

How LightAutoML Saved a Bank Millions in Record Time!
Find out how LightAutoML is changing the way financial services handle machine learning.

LightAutoML was developed for a large European financial services company and its ecosystem. While building high-quality ML models significantly faster, it performed at the level of experienced data scientists.
Introduction
Several companies and libraries have developed autoML-based models that automatically build ML-based models in the last few years. This paper focuses on developing a vertical AutoML solution for a large European financial services company.
It’s important for AutoML systems to handle large datasets efficiently, to work with different types of data from hundreds of different information systems, as well as build and maintain thousands of production-level models across our complex ecosystem.
A vertical AutoML, called LightAutoML, focuses on the aforementioned needs of our complex ecosystem in this paper. It’s got the following features: almost optimal and fast hyperparameter search, but doesn’t optimize them directly, but still gets good results.
The LightAutoML system performed well on a wide range of data sources. By using it, the company saved millions of dollars and got some novel capabilities.
This paper presents the LightAutoML system we developed for a big financial services company. LightAutoML is compared to the top general-purpose AutoML solutions, and we describe our deployment experience.
Related Work
A paper called Auto-WEKA published in 2013 expanded the early work on AutoML from the mid-’90s.
AutoML uses various optimization methods for hyperparameter search. Selection and optimization of deep learning models, and generating features are other methods.
AutoML has been discussed in the AutoML community about what it is and how to define it. Others cover other stages of the lifecycle and take a broader view of the process.
A review of successful AutoML solutions for medical, financial, and advertisement domains is included. A simple general-purpose AutoML system is created to detect bank failures.
We focus on a broader approach to AutoML, including data processing, model selection, and hyperparameter tuning.
Overview of LIGHTAUTOML
Here’s how LightAutoML works, an open source modular AutoML framework you can download from our GitHub repository. There are four types of ML tasks that LightAutoML supports: TabularAutoML, WhiteBox, NLP, and CV.
When LightAutoML gets raw data, it uses Readers to clean it up and decide what data manipulations to do before fitting different models.
Main components of LightAutoML Pipeline
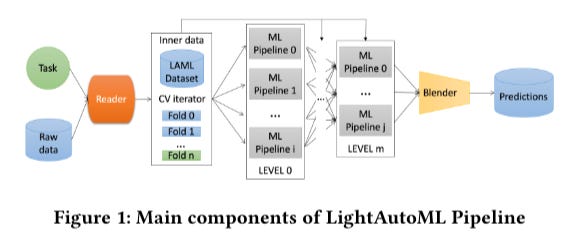
An ML pipeline is a collection of ML models that share a data preprocessing and validation scheme. By averaging the ML pipelines, they can be computed independently on the same datasets.
LightAutoML’s Tabular Preset
On tabular data, TabularAutoML solves three types of problems: binary classification, multiclass classification, and regression.
Three types of algorithms are used in LightAutoML to train two classes of models: Linear Model with L2 penalty, LightGBM version of GBM, and CatBoost version of GBM. Choosing the right order helps you manage your time.
LightAutoML selected traditional ML algorithms since they outperform other approaches in many benchmarks and competitions right now. In addition, linear models are fast and easy to tune.
Data Preprocessing and Auto-typing
Initially, we focused on the data preprocessing part of LightAutoML. To solve the problem of automatic data type inference (autotyping), this part is crucial.
The TabularAutoML Preset maps features into three classes: numeric, category, and datetime. Due to the frequent occurrence of numeric data types in category columns, this mapping isn’t the best.
As a measure of encoding quality, we choose the Normalized Gini Index between target variable and encoded feature. Ten expert rules are used to make the final decision over estimated encoding qualities.
LightAutoML uses machine learning for auto-typing, but not for human labeling. It might boost performance a lot.
We can also guess the best way to preprocess a feature after we infer its type.
Validation Schemes
Data in the industry can change quickly over time in some ecosystem processes, making the independent identically distributed (IID) assumption irrelevant. Validation splits need to be time series-based, grouped, or even custom.
In addition to handling non-IID cases, TabularAutoML uses advanced validation schemes to make models more robust and stable.
Feature Selection
There are three ways to select features in TabularAutoML: No selection, Importance cut off selection (by default), and Importance based forward selection.
There are two ways to estimate feature importance: split-based tree importance or permutation importance of GBM. By using importance cutoffs, you can reduce the number of features without sacrificing performance.
