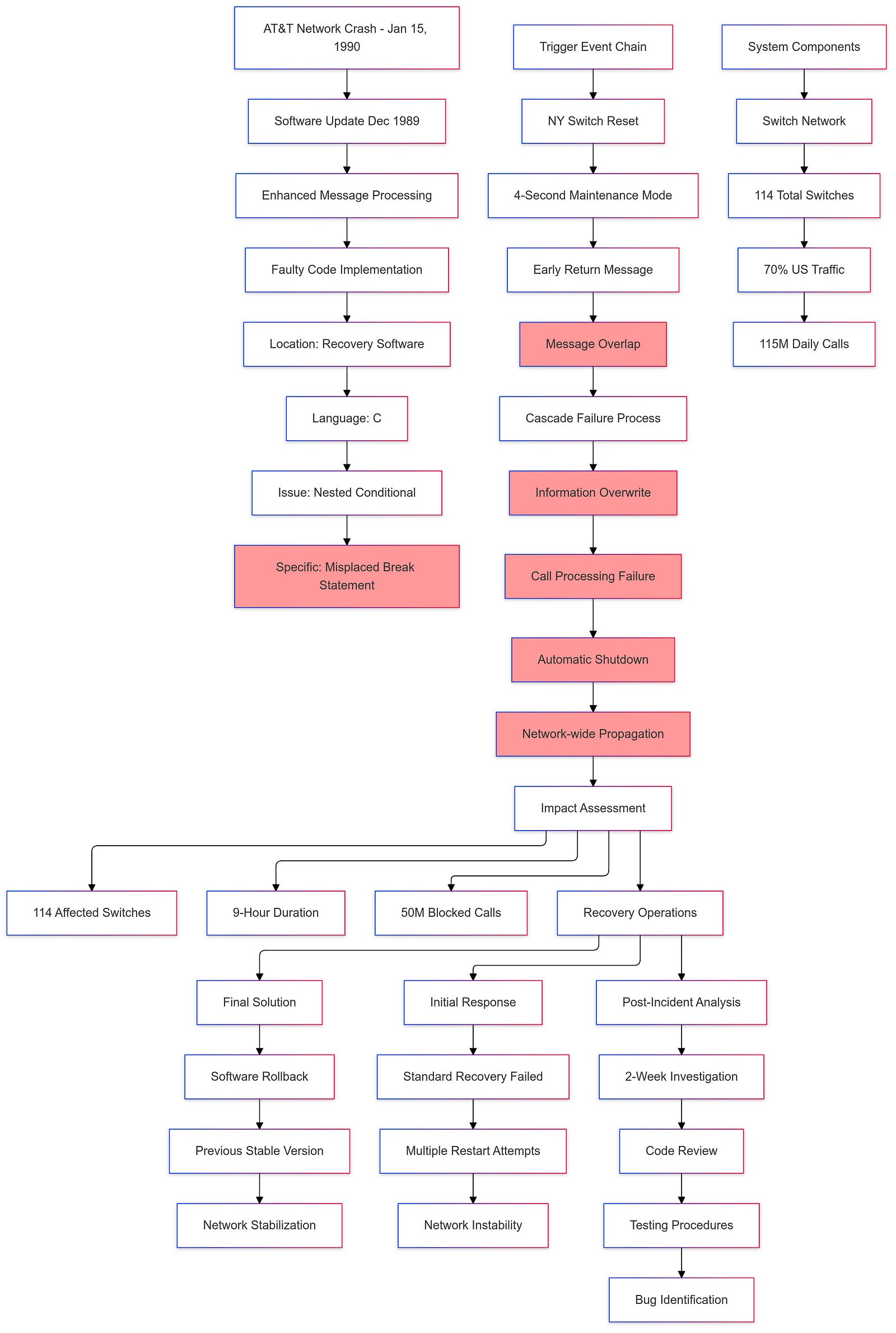
The source of the problem was traced back to a software update that had been implemented in December 1989. This update was intended to enhance the processing speed of certain types of messages across the network. Despite rigorous testing prior to deployment, a critical bug — a single faulty line of code — was introduced into the recovery software used by all 114 switches within AT&T’s network.
The technical details of the failure reveal the complexity and interconnectedness of the AT&T network. When the New York switch performed a routine maintenance reset, it sent out a message indicating it would not accept new calls for approximately four seconds. However, during this time, another message arrived from the switch indicating it was back online. Due to the software defect, this second message overwrote crucial communication information from the first message, leading to a failure in processing incoming calls and initiating an automatic shutdown of the switch.
This initial failure triggered similar responses in other switches across the network. Each affected switch began to reset itself upon detecting overlapping messages, creating a cascading effect that propagated throughout AT&T’s entire system. In total, approximately 50 million calls were blocked during this nine-hour outage.
