

From Twitter Sentiments to Stock Market Insights
Harnessing Financial Data: A Comprehensive Guide

In the rapidly evolving world of finance, leveraging data from diverse sources like social media and financial markets has become crucial. This guide delves into the intricate process of extracting and analyzing data from Twitter and stock market sources, providing a comprehensive approach to understanding market sentiments and trends. The methodology involves gathering tweets related to specific financial instruments and stock data from platforms like Yahoo Finance, showcasing the power of social media analytics in financial decision-making. This fusion of social media sentiment with hard financial data opens up new avenues for investors and analysts to gauge market moods and make informed decisions.
Central to our approach is the use of various Python libraries and packages, each serving a unique purpose in the data processing pipeline. For instance, Tweepy is employed for Twitter API interactions, enabling the retrieval of relevant tweets, while Newspaper3k aids in extracting publication dates of financial news articles. The integration of these tools facilitates the collection, cleaning, and analysis of vast datasets, transforming raw data into actionable insights. Furthermore, sophisticated natural language processing techniques are applied to summarize news content and analyze tweet sentiments, which are then correlated with stock market data to generate comprehensive market insights. This guide offers a detailed walkthrough of this multifaceted process, empowering readers with the knowledge to harness the synergy between social media and financial market data.
We install all the necessary packages to build the model
!pip install glomTo easily install the glom Python package, run !pip install glom in a Python environment like a Jupyter notebook or comm-line interface. This comm executes pip as a system comm downloads the latest version of glom from PyPI, making it available for use in the current environment.
!pip install yfinanceTo install the ‘yfinance’ library for Python, run this comm to prompt the pip installer to download install the latest version from the Python Package Index (PyPI) or other configured repositories. This allows users to access a range of financial data from Yahoo Finance for their programs.
!pip install newspaper3kUse this comm to install the Python library ‘newspaper3k’, a tool for extracting curating articles from the web. It will instruct pip to download install the package from PyPI into your Python environment, allowing you to perform tasks like scraping news articles conducting natural language processing.
!pip install bs4To install the Python package BeautifulSoup 4 (bs4) for parsing HTML XML documents, run the following comm in a Jupyter notebook or similar environment using pip: !pip install bs4. This will automatically download install bs4 from the Python Package Index (PyPI) or another configured source. Once installed, bs4 can be used in Python to extract data from web pages.
import nltk
nltk.download('punkt')
nltk.download('stopwords')
This Python code snippet uses NLTK for natural language processing. When run, it will download ‘punkt’ ‘stopwords’ packages, which help tokenize remove meaningless words from texts. These steps are necessary for text analysis in Python.
Importing Packages
Import packages for performing data extraction, cleaning, visulaization, and modelling
import tweepy, jsonThis code utilizes the tweepy json libraries to interact with Twitter’s API in a Python script. With authentication, it can post, read, follow on behalf of a user. Additional code is needed for specific actions.
from glom import glomThe glom module in Python allows for easy nested data extraction manipulation. First, import the glom function from the module, then specify a target data structure a spec to retrieve or transform data. The glom function will traverse the target return the result. The code snippet does not include an actual invocation of the function, it simply imports it for later use.
import numpy as npThis Python code imports the NumPy library its numerical computing capabilities. By using import numpy as np, all features from NumPy are loaded into the script easily accessible through the alias np.
import pandas as pdUse this one-liner in Python to import the pas library assign it to the alias ‘pd’. This library has functions data structures specifically for working with structured data like spreadsheets CSV files. Place this code at the beginning of your script or notebook to use pas’ features throughout the rest of your code.
Collecting Twitter Data
Acquiring developer credentials from Twitter to retrieve past tweets, spanning a period of up to 7 days.
IMPORTANT: The keys provided below are confidential. They must be handled with discretion and should not be utilized inappropriately without the explicit permission of the key owner.
api_key = "D3a1PVON8wECC8ZB781LXEY0I"
api_secret_key = "lrrXjpTn0P2Rj1R1lH3cVn1KUA4xrTZyrRzb9Jfgwx1bKPC5Y2"
access_token = "1319681101-suDjXaeuUGiCMVoQ3ZHmwIv84CNkXbkvuSE39JK"
access_token_secret = "IvLRZh7i2PaxmXr4riVb7QZoLBOzqS3MJfDEEq9nX9oYU"The code snippet contains four lines that declare assign variables for authentication. api_key api_secret_key are app credentials, while access_token access_token_secret are user-level access keys. These keys form necessary credentials for OAuth authentication with APIs, allowing the app to make requests on behalf of the user while protecting their password.
auth = tweepy.OAuthHandler(api_key,api_secret_key)
auth.set_access_token(access_token,access_token_secret)
api = tweepy.API(auth)This code is for authenticating with the Twitter API using Tweepy for Python. Credentials are provided by Twitter used to create an OAuth hler object, which starts the authentication process. The next line sets the access tokens, also provided by Twitter, for a specific user. Lastly, a Tweepy API object is created to communicate with the Twitter API perform actions such as tweeting managing users.
def get_tweets(ticker_list, count):
tweets = pd.DataFrame()
for i in range(len(ticker_list)):
results = api.search(q=ticker_list[i], lang='en', count=count)
results = pd.DataFrame(results)
temp = pd.DataFrame()
temp['Timestamp'] = results[0].apply(lambda row: glom(row, 'created_at'))
temp['Title'] = results[0].apply(lambda row: glom(row, 'text'))
temp['Ticker'] = ticker_list[i]
temp['Tweet ID'] = results[0].apply(lambda row: glom(row, 'id'))
temp['User ID'] = results[0].apply(lambda row: glom(row, 'user.id'))
temp['Name'] = results[0].apply(lambda row: glom(row, "user.screen_name"))
temp['Followers'] = results[0].apply(lambda row: glom(row, 'user.followers_count'))
temp['Location'] = results[0].apply(lambda row: glom(row, 'user.location'))
tweets = tweets.append(temp)
tweets.drop_duplicates(inplace=True)
return tweetsThe get_tweets function retrieves tweets related to financial tickers organizes them into a DataFrame. It takes in a list of ticker symbols a count of tweets to retrieve per ticker. First, an empty DataFrame is initialized. Then, the function calls the Twitter API to fetch tweets matching the ticker symbols in English, up to the specified count. The results are converted into a new DataFrame, with details such as timestamp, text, ticker symbol, tweet ID, user ID, username, follower count, location extracted. The information is organized into a temporary DataFrame then appended to the empty DataFrame. Finally, duplicate records are removed the populated DataFrame is returned.
The list of tickers encompasses all stock names within the NIFTY Bank.
Any tweets featuring these specified keywords are collected.
ticker_list = ["NIFTY BANK", 'SBIN', 'IDBI', 'AXISBANK', 'HDFCBANK', 'KOTAKBANK', 'PNB', 'ICICIBANK', 'BARODA', 'CANARA', 'INDUSIND', 'BANKINDIA', 'UNION']
count = 1000
tweets = get_tweets(ticker_list=ticker_list, count=count)This code gathers 1000 tweets about certain banks financial institutions. It stores the tweets in a variable called tweets after passing a list of bank tickers the number 1000 as arguments to the get_tweets function. This is likely used for analyzing social media sentiment or market trends related to these financial entities.
def firstandlastdate(dataframe):
first = np.min(dataframe['Timestamp'])
last = np.max(dataframe['Timestamp'])
return first, lastThis function, firstlastdate, finds the earliest latest dates in a dataframe’s ‘Timestamp’ column. It takes in one argument — dataframe, which is a table of data organized in rows columns. Using a function from the numpy library, it calculates the minimum maximum values in the ‘Timestamp’ column stores them in variables named first last. These values are then returned for use in other code. This function essentially extracts the date or time range in a dataset.
first_tw, last_tw = firstandlastdate(tweets)
print('Starting: '+str(first_tw) +'\n' +'Ending: '+str(last_tw))
This code finds the first last dates from a collection of tweets. It concatenates them into a message, which is then printed. The message shows the timeline of the tweets.
tweets.info()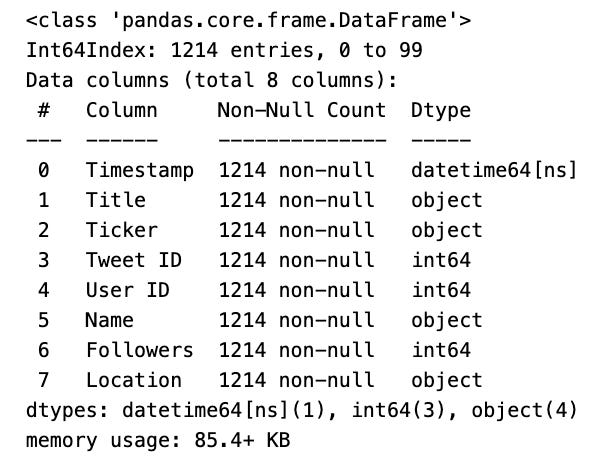
To quickly underst a pas DataFrame called tweets, use info() to display a summary of its structure, including column names, data types, number of non-null values. This helps with data cleaning transformation.
Extracting News
Functions have been developed for the purpose of navigating webpages to gather URLs, subsequently filtering these URLs, and then processing them through a data extraction algorithm to obtain news information.
def search_for_stocks_news_urls(ticker, url_list):
for url in url_list:
search_url = url.format(ticker)
r = requests.get(search_url)
soup = BeautifulSoup(r.text, 'html.parser')
atags = soup.find_all('a')
hrefs = [tag['href'] if tag.has_attr('href') else '' for tag in atags]
return hrefsThis function, search_for_stocks_news_urls, takes a stock ticker symbol a list of URL templates. It uses the ticker symbol to create search URLs fetches webpage content. Using BeautifulSoup, a library for parsing documents, it gathers URLs related to the stock from the parsed content returns them in a list.
def strip_unwanted_urls(urls, exclude_list):
val = []
for url in urls:
if 'https://' in url and not any(exclude_word in url for exclude_word in exclude_list):
res = re.findall(r'(https?://\S+)', url)[0].split('&')[0]
val.append(res)
return list(set(val))strip_unwanted_urls function takes two arguments, urls, exclude_list. It checks each URL from the urls list, if it starts with https:// does not contain words from exclude_list, it isolates the HTTPS URL removes any parameters. Finally, it returns a list of unique HTTPS URLs without the excluded words.
The Newspaper3k package is solely utilized for determining the publication date of each extracted article.
def publish_date(URLs):
publishdate = []
for url in URLs:
try:
publishdate.append(str(find_date(url)))
except:
publishdate.append("None")
pass
return publishdateThe function publish_date takes a list of URLs returns a list of publishing dates. It calls the function find_date(url) for each URL, converting the date into a string before adding it to the list. If an error occurs, None is added to the list.
def get_news_data(ticker_list, cleaned_urls):
articles_info = []
for ticker in ticker_list:
links = cleaned_urls[ticker]
for i in links:
article_dict = {}
article = Article(i)
article.download()
article_dict["link"] = i
article_dict["Ticker"] = ticker
try:
article.parse()
article_dict["Text"] = article.text
article_dict["Title"] = article.title
article.nlp()
except ArticleException:
article_dict["Text"] = np.nan
article_dict["Title"] = np.nan
articles_info.append(article_dict)
news_data = pd.DataFrame(articles_info)
return news_dataThis function, get_news_data, gathers news articles’ data for a given list of stock tickers their corresponding URLs returns it in a pas DataFrame. It takes two arguments: a list of ticker symbols (ticker_list) a dictionary mapping those symbols to their URLs (cleaned_urls). After initializing an empty list (articles_info), the function goes through each ticker’s URLs, creates a dictionary to store article information, downloads the content using the Article class, attempts to extract the text title using text parsing methods. The function then applies natural language processing techniques adds the article information to the articles_info list. Once all articles have been processed, the function converts this list into a well-organized DataFrame returns it.
ticker_list = ["NIFTY BANK", 'SBIN', 'IDBI', 'AXISBANK', 'HDFCBANK', 'KOTAKBANK', 'PNB', 'ICICIBANK', 'BARODA', 'CANARA', 'INDUSIND', 'BANKINDIA', 'UNION']
url_list = ["https://www.google.com/search?q={}&tbm=nws"]
raw_urls = {ticker:search_for_stocks_news_urls(ticker=ticker, url_list=url_list) for ticker in ticker_list}The code creates a dictionary named raw_urls with stock tickers corresponding news URLs. It uses a Google search URL template a function search_for_stocks_news_urls to get the news URLs for each ticker from Google News search results.
links = []
for ticker in ticker_list:
print('Number of URLs in '+ticker + ': '+str(len(raw_urls[ticker])))
for link in raw_urls[ticker]:
links.append(link)
print('Total number of raw URLs: '+str(len(links)))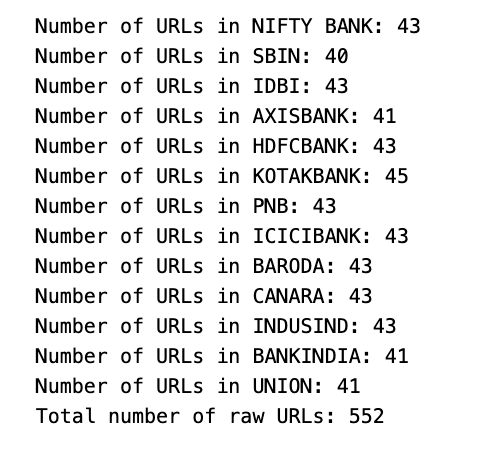
The code analyzes data for URLs associated with stock tickers. It creates an empty list called links loops through a list of tickers named ticker_list. For each ticker, the code prints the number of associated URLs from the raw_urls dictionary. Then, it appends all the URLs to the links list. Finally, the code displays the total count of extracted URLs from all tickers.
exclude_list = ['maps', 'policies', 'preferences', 'accounts', 'support']
cleaned_urls = {ticker:strip_unwanted_urls(raw_urls[ticker], exclude_list) for ticker in ticker_list}A dictionary called cleaned_urls stores values associated with ‘tickers’. It’s populated using a dictionary comprehension, using ticker_list as an iterable. For each ticker, the strip_unwanted_urls function is used to remove unwanted URLs from raw_urls[ticker] using the exclude_list of keywords. The result is a cleaned_urls entry for each ticker with a list of filtered URLs.
links = []
for ticker in ticker_list:
print('Number of URLs in '+ticker + ': '+str(len(cleaned_urls[ticker])))
for link in cleaned_urls[ticker]:
links.append(link)
print('Total number of cleaned URLs: '+str(len(links)))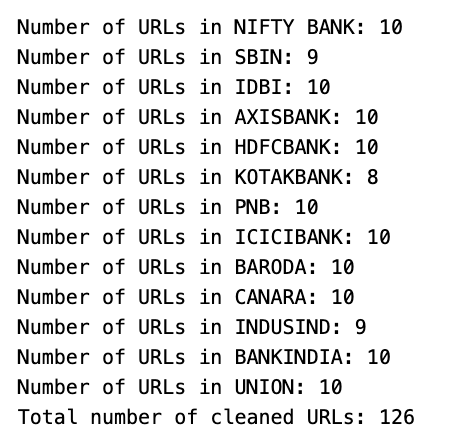
This code processes URLs for financial tickers by iterating through a list appending them to a links list. It also displays a message with the total count of URLs collected for each ticker.
articles_publishdate = {ticker:publish_date(cleaned_urls[ticker]) for ticker in ticker_list}
articles_publishdate
This code creates the articles_publishdate dictionary by iterating over the ticker_list using the publish_date function with the corresponding cleaned URL for each ticker. It then stores this dictionary in the variable articles_publishdate.
dates = []
for ticker in ticker_list:
count = 0
for value in articles_publishdate[ticker]:
if value != "None":
count = count + 1
print('Number of URLs in '+ticker + ' with dateofpub: '+str(count))
for date in articles_publishdate[ticker]:
dates.append(link) 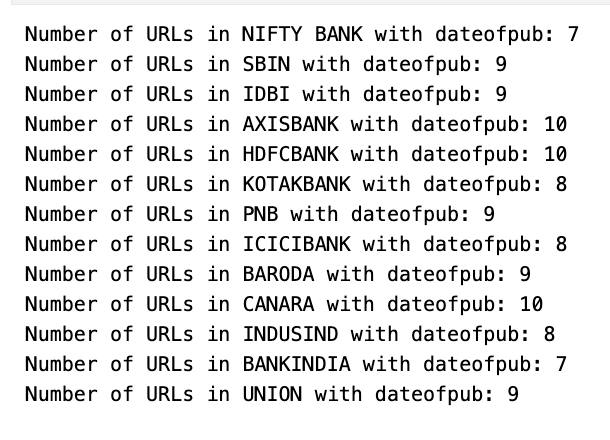
This code counts valid publication dates for stock tickers. It initializes a list iterates over a ticker list. Inside a nested loop, it increments a count variable if a valid date is found. It then prints the ticker count. There is potential for error in the provided snippet. The end result is a count for each ticker’s publication dates.
news_data = get_news_data(ticker_list=ticker_list, cleaned_urls=cleaned_urls)This code calls the function get_news_data with two arguments: ticker_list cleaned_urls. It retrieves news data for the specified ticker symbols stores it in the variable news_data. The content of the news data depends on how the get_news_data function is written.
dates = []
for ticker in ticker_list:
for l in articles_publishdate[ticker]:
dates.append(l)
news_data['Timestamp'] = datesThe code creates a list of publication dates for a given list of ticker symbols, using a dictionary called articles_publishdate to retrieve the dates. Finally, the dates are saved under the key ‘Timestamp’ in a DataFrame named news_data. This is likely for further analysis, such as correlating financial news with market movements.
Articles without publish date are removed and are converted to datetime datatype so that it uniform with the stock data
news_data = news_data[news_data['Timestamp'] != 'None']This code filters a dataset by removing rows with a ‘None’ value in the ‘Timestamp’ column. It checks each row in the dataset keeps those with a valid ‘Timestamp’ value, discarding the rest. The updated dataset is reassigned to the original variable ‘news_data’.
news_data['Timestamp'] = news_data['Timestamp'].apply(lambda date: datetime(int(date[:4]), int(date[5:7]), int(date[8:])))The Python code snippet converts date strings in the ‘Timestamp’ column of ‘news_data’ into datetime objects.
def timestamp_adjuster(timestamp, start, delta):
if timestamp >= datetime(timestamp.year,timestamp.month,timestamp.day,9,15) and timestamp <= datetime(timestamp.year,timestamp.month,timestamp.day,15,15):
timestamp = start + math.ceil((timestamp - start) / delta) * delta
elif timestamp > datetime(timestamp.year,timestamp.month,timestamp.day,15,15) and timestamp < datetime(timestamp.year,timestamp.month,timestamp.day)+timedelta(days=1):
timestamp = datetime(timestamp.year,timestamp.month,timestamp.day,9,15) + timedelta(days=1)
else:
timestamp = datetime(timestamp.year,timestamp.month,timestamp.day,9,15)
return timestampThe code creates a function, timestamp_adjuster, with 3 arguments: timestamp, start, delta. It adjusts the timestamp based on specific rules:
If between 9:15 AM 3:15 PM, round up to nearest delta interval starting from start.
If after 3:15 PM but before midnight, set timestamp to 9:15 AM the next day.
If any other time, set timestamp to 9:15 AM same day. The adjusted timestamp is then returned.
news_data['Timestamp'] = news_data['Timestamp'].apply(lambda x: datetime.strptime(x.strftime('%Y-%m-%d %H:%M:%S'), '%Y-%m-%d %H:%M:%S'))
news_data['Timestamp'] = news_data['Timestamp'].apply(lambda x: timestamp_adjuster(x, start=datetime(2020,1,1,0,15), delta=timedelta(hours=1)))The code modifies timestamps in the ‘Timestamp’ column of the news_data dataframe. It first uses datetime.strptime to format each timestamp into a stard datetime object, then applies a custom adjustment with the timestamp_adjuster function using specific parameters.
news_data.dropna(subset=['Text'], axis=0, inplace=True)The code cleans the news_data dataframe by dropping all rows with missing values in the ‘Text’ column using the dropna method. Only the ‘Text’ column is considered using the subset parameter, axis=0 specifies that rows should be dropped. The operation directly modifies the news_data dataframe.
news_data['Text'] = news_data['Text'].apply(lambda x: str(x))This code snippet converts the ‘Text’ column in the ‘news_data’ dataset to a string data type using the apply() function a lambda function.
news_data.index = range(0, len(news_data))This code reindexes the news_data dataset, resetting the indices to a continuous range of integers from 0 to one less than the dataset’s length. It maintains a consistent sequential index despite any additions, removals, or shuffling of rows.
Getting Stock Data
Stock data with a resolution of 1 hour is extracted from Yahoo Finance using appropriate tickers for the period where news data and tweets are available
def get_stocksdata(ticker_list, start, end, period, resolution):
stocks_data = pd.DataFrame()
for i in range(len(ticker_list)):
temp = yf.download(tickers=[ticker_list[i-1]], start=start, end=end, auto_adjust=True, period=period, interval=resolution)
temp['Timestamp'] = temp.index
temp['Symbol'] = ticker_list[i-1]
stocks_data = stocks_data.append(temp)
return stocks_dataCreate a function called get_stocksdata that downloads historical stock data for a list of stock tickers within a specified date range time resolution. It takes in five parameters: a list of stock tickers, a start date, an end date, a period, a resolution. The function uses the yf.download function to retrieve the data for each ticker adjusts it for corporate actions. A temporary DataFrame is created for each ticker combined into a primary DataFrame. The primary DataFrame is then returned. Remember to use ticker_list[i] instead of ticker_list[i-1] in the loop.
stocks_ticker_list = ["^NSEBANK", 'SBIN.NS', 'IDBI.NS', 'AXISBANK.NS', 'HDFCBANK.NS', 'KOTAKBANK.NS', 'PNB.NS', 'ICICIBANK.NS', 'BANKBARODA.NS', 'CANBK.NS', 'INDUSINDBK.NS', 'BANKINDIA.NS', 'UNIONBANK.NS']
start = min(first_tw, first_ne)
end = min(last_tw, last_ne)
period = '1d'
resolution = '1h'
stocks_data = get_stocksdata(ticker_list=stocks_ticker_list, start=start, end=end, period=period, resolution=resolution)The code pulls stock market data for a specific list of banks from a designated period resolution.
stocks_data.index = range(1, len(stocks_data)+1)This code snippet changes the index of stocks_data to start from 1 instead of 0. It uses a range object to create sequential indexes for every row.
stocks_data['Date'] = stocks_data['Timestamp'].apply(lambda x: x.date)
stocks_data['Time'] = stocks_data['Timestamp'].apply(lambda x: x.time)
stocks_data['Timestamp'] = stocks_data['Timestamp'].apply(lambda x: datetime.strptime(x.strftime('%Y-%m-%d %H:%M:%S'), '%Y-%m-%d %H:%M:%S'))This code manipulates a DataFrame called stocks_data by creating a new ‘Date’ column that contains only the date portion from the ‘Timestamp’ column. It also adds a ‘Time’ column with only the time portion from ‘Timestamp’ re-formats the ‘Timestamp’ column to maintain its original date time data.
stocks_symbol_map = {'NIFTY BANK':"^NSEBANK", 'SBIN':'SBIN.NS', 'IDBI':'IDBI.NS', 'AXISBANK':'AXISBANK.NS', 'HDFCBANK':'HDFCBANK.NS',
'KOTAKBANK':'KOTAKBANK.NS', 'PNB':'PNB.NS', 'ICICIBANK':'ICICIBANK.NS', 'BARODA':'BANKBARODA.NS',
'CANARA':'CANBK.NS', 'INDUSIND':'INDUSINDBK.NS', 'BANKINDIA':'BANKINDIA.NS', 'UNION':'UNIONBANK.NS'}
symbol_stocks_map = {k:v for v,k in stocks_symbol_map.items()}
stocks_data['Ticker'] = stocks_data['Symbol'].map(symbol_stocks_map)The code creates a dictionary called stocks_symbol_map for mapping stock names to their ticker symbols. It also produces a reverse mapping dictionary called symbol_stocks_map by inverting the key-value pairs. Finally, it modifies the ‘Ticker’ column in the stocks_data DataFrame by replacing symbols with their corresponding bank names using symbol_stocks_map.
stocks_data = stocks_data[['Open', 'Volume', 'Ticker', 'Timestamp']]The code snippet selects specific columns from the stocks_data DataFrame, including ‘Open’, ‘Volume’, ‘Ticker’, ‘Timestamp’, creates a new DataFrame with them in that order. This is a common operation when working with specific columns from a larger set of data.
for i in range(1, len(stocks_data['Timestamp'])+1):
temp = stocks_data['Timestamp'][i]
stocks_data['Timestamp'][i] = datetime(temp.year, temp.month, temp.day, temp.hour, temp.minute, temp.second)This code transforms each timestamp in stocks_data[‘Timestamp’] to a stard datetime format without time zone or microsecond info.
stocks_data[stocks_data['Ticker'] == 'NIFTY BANK']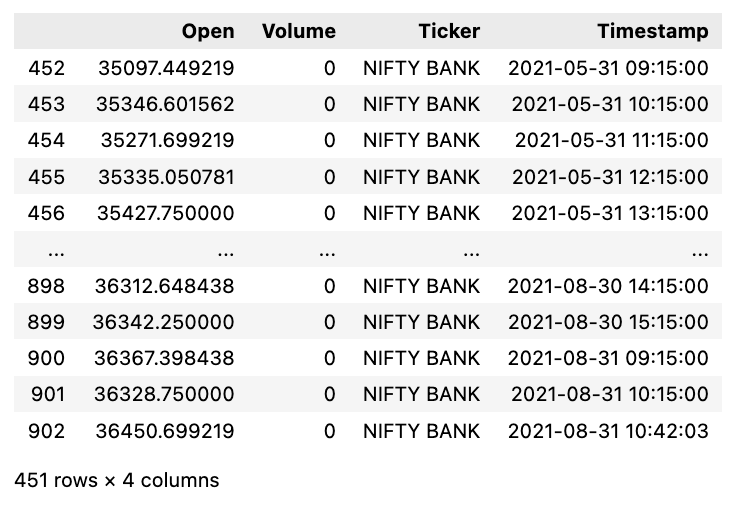
This code filters the stocks_data dataframe by matching the value in the ‘Ticker’ column to ‘NIFTY BANK’. It creates a subset of data specifically for ‘NIFTY BANK’, often used in data analysis. By checking each row in the ‘Ticker’ column, the code selects only the matching rows for the output. Ultimately, producing a new dataframe with the desired information.
Summarizing Text And Performing Sentiment Analysis
tweets['Timestamp'] = tweets['Timestamp'].apply(lambda x: timestamp_adjuster(timestamp=x, start=datetime(2020,1,1,0,15), delta=timedelta(hours=1)))The ‘tweets’ DataFrame’s ‘Timestamp’ column is modified by passing the values through the ‘timestamp_adjuster’ function reassigning them back to the column. The function likely adjusts each timestamp based on a starting date-time timedelta, updating the entire column.
tweets = tweets[['Ticker', 'Title', 'Timestamp']]This code extracts specific columns from the tweets dataset, namely ‘Ticker’, ‘Title’, ‘Timestamp’. The resulting dataset only contains these three columns excludes the rest. This helps to filter prepare the data for further processing.
tweets.columns = ['Ticker', 'Text Summary', 'Timestamp']Rename columns in ‘tweets’ dataframe to ‘Ticker’, ‘Text Summary’, ‘Timestamp’ for data clarity consistency.
News data is summarized using a pre-trained model
summarizer = pipeline("summarization")
This code initializes a text summarization pipeline using the transformers library by Hugging Face. It creates a pre-configured pipeline for the task of summarizing text with a pre-trained model tokenizer. Just pass text to the summarizer for a condensed summary.
Text_Summary = []
for i in range(0, len(news_data['Text'])):
summary = summarizer(news_data['Text'][i][:512], max_length=50, min_length=25, do_sample=False)[0]['summary_text']
Text_Summary.append(summary)
This code creates condensed summaries for texts stored as news_data with key ‘Text’. It uses a function, summarizer, to process texts into summaries that are 25–50 characters long. The results are added to a list, Text_Summary.
news_data['Text Summary'] = Text_SummaryThe code snippet assigns the value of Text_Summary to the ‘Text Summary’ column in the news_data DataFrame. This adds or updates the column by filling it with the contents of Text_Summary. It is useful for appending summaries to news articles in a structured dataset.
for i in range(0, len(news_and_tweets['Sentiment'])):
if news_and_tweets['Sentiment'][i] == 'positive' and news_and_tweets['Sentiment Score'][i] >= 0.6:
news_and_tweets['Sentiment'][i] = 'Buy'
elif news_and_tweets['Sentiment'][i] == 'negative' and news_and_tweets['Sentiment Score'][i] >= 0.6:
news_and_tweets['Sentiment'][i] = 'Sell'
else:
news_and_tweets['Sentiment'][i] = 'None'This code updates the sentiment of items in news__tweets based on their sentiment type score, with a threshold of 0.6. Items with a positive sentiment score 0.6 or higher are updated to ‘Buy’, while items with a negative sentiment score 0.6 or higher are updated to ‘Sell’. Other cases result in a sentiment of ‘None’.
Keep reading with a 7-day free trial
Subscribe to Onepagecode to keep reading this post and get 7 days of free access to the full post archives.