

Mastering Stock Market Algo Trading with QuantArena
Build, simulation, and validate robust quantitative strategies using the industry-standard Gym interface.

Download entire project code using the link at the end of this article!
QuantArena is a comprehensive toolkit designed for training and backtesting Reinforcement Learning (RL) algorithms in financial markets. Inspired by the flexibility and standardization of OpenAI Gym it provides a familiar interface for developing and evaluating trading strategies.
Whether you are working with high-frequency tick data or standard OHLC (Open, High, Low, Close) bars, QuantArena offers a robust environment to simulate trading sessions, manage portfolios, and visualize agent performance.
Key Features
OpenAI Gym Interface: Fully compatible with the standard
gymAPI (reset,step,render), making it easy to integrate with existing RL libraries (e.g., Stable Baselines, Ray RLLib).Dual Modes:
Training Mode (
training_v1): Randomly samples data segments to ensure agents learn robust, generalized strategies without overfitting to specific historical timelines.Backtesting Mode (
backtest_v1): Simulates trading sequentially over the entire dataset to evaluate strategy performance in a realistic, continuous timeline.Realistic Simulation: Handles transaction fees, maximum position limits (long/short), and precise PnL calculations (realized vs. unrealized).
Visual Rendering: Built-in Matplotlib-based rendering to visualize price action, trade entries/exits, portfolio value, and reward curves in real-time.
Flexible Data Support: Designed for tick data but adaptable for any time-series financial data (OHLC, etc.).
Installation
You can install QuantArena directly from the source code. Ensure you have Python 3.6+ installed.
Download the source code from the link below and follow the following steps.
Install the package:
pip install .
This will automatically install necessary dependencies like pandas, numpy, matplotlib, and colour.
Quick Start Guide
Training Your Agent
The training environment (training_v1) is designed for the learning phase. It randomly selects episodes from your data to maximize sample efficiency and generalization.
import pandas as pd
import numpy as np
import trading_env
# 1. Load your historical data
# Ensure your CSV has a ‘datetime’ column and the columns specified in feature_names
df = pd.read_csv(’your_data.csv’, index_col=0, parse_dates=[’datetime’])
# 2. Initialize the Training Environment
env = trading_env.make(
env_id=’training_v1’,
obs_data_len=256, # Observation window size (history agent sees)
step_len=128, # Steps to move forward each transition
df=df, # Your data
fee=0.1, # Transaction fee per trade
max_position=5, # Max contracts/shares allowed (Long or Short)
deal_col_name=’Price’, # Column used for execution/reward calc
feature_names=[’Price’, ‘Volume’, ‘Macd’, ‘Rsi’], # Features for observation
fluc_div=100.0 # Scaling factor for fluctuation reward
)
# 3. Training Loop
env.reset()
done = False
while not done:
# Random action: 0 (Hold), 1 (Long), 2 (Short)
action = np.random.randint(3)
# Step the environment
state, reward, done, info = env.step(action)
# Render the environment (optional, can be slow)
# env.render()
print(”Training Episode Finished”)Backtesting Your Strategy
The backtesting environment (backtest_v1) runs through your data sequentially from start to finish. Use this to validate your trained agent.
# Initialize Backtest Environment
env_bt = trading_env.make(
env_id=’backtest_v1’,
obs_data_len=256,
step_len=1, # Usually step_len=1 for realistic backtesting
df=df,
fee=0.1,
max_position=5,
deal_col_name=’Price’,
feature_names=[’Price’, ‘Volume’, ‘Macd’, ‘Rsi’]
)
# Backtest Loop
state = env_bt.reset()
done = False
while not done:
# Replace with your trained agent’s prediction
action = model.predict(state)
state, reward, done, info = env_bt.step(action)
# Visualize the trade execution
env_bt.render()
print(”Backtest Complete”)Environment Parameters
When calling trading_env.make(), you can configure the environment with the following arguments:

Visualization
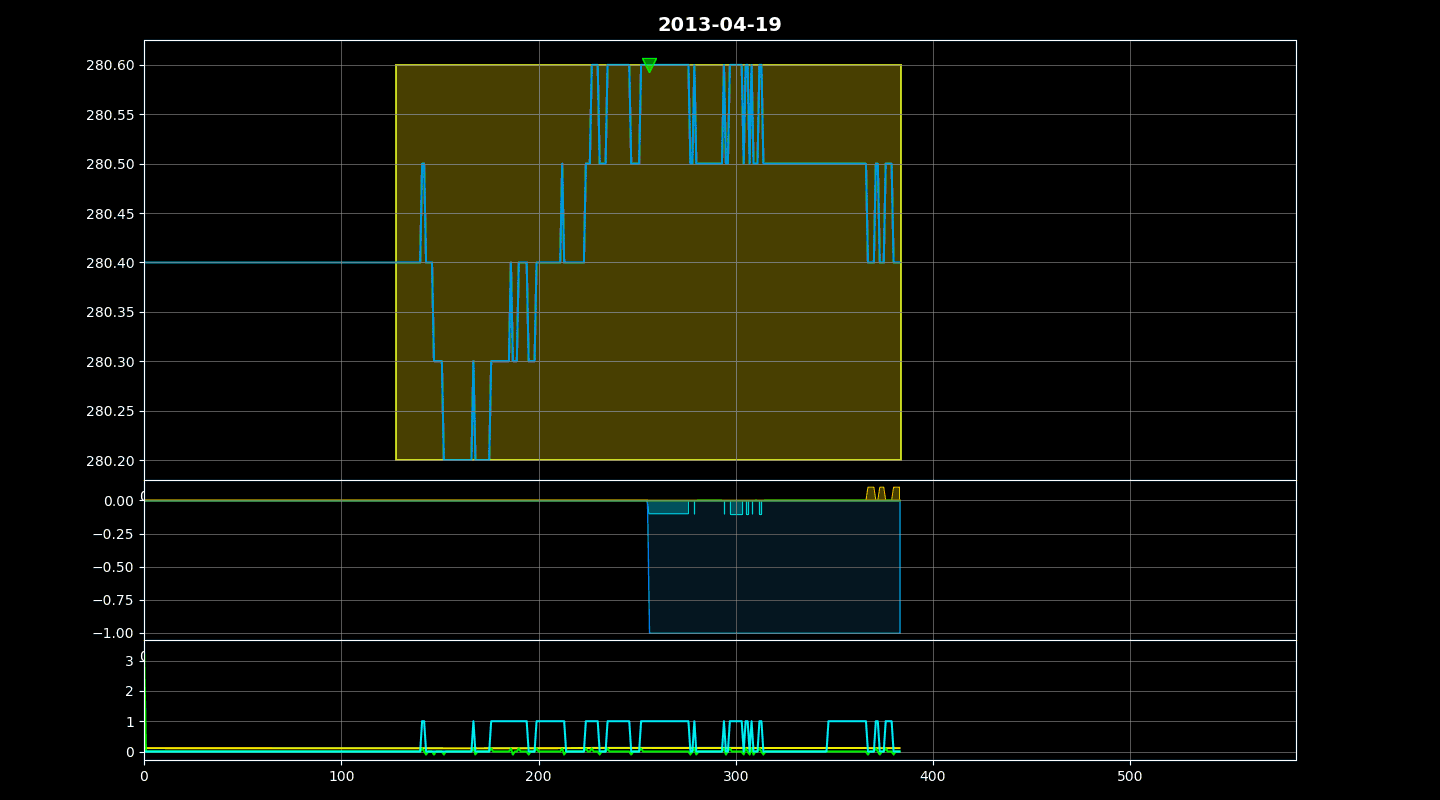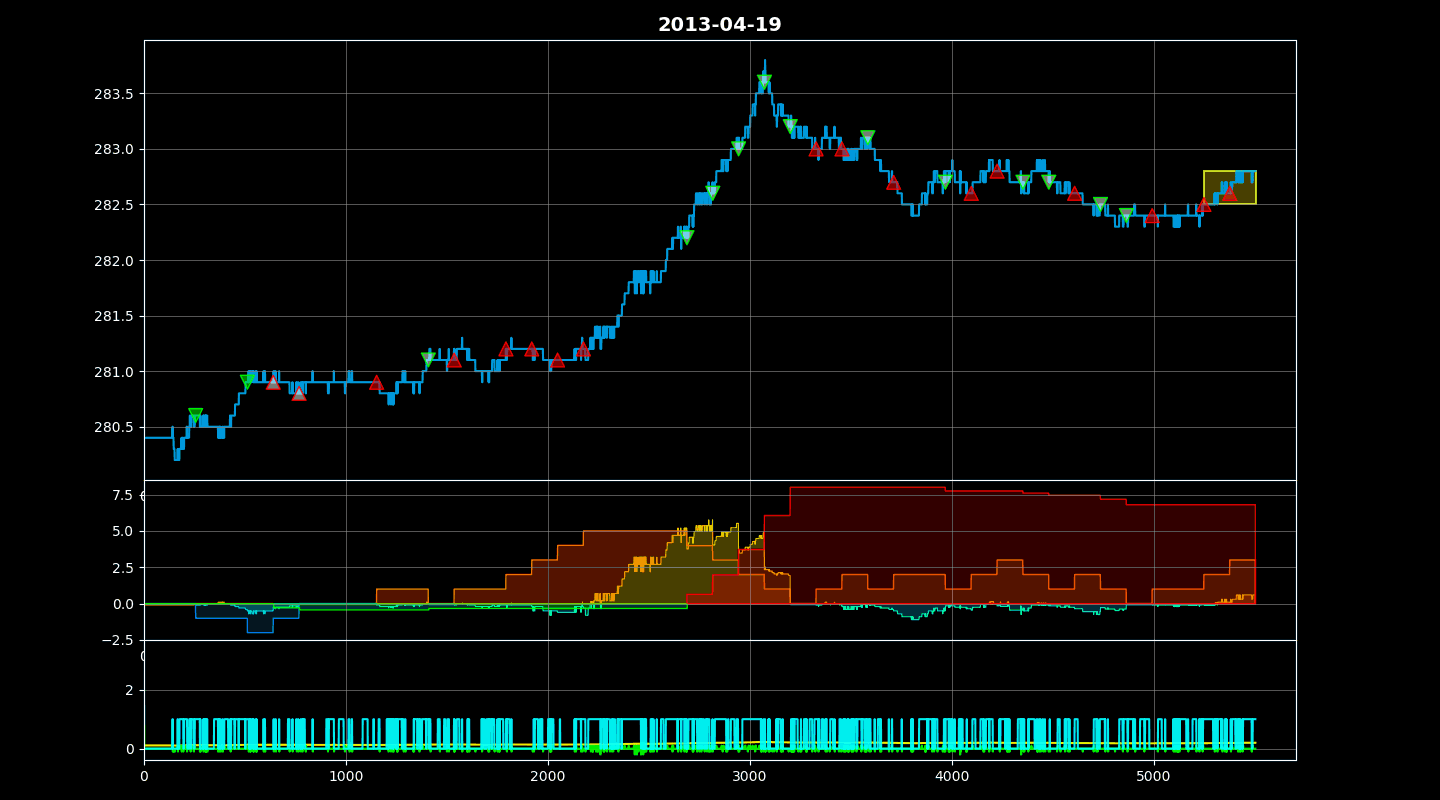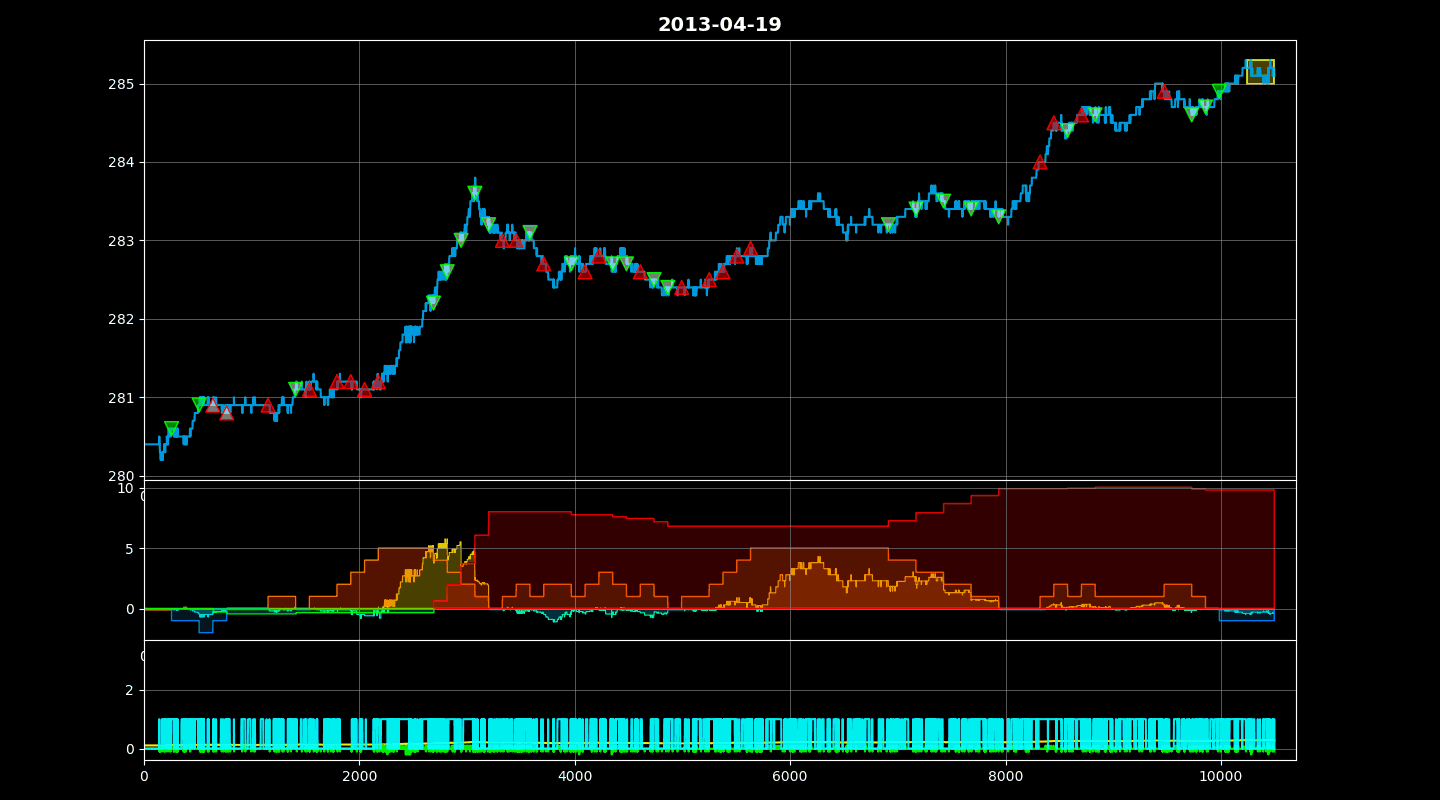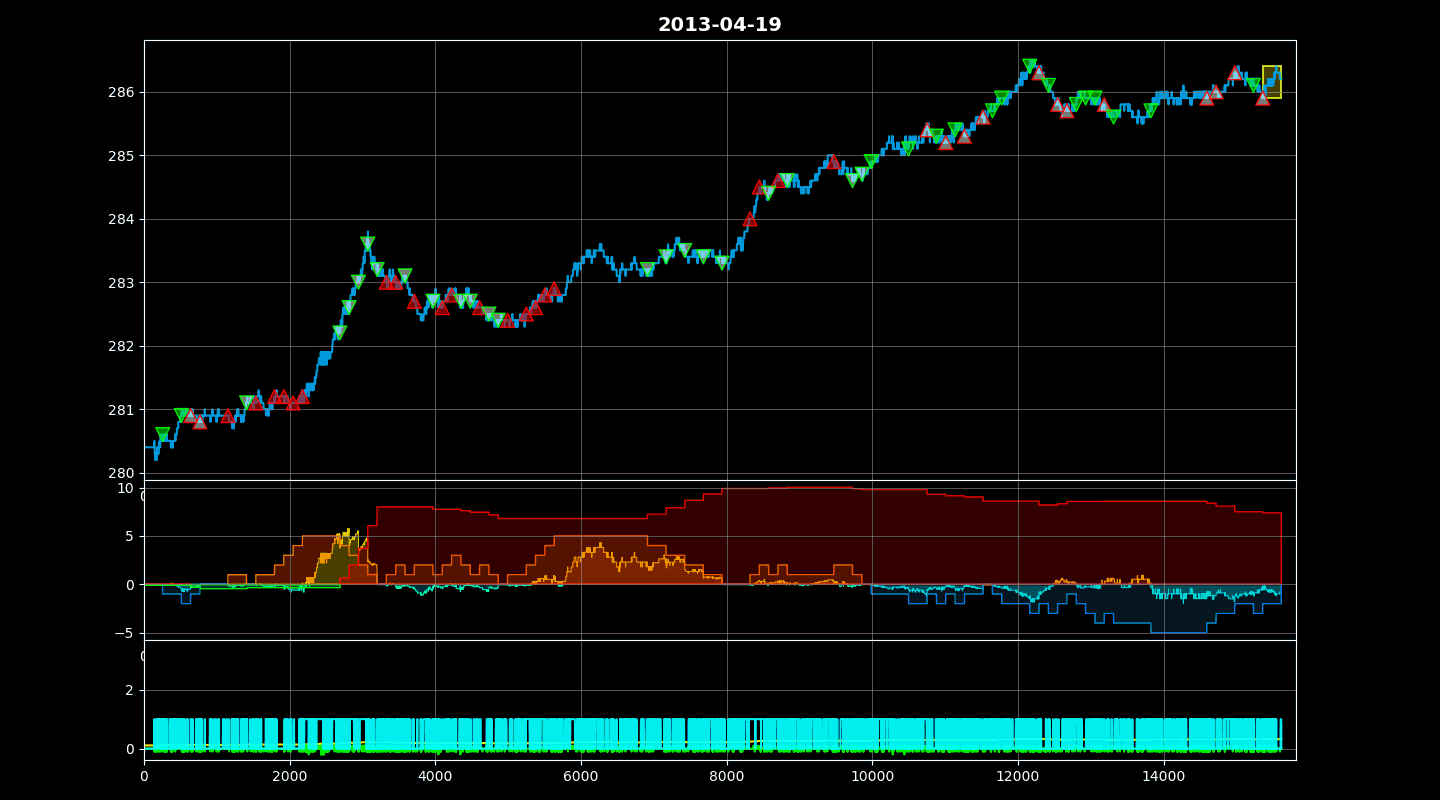
QuantArena includes a powerful rendering engine. Calling `env.render()` displays a window showing:
1. Price Chart: The asset price movement with Buy (Up Triangle) and Sell (Down Triangle) markers.
2. PnL Curve: Real-time plot of Cumulative Reward and Per-step Reward.
3. Position: Visual tracking of the current Net Position.
To save the rendered frames as images (e.g., for creating animations), pass `save=True`:
env.render(save=True)Note: Rendering significantly slows down training. It is recommended to use it only for debugging or final backtest visualization.*
Code Breakdown:
Download entire source code from here:
Onepagecode | Substack
Money + Code + Artificial Intelligence. Click to read Onepagecode, a Substack publication with thousands of…onepagecode.substack.com
Backtest Code Explained:
def __init__(self, env_id, obs_data_len, step_len,
df, fee, max_position=5, deal_col_name=’price’,
feature_names=[’price’, ‘volume’],
return_transaction=True,
fluc_div=100.0, gameover_limit=5,
*args, **kwargs):
#assert df
# need deal price as essential and specified the df format
# obs_data_leng -> observation data length
# step_len -> when call step rolling windows will + step_len
# df -> dataframe that contain data for trading(format as...)
# price
# datetime
# serial_number -> serial num of deal at each day recalculating
# fee -> when each deal will pay the fee, set with your product
# max_position -> the max market position for you trading share
# deal_col_name -> the column name for cucalate reward used.
# feature_names -> list contain the feature columns to use in trading status.
# ?day trade option set as default if don’t use this need modify
logging.basicConfig(level=logging.INFO, format=’[%(asctime)s] %(message)s’)
self.logger = logging.getLogger(env_id)
#self.file_loc_path = os.environ.get(’FILEPATH’, ‘’)
self.df = df
self.action_space = 3
self.action_describe = {0:’do nothing’,
1:’long’,
2:’short’}
self.obs_len = obs_data_len
self.feature_len = len(feature_names)
self.observation_space = np.array([self.obs_len*self.feature_len,])
self.using_feature = feature_names
self.price_name = deal_col_name
self.step_len = step_len
self.fee = fee
self.max_position = max_position
self.fluc_div = fluc_div
self.gameover = gameover_limit
self.return_transaction = return_transaction
self.begin_fs = self.df[self.df[’serial_number’]==0]
self.date_leng = len(self.begin_fs)
self.date_record = 0
self.backtest_done = False
self.render_on = 0
self.buy_color, self.sell_color = (1, 2)
self.new_rotation, self.cover_rotation = (1, 2)
self.transaction_details = pd.DataFrame()
self.logger.info(’Making new env: {}’.format(env_id))The `__init__` method serves as the constructor for the backtesting environment, setting up all the fundamental properties required for the simulation. It initializes the environment ID for logging purposes and configures the dimensions of the observation space (`obs_data_len` for the window size) and the simulation step size (`step_len`). The method accepts the historical dataframe (`df`) and critical trading parameters such as the transaction `fee` and the maximum allowable position size (`max_position`). It also sets up the action space (0: Do Nothing, 1: Long, 2: Short) and prepares various internal variables for tracking the state, such as `transaction_details` and rendering flags. A key part of the initialization is identifying the start of new trading days or sessions using the `serial_number` column, which helps in managing data segmentation.
def _choice_section(self):
“”“
The `_choice_section` method is responsible for selecting the next sequential slice of data for the backtest. Unlike the training environment which chooses random sections, this method strictly iterates through the dataset based on the `date_record` index. It checks if the current record index is less than the total available dates (`date_leng`). If it is the last segment, it selects data from the current point to the end. Otherwise, it selects the data between the current start point and the next start point. It updates the `date_record` counter to ensure the next call retrieves the subsequent data chunk. If the end of the dataset is reached, it sets the `backtest_done` flag to True, signaling that the entire historical period has been simulated.
“”“
assert self.date_record < self.date_leng, ‘Backtest Done.’
section_int = self.date_record
if section_int == self.date_leng - 1:
begin_point = self.begin_fs.index[section_int]
end_point = None
else:
begin_point, end_point = self.begin_fs.index[section_int: section_int+2]
df_section = self.df.iloc[begin_point: end_point]
self.date_record += 1
if self.date_record >= self.date_leng:
self.backtest_done = True
return df_sectionThe `_choice_section` method is responsible for selecting the next sequential slice of data for the backtest. Unlike the training environment which chooses random sections, this method strictly iterates through the dataset based on the `date_record` index. It checks if the current record index is less than the total available dates (`date_leng`). If it is the last segment, it selects data from the current point to the end. Otherwise, it selects the data between the current start point and the next start point. It updates the `date_record` counter to ensure the next call retrieves the subsequent data chunk. If the end of the dataset is reached, it sets the `backtest_done` flag to True, signaling that the entire historical period has been simulated.
def reset(self):
“”“
The `reset` method prepares the environment for the next segment of the backtest. It calls `_choice_section` to retrieve the next chunk of historical data (e.g., the next trading day). It then resets all the transient state variables for the current episode, such as the current step index (`step_st`), price arrays, and observation features. It initializes numpy arrays to track positions (`posi_arr`), position variations (`posi_variation_arr`), and rewards (`reward_arr`). This method effectively clears the slate for the new data segment while preserving the overall progress of the backtest through the sequential data loading mechanism. Finally, it returns the initial observation state for the new segment.
“”“
self.render_on = 0
self.df_sample = self._choice_section()
self.step_st = 0
# define the price to calculate the reward
self.price = self.df_sample[self.price_name].as_matrix()
# define the observation feature
self.obs_features = self.df_sample[self.using_feature].as_matrix()
#maybe make market position feature in final feature, set as option
self.posi_arr = np.zeros_like(self.price)
# position variation
self.posi_variation_arr = np.zeros_like(self.posi_arr)
# position entry or cover :new_entry->1 increase->2 cover->-1 decrease->-2
self.posi_entry_cover_arr = np.zeros_like(self.posi_arr)
# self.position_feature = np.array(self.posi_l[self.step_st:self.step_st+self.obs_len])/(self.max_position*2)+0.5
self.price_mean_arr = self.price.copy()
self.reward_fluctuant_arr = (self.price - self.price_mean_arr)*self.posi_arr
self.reward_makereal_arr = self.posi_arr.copy()
self.reward_arr = self.reward_fluctuant_arr*self.reward_makereal_arr
self.info = None
self.transaction_details = pd.DataFrame()
# observation part
self.obs_state = self.obs_features[self.step_st: self.step_st+self.obs_len]
self.obs_posi = self.posi_arr[self.step_st: self.step_st+self.obs_len]
self.obs_posi_var = self.posi_variation_arr[self.step_st: self.step_st+self.obs_len]
self.obs_posi_entry_cover = self.posi_entry_cover_arr[self.step_st: self.step_st+self.obs_len]
self.obs_price = self.price[self.step_st: self.step_st+self.obs_len]
self.obs_price_mean = self.price_mean_arr[self.step_st: self.step_st+self.obs_len]
self.obs_reward_fluctuant = self.reward_fluctuant_arr[self.step_st: self.step_st+self.obs_len]
self.obs_makereal = self.reward_makereal_arr[self.step_st: self.step_st+self.obs_len]
self.obs_reward = self.reward_arr[self.step_st: self.step_st+self.obs_len]
if self.return_transaction:
self.obs_return = np.concatenate((self.obs_state,
self.obs_posi[:, np.newaxis],
self.obs_posi_var[:, np.newaxis],
self.obs_posi_entry_cover[:, np.newaxis],
self.obs_price[:, np.newaxis],
self.obs_price_mean[:, np.newaxis],
self.obs_reward_fluctuant[:, np.newaxis],
self.obs_makereal[:, np.newaxis],
self.obs_reward[:, np.newaxis]), axis=1)
else:
self.obs_return = self.obs_state
self.t_index = 0
return self.obs_returnThe `reset` method prepares the environment for the next segment of the backtest. It calls `_choice_section` to retrieve the next chunk of historical data (e.g., the next trading day). It then resets all the transient state variables for the current episode, such as the current step index (`step_st`), price arrays, and observation features. It initializes numpy arrays to track positions (`posi_arr`), position variations (`posi_variation_arr`), and rewards (`reward_arr`). This method effectively clears the slate for the new data segment while preserving the overall progress of the backtest through the sequential data loading mechanism. Finally, it returns the initial observation state for the new segment.
def _long(self, open_posi, enter_price, current_mkt_position, current_price_mean):
“”“
The `_long` method encapsulates the logic for executing a LONG (buy) order when the agent wants to increase its position. It takes boolean flags and current state values as input. If `open_posi` is True (meaning the current position is zero), it initializes the position with a single unit and sets the average entry price (`chg_price_mean`) to the execution price. If the agent is already long (`open_posi` is False) and adding to the position, it calculates the new weighted average entry price based on the current holding and the new execution price, and then increments the position count. It also updates flags for position variation and entry/cover status to track the nature of the trade.
“”“
if open_posi:
self.chg_price_mean[:] = enter_price
self.chg_posi[:] = 1
self.chg_posi_var[:1] = 1
self.chg_posi_entry_cover[:1] = 1
else:
after_act_mkt_position = current_mkt_position + 1
self.chg_price_mean[:] = (current_price_mean*current_mkt_position + \
enter_price)/after_act_mkt_position
self.chg_posi[:] = after_act_mkt_position
self.chg_posi_var[:1] = 1
self.chg_posi_entry_cover[:1] = 2The `_long` method encapsulates the logic for executing a LONG (buy) order when the agent wants to increase its position. It takes boolean flags and current state values as input. If `open_posi` is True (meaning the current position is zero), it initializes the position with a single unit and sets the average entry price (`chg_price_mean`) to the execution price. If the agent is already long (`open_posi` is False) and adding to the position, it calculates the new weighted average entry price based on the current holding and the new execution price, and then increments the position count. It also updates flags for position variation and entry/cover status to track the nature of the trade.
def _short(self, open_posi, enter_price, current_mkt_position, current_price_mean):
“”“
The `_short` method handles the logic for executing a SHORT (sell) order to open or increase a short position. Similar to the `_long` method, it checks if this is a new position (`open_posi`). If it is, it sets the position to -1 and records the entry price. If adding to an existing short position, it updates the weighted average entry price and decrements the position count (making it more negative). It updates the relevant state arrays to reflect the position change (`chg_posi`), the variation direction (`chg_posi_var`), and the type of trade (`chg_posi_entry_cover`), ensuring accurate tracking of the portfolio’s short side.
“”“
if open_posi:
self.chg_price_mean[:] = enter_price
self.chg_posi[:] = -1
self.chg_posi_var[:1] = -1
self.chg_posi_entry_cover[:1] = 1
else:
after_act_mkt_position = current_mkt_position - 1
self.chg_price_mean[:] = (current_price_mean*abs(current_mkt_position) + \
enter_price)/abs(after_act_mkt_position)
self.chg_posi[:] = after_act_mkt_position
self.chg_posi_var[:1] = -1
self.chg_posi_entry_cover[:1] = 2The `_short` method handles the logic for executing a SHORT (sell) order to open or increase a short position. Similar to the `_long` method, it checks if this is a new position (`open_posi`). If it is, it sets the position to -1 and records the entry price. If adding to an existing short position, it updates the weighted average entry price and decrements the position count (making it more negative). It updates the relevant state arrays to reflect the position change (`chg_posi`), the variation direction (`chg_posi_var`), and the type of trade (`chg_posi_entry_cover`), ensuring accurate tracking of the portfolio’s short side.
def _short_cover(self, current_price_mean, current_mkt_position):
“”“
The `_short_cover` method executes the logic for closing (covering) a short position. When the agent is short and decides to buy, this method is called. It maintains the current average price but updates the position by incrementing it (moving towards zero). Crucially, it calculates the realized reward for this specific trade action. The reward is derived from the difference between the selling price and the current covering price (multiplied by -1 for short profit logic), minus the transaction fee. It marks the transaction as ‘making real’ profit/loss (`chg_makereal`) and updates the position variation and entry/cover flags to indicate a covering trade.
“”“
self.chg_price_mean[:] = current_price_mean
self.chg_posi[:] = current_mkt_position + 1
self.chg_makereal[:1] = 1
self.chg_reward[:] = ((self.chg_price - self.chg_price_mean)*(-1) - self.fee)*self.chg_makereal
self.chg_posi_var[:1] = 1
self.chg_posi_entry_cover[:1] = -1The `_short_cover` method executes the logic for closing (covering) a short position. When the agent is short and decides to buy, this method is called. It maintains the current average price but updates the position by incrementing it (moving towards zero). Crucially, it calculates the realized reward for this specific trade action. The reward is derived from the difference between the selling price and the current covering price (multiplied by -1 for short profit logic), minus the transaction fee. It marks the transaction as ‘making real’ profit/loss (`chg_makereal`) and updates the position variation and entry/cover flags to indicate a covering trade.
ef _long_cover(self, current_price_mean, current_mkt_position):
“”“
The `_long_cover` method executes the logic for closing (selling) a long position. When the agent is long and decides to sell, this method is called. It decreases the position count (moving towards zero) while keeping the average entry price constant for the remaining portion. It calculates the realized reward based on the difference between the current selling price and the average entry price, subtracting the transaction fee. It updates the state arrays to reflect that a portion of the position has been closed and a realized PnL has been generated (`chg_makereal`), marking the action as a cover operation.
“”“
self.chg_price_mean[:] = current_price_mean
self.chg_posi[:] = current_mkt_position - 1
self.chg_makereal[:1] = 1
self.chg_reward[:] = ((self.chg_price - self.chg_price_mean)*(1) - self.fee)*self.chg_makereal
self.chg_posi_var[:1] = -1
self.chg_posi_entry_cover[:1] = -1The `_long_cover` method executes the logic for closing (selling) a long position. When the agent is long and decides to sell, this method is called. It decreases the position count (moving towards zero) while keeping the average entry price constant for the remaining portion. It calculates the realized reward based on the difference between the current selling price and the average entry price, subtracting the transaction fee. It updates the state arrays to reflect that a portion of the position has been closed and a realized PnL has been generated (`chg_makereal`), marking the action as a cover operation.
def _stayon(self, current_price_mean, current_mkt_position):
“”“
The `_stayon` method handles the ‘Do Nothing’ or ‘Hold’ action. When the agent chooses to maintain its current stance, this method ensures that the state variables for the next step carry over the current values. It propagates the current average entry price (`current_price_mean`) and the current market position (`current_mkt_position`) to the arrays designated for the new time step (`chg_posi`, `chg_price_mean`). This ensures continuity in the portfolio state when no active trading decision is made.
“”“
self.chg_posi[:] = current_mkt_position
self.chg_price_mean[:] = current_price_meanThe `_stayon` method handles the ‘Do Nothing’ or ‘Hold’ action. When the agent chooses to maintain its current stance, this method ensures that the state variables for the next step carry over the current values. It propagates the current average entry price (`current_price_mean`) and the current market position (`current_mkt_position`) to the arrays designated for the new time step (`chg_posi`, `chg_price_mean`). This ensures continuity in the portfolio state when no active trading decision is made.
def step(self, action):
“”“
The `step` method represents the core heartbeat of the simulation, advancing the environment by one time unit. It takes the agent’s chosen `action` and orchestrates the entire state transition process.
First, the method retrieves the current state, including the market position and average price from the previous step. It then advances the time index (`t_index`) and the step pointer (`step_st`). It slices the data arrays to prepare the observation window for the *next* state, gathering price, volume, and other feature data.
The method then checks if the episode has ended (`done`). This condition is met if the simulation step exceeds the available data length. If `done` is True, it forces a liquidation of any remaining open positions. It calculates the final realized reward for closing these positions (whether long or short) and subtracts the fees. It generates a summary DataFrame `transaction_details` containing the complete history of the episode (positions, rewards, price flows) and attaches it to the `info` object.
If the episode is not done, the method proceeds to execute the agent’s action:
- If `action` is 1 (Long):
- If the agent is within position limits (`max_position`), it checks if this is a new position or an addition.
- If keeping within limits, it calls `_long`.
- If the agent is currently Short (`current_mkt_position < 0`), action 1 acts as a cover buy, calling `_short_cover`.
- If the agent is already at maximum long position, the action is forced to 0 (Hold).
- If `action` is 2 (Short):
- If the agent is within short limits, it calls `_short`.
- If the agent is currently Long (`current_mkt_position > 0`), action 2 acts as a cover sell, calling `_long_cover`.
- If the agent is at maximum short position, the action is forced to 0 (Hold).
- If `action` is 0 (Hold):
- It calls `_stayon` to maintain the status quo.
Finally, the method calculates the fluctuating (unrealized) reward for the step based on price movements and the open position. It constructs the full observation vector, which may include the raw features plus state info (position, rewards, etc.), and returns the tuple `(obs_return, obs_reward, done, info)`.
“”“
current_index = self.step_st + self.obs_len -1
current_price_mean = self.price_mean_arr[current_index]
current_mkt_position = self.posi_arr[current_index]
self.t_index += 1
self.step_st += self.step_len
# observation part
self.obs_state = self.obs_features[self.step_st: self.step_st+self.obs_len]
self.obs_posi = self.posi_arr[self.step_st: self.step_st+self.obs_len]
# position variation
self.obs_posi_var = self.posi_variation_arr[self.step_st: self.step_st+self.obs_len]
# position entry or cover :new_entry->1 increase->2 cover->-1 decrease->-2
self.obs_posi_entry_cover = self.posi_entry_cover_arr[self.step_st: self.step_st+self.obs_len]
self.obs_price = self.price[self.step_st: self.step_st+self.obs_len]
self.obs_price_mean = self.price_mean_arr[self.step_st: self.step_st+self.obs_len]
self.obs_reward_fluctuant = self.reward_fluctuant_arr[self.step_st: self.step_st+self.obs_len]
self.obs_makereal = self.reward_makereal_arr[self.step_st: self.step_st+self.obs_len]
self.obs_reward = self.reward_arr[self.step_st: self.step_st+self.obs_len]
# change part
self.chg_posi = self.obs_posi[-self.step_len:]
self.chg_posi_var = self.obs_posi_var[-self.step_len:]
self.chg_posi_entry_cover = self.obs_posi_entry_cover[-self.step_len:]
self.chg_price = self.obs_price[-self.step_len:]
self.chg_price_mean = self.obs_price_mean[-self.step_len:]
self.chg_reward_fluctuant = self.obs_reward_fluctuant[-self.step_len:]
self.chg_makereal = self.obs_makereal[-self.step_len:]
self.chg_reward = self.obs_reward[-self.step_len:]
done = False
if self.step_st+self.obs_len+self.step_len >= len(self.price):
done = True
action = -1
if current_mkt_position != 0:
self.chg_price_mean[:] = current_price_mean
self.chg_posi[:] = 0
self.chg_posi_var[:1] = -current_mkt_position
self.chg_posi_entry_cover[:1] = -2
self.chg_makereal[:1] = 1
self.chg_reward[:] = ((self.chg_price - self.chg_price_mean)*(current_mkt_position) - abs(current_mkt_position)*self.fee)*self.chg_makereal
self.transaction_details = pd.DataFrame([self.posi_arr,
self.posi_variation_arr,
self.posi_entry_cover_arr,
self.price_mean_arr,
self.reward_fluctuant_arr,
self.reward_makereal_arr,
self.reward_arr],
index=[’position’, ‘position_variation’, ‘entry_cover’,
‘price_mean’, ‘reward_fluctuant’, ‘reward_makereal’,
‘reward’],
columns=self.df_sample.index).T
self.info = self.df_sample.join(self.transaction_details)
# use next tick, maybe choice avg in first 10 tick will be better to real backtest
enter_price = self.chg_price[0]
if action == 1 and self.max_position > current_mkt_position >= 0:
open_posi = (current_mkt_position == 0)
self._long(open_posi, enter_price, current_mkt_position, current_price_mean)
elif action == 2 and -self.max_position < current_mkt_position <= 0:
open_posi = (current_mkt_position == 0)
self._short(open_posi, enter_price, current_mkt_position, current_price_mean)
elif action == 1 and current_mkt_position<0:
self._short_cover(current_price_mean, current_mkt_position)
elif action == 2 and current_mkt_position>0:
self._long_cover(current_price_mean, current_mkt_position)
elif action == 1 and current_mkt_position==self.max_position:
action = 0
elif action == 2 and current_mkt_position==-self.max_position:
action = 0
if action == 0:
if current_mkt_position != 0:
self._stayon(current_price_mean, current_mkt_position)
self.chg_reward_fluctuant[:] = (self.chg_price - self.chg_price_mean)*self.chg_posi - np.abs(self.chg_posi)*self.fee
if self.return_transaction:
self.obs_return = np.concatenate((self.obs_state,
self.obs_posi[:, np.newaxis],
self.obs_posi_var[:, np.newaxis],
self.obs_posi_entry_cover[:, np.newaxis],
self.obs_price[:, np.newaxis],
self.obs_price_mean[:, np.newaxis],
self.obs_reward_fluctuant[:, np.newaxis],
self.obs_makereal[:, np.newaxis],
self.obs_reward[:, np.newaxis]), axis=1)
else:
self.obs_return = self.obs_state
return self.obs_return, self.obs_reward.sum(), done, self.infoThe step method functions as the central driving mechanism of the simulation, moving the environment forward by one unit of time and handling all state transitions based on the action chosen by the agent. It begins by reading the current state of the market, including the existing position and the average price carried over from the previous step. After this, it advances the internal time index and updates the pointer that tracks progress through the dataset. The method then prepares the next observation window by slicing the required portion of price, volume, and feature data so that the agent receives updated information.
Once the new position in the data is confirmed, the method checks whether the episode has completed. This happens when the simulation steps exceed the available market data. If the episode has ended, all open positions are forcefully liquidated, and the final realized reward is calculated after accounting for transaction fees. At this point, a complete summary of the episode is generated in the form of a DataFrame that records the sequence of prices, positions, and rewards, and this information is added to the info object for later analysis.
If the simulation has not ended, the method goes on to execute the selected action. A long action attempts to buy or, if the agent is currently holding a short position, acts as a buy to close. Position limits are evaluated to prevent exceeding the allowed maximum exposure. A short action attempts to sell or reduces an existing long position if current holdings favor the opposite direction. If limits are already reached, the action is converted into a hold, preventing further scaling of the trade. When the action is hold, the environment simply maintains the existing state.
After the trading decision is processed, the method updates the unrealized reward to reflect the latest price movement relative to the open position. It then builds the observation vector for the next step, combining the selected technical or raw features with internal state variables such as current position and reward values. The method finishes by returning the updated observation, the new cumulative reward value, a flag indicating whether the episode has ended, and the info dictionary.
def _gen_trade_color(self, ind, long_entry=(1, 0, 0, 0.5), long_cover=(1, 1, 1, 0.5),
short_entry=(0, 1, 0, 0.5), short_cover=(1, 1, 1, 0.5)):
if self.posi_variation_arr[ind]>0 and self.posi_entry_cover_arr[ind]>0:
return long_entry
elif self.posi_variation_arr[ind]>0 and self.posi_entry_cover_arr[ind]<0:
return long_cover
elif self.posi_variation_arr[ind]<0 and self.posi_entry_cover_arr[ind]>0:
return short_entry
elif self.posi_variation_arr[ind]<0 and self.posi_entry_cover_arr[ind]<0:
return short_cover The `_gen_trade_color` method is a helper function for visualization. It determines the color of the trade marker based on the type of transaction that occurred at index `ind`. It examines the `posi_variation_arr` (which shows if position increased or decreased) and the `posi_entry_cover_arr` (which indicates entry or cover).
- If position increased (>0) and it was an entry (>0), it returns the `long_entry` color (typically red).
- If position increased (>0) but it was a cover/others (<0), it returns `long_cover`.
- If position decreased (<0) and it was an entry (>0) [for shorts], it returns `short_entry` (typically green).
- If position decreased (<0) and it was a cover (<0), it returns `short_cover`.
This logic ensures that the visual plot clearly distinguishes between entering/adding to trades and closing/covering them.
def _plot_trading(self):
price_x = list(range(len(self.price[:self.step_st+self.obs_len])))
self.price_plot = self.ax.plot(price_x, self.price[:self.step_st+self.obs_len], c=(0, 0.68, 0.95, 0.9),zorder=1)
# maybe seperate up down color
#self.price_plot = self.ax.plot(price_x, self.price[:self.step_st+self.obs_len], c=(0, 0.75, 0.95, 0.9),zorder=1)
self.features_plot = [self.ax3.plot(price_x, self.obs_features[:self.step_st+self.obs_len, i],
c=self.features_color[i])[0] for i in range(self.feature_len)]
rect_high = self.obs_price.max() - self.obs_price.min()
self.target_box = self.ax.add_patch(
patches.Rectangle(
(self.step_st, self.obs_price.min()), self.obs_len, rect_high,
label=’observation’,edgecolor=(0.9, 1, 0.2, 0.8),facecolor=(0.95,1,0.1,0.3),
linestyle=’-’,linewidth=1.5,
fill=True)
) # remove background)
self.fluc_reward_plot_p = self.ax2.fill_between(price_x, 0, self.reward_fluctuant_arr[:self.step_st+self.obs_len],
where=self.reward_fluctuant_arr[:self.step_st+self.obs_len]>=0,
facecolor=(1, 0.8, 0, 0.2), edgecolor=(1, 0.8, 0, 0.9), linewidth=0.8)
self.fluc_reward_plot_n = self.ax2.fill_between(price_x, 0, self.reward_fluctuant_arr[:self.step_st+self.obs_len],
where=self.reward_fluctuant_arr[:self.step_st+self.obs_len]<=0,
facecolor=(0, 1, 0.8, 0.2), edgecolor=(0, 1, 0.8, 0.9), linewidth=0.8)
self.posi_plot_long = self.ax2.fill_between(price_x, 0, self.posi_arr[:self.step_st+self.obs_len],
where=self.posi_arr[:self.step_st+self.obs_len]>=0,
facecolor=(1, 0.5, 0, 0.2), edgecolor=(1, 0.5, 0, 0.9), linewidth=1)
self.posi_plot_short = self.ax2.fill_between(price_x, 0, self.posi_arr[:self.step_st+self.obs_len],
where=self.posi_arr[:self.step_st+self.obs_len]<=0,
facecolor=(0, 0.5, 1, 0.2), edgecolor=(0, 0.5, 1, 0.9), linewidth=1)
self.reward_plot_p = self.ax2.fill_between(price_x, 0,
self.reward_arr[:self.step_st+self.obs_len].cumsum(),
where=self.reward_arr[:self.step_st+self.obs_len].cumsum()>=0,
facecolor=(1, 0, 0, 0.2), edgecolor=(1, 0, 0, 0.9), linewidth=1)
self.reward_plot_n = self.ax2.fill_between(price_x, 0,
self.reward_arr[:self.step_st+self.obs_len].cumsum(),
where=self.reward_arr[:self.step_st+self.obs_len].cumsum()<=0,
facecolor=(0, 1, 0, 0.2), edgecolor=(0, 1, 0, 0.9), linewidth=1)
trade_x = self.posi_variation_arr.nonzero()[0]
trade_x_buy = [i for i in trade_x if self.posi_variation_arr[i]>0]
trade_x_sell = [i for i in trade_x if self.posi_variation_arr[i]<0]
trade_y_buy = [self.price[i] for i in trade_x_buy]
trade_y_sell = [self.price[i] for i in trade_x_sell]
trade_color_buy = [self._gen_trade_color(i) for i in trade_x_buy]
trade_color_sell = [self._gen_trade_color(i) for i in trade_x_sell]
self.trade_plot_buy = self.ax.scatter(x=trade_x_buy, y=trade_y_buy, s=100, marker=’^’,
c=trade_color_buy, edgecolors=(1,0,0,0.9), zorder=2)
self.trade_plot_sell = self.ax.scatter(x=trade_x_sell, y=trade_y_sell, s=100, marker=’v’,
c=trade_color_sell, edgecolors=(0,1,0,0.9), zorder=2)The `_plot_trading` method performs the heavy lifting of drawing the trading analysis chart. It is called by the `render` method. It plots the price line on the main axis (`self.ax`), and overlays additional features (like volume) on a secondary axis (`self.ax3`). It draws a rectangular box to visualize the current observation window, showing the user exactly what data segment the agent is seeing. It then uses `fill_between` on another axis (`self.ax2`) to visualize:
- The fluctuating reward (unrealized PnL), colored differently for profit (orange) and loss (cyan).
- The current position size (longs in orange, shorts in blue).
- The cumulative reward curve, tracking total strategy performance.
Finally, it identifies the indices where trades occurred and scatters markers (triangles) on the price chart, colored by the specific trade type (as determined by `_gen_trade_color`), providing a clear visual audit of the agent’s decisions.
def render(self, save=False):
if self.render_on == 0:
matplotlib.style.use(’dark_background’)
self.render_on = 1
left, width = 0.1, 0.8
rect1 = [left, 0.4, width, 0.55]
rect2 = [left, 0.2, width, 0.2]
rect3 = [left, 0.05, width, 0.15]
self.fig = plt.figure(figsize=(15,8))
self.fig.suptitle(’%s’%self.df_sample[’datetime’].iloc[0].date(), fontsize=14, fontweight=’bold’)
#self.ax = self.fig.add_subplot(1,1,1)
self.ax = self.fig.add_axes(rect1) # left, bottom, width, height
self.ax2 = self.fig.add_axes(rect2, sharex=self.ax)
self.ax3 = self.fig.add_axes(rect3, sharex=self.ax)
self.ax.grid(color=’gray’, linestyle=’-’, linewidth=0.5)
self.ax2.grid(color=’gray’, linestyle=’-’, linewidth=0.5)
self.ax3.grid(color=’gray’, linestyle=’-’, linewidth=0.5)
self.features_color = [c.rgb+(0.9,) for c in Color(’yellow’).range_to(Color(’cyan’), self.feature_len)]
#fig, ax = plt.subplots()
self._plot_trading()
self.ax.set_xlim(0,len(self.price[:self.step_st+self.obs_len])+200)
plt.ion()
#self.fig.tight_layout()
plt.show()
if save:
self.fig.savefig(’fig/%s.png’ % str(self.t_index))
elif self.render_on == 1:
self.ax.lines.remove(self.price_plot[0])
[self.ax3.lines.remove(plot) for plot in self.features_plot]
self.fluc_reward_plot_p.remove()
self.fluc_reward_plot_n.remove()
self.target_box.remove()
self.reward_plot_p.remove()
self.reward_plot_n.remove()
self.posi_plot_long.remove()
self.posi_plot_short.remove()
self.trade_plot_buy.remove()
self.trade_plot_sell.remove()
self._plot_trading()
self.ax.set_xlim(0,len(self.price[:self.step_st+self.obs_len])+200)
if save:
self.fig.savefig(’fig/%s.png’ % str(self.t_index))
plt.pause(0.0001)The `render` method orchestrates the visualization of the environment. It supports a dynamic, interactive plot using Matplotlib.
- If `render_on` is 0 (first call), it sets up the figure, axes, and layout. It defines the grid, sets the background style, and initializes the plot objects. It then calls `_plot_trading` to draw the initial state.
- If `render_on` is 1 (subsequent calls), it clears the previous frame’s dynamic elements (lines, patches, fills) to prevent overdrawing and slow performance. It then calls `_plot_trading` again to draw the updated state for the current step.
The method handles the axis scaling (`set_xlim`) to keep the chart centered on the action. It also includes an option to save the current frame to the `fig/` directory if `save` is True. Finally, it uses `plt.pause` to allow the GUI event loop to process the drawing, creating the animation effect.
def __init__(self, env_id, obs_data_len, step_len,
df, fee, max_position=5, deal_col_name=’price’,
feature_names=[’price’, ‘volume’],
return_transaction=True,
fluc_div=100.0, gameover_limit=5,
*args, **kwargs):
#assert df
# need deal price as essential and specified the df format
# obs_data_leng -> observation data length
# step_len -> when call step rolling windows will + step_len
# df -> dataframe that contain data for trading(format as...)
# price
# datetime
# serial_number -> serial num of deal at each day recalculating
# fee -> when each deal will pay the fee, set with your product
# max_position -> the max market position for you trading share
# deal_col_name -> the column name for cucalate reward used.
# feature_names -> list contain the feature columns to use in trading status.
# ?day trade option set as default if don’t use this need modify
logging.basicConfig(level=logging.INFO, format=’[%(asctime)s] %(message)s’)
self.logger = logging.getLogger(env_id)
#self.file_loc_path = os.environ.get(’FILEPATH’, ‘’)
self.df = df
self.action_space = 3
self.action_describe = {0:’do nothing’,
1:’long’,
2:’short’}
self.obs_len = obs_data_len
self.feature_len = len(feature_names)
self.observation_space = np.array([self.obs_len*self.feature_len,])
self.using_feature = feature_names
self.price_name = deal_col_name
self.step_len = step_len
self.fee = fee
self.max_position = max_position
self.fluc_div = fluc_div
self.gameover = gameover_limit
self.return_transaction = return_transaction
self.begin_fs = self.df[self.df[’serial_number’]==0]
self.date_leng = len(self.begin_fs)
self.render_on = 0
self.buy_color, self.sell_color = (1, 2)
self.new_rotation, self.cover_rotation = (1, 2)
self.transaction_details = pd.DataFrame()
self.logger.info(’Making new env: {}’.format(env_id))The `__init__` method initializes the training environment with the necessary configuration. It sets up the logging system using the provided `env_id` and defines the core dimensions of the RL problem: `obs_data_len` (the lookback window size) and `step_len` (how far the simulation advances each step). It ingests the historical market data (`df`) and sets critical trading constraints like the transaction `fee`, `max_position` limit, and a stop-loss/gameover threshold (`gameover_limit`). The method also defines the discrete action space (Hold, Long, Short) and the continuous observation space. It identifies the start of every trading day in the dataset (`serial_number == 0`) to allow for valid random episode sampling.
def _random_choice_section(self):
random_int = np.random.randint(self.date_leng)
if random_int == self.date_leng - 1:
begin_point = self.begin_fs.index[random_int]
end_point = None
else:
begin_point, end_point = self.begin_fs.index[random_int: random_int+2]
df_section = self.df.iloc[begin_point: end_point]
return df_sectionThe `_random_choice_section` method is the key mechanism for the training environment’s stochasticity. It randomly selects a valid starting point for a new episode from the available data. It uses `np.random.randint` to pick a random day index from `begin_fs` (the list of day start indices). It then slices the main DataFrame `df` to extract the data for that specific day (or period) defined by the start index and the subsequent start index. This random slice (`df_section`) effectively becomes the “mini-universe” for the agent’s next training episode, ensuring diverse exposure to market history.
def reset(self):
self.df_sample = self._random_choice_section()
self.step_st = 0
# define the price to calculate the reward
self.price = self.df_sample[self.price_name].to_numpy()
# define the observation feature
self.obs_features = self.df_sample[self.using_feature].to_numpy()
#maybe make market position feature in final feature, set as option
self.posi_arr = np.zeros_like(self.price)
# position variation
self.posi_variation_arr = np.zeros_like(self.posi_arr)
# position entry or cover :new_entry->1 increase->2 cover->-1 decrease->-2
self.posi_entry_cover_arr = np.zeros_like(self.posi_arr)
# self.position_feature = np.array(self.posi_l[self.step_st:self.step_st+self.obs_len])/(self.max_position*2)+0.5
self.price_mean_arr = self.price.copy()
self.reward_fluctuant_arr = (self.price - self.price_mean_arr)*self.posi_arr
self.reward_makereal_arr = self.posi_arr.copy()
self.reward_arr = self.reward_fluctuant_arr*self.reward_makereal_arr
self.info = None
self.transaction_details = pd.DataFrame()
# observation part
self.obs_state = self.obs_features[self.step_st: self.step_st+self.obs_len]
self.obs_posi = self.posi_arr[self.step_st: self.step_st+self.obs_len]
self.obs_posi_var = self.posi_variation_arr[self.step_st: self.step_st+self.obs_len]
self.obs_posi_entry_cover = self.posi_entry_cover_arr[self.step_st: self.step_st+self.obs_len]
self.obs_price = self.price[self.step_st: self.step_st+self.obs_len]
self.obs_price_mean = self.price_mean_arr[self.step_st: self.step_st+self.obs_len]
self.obs_reward_fluctuant = self.reward_fluctuant_arr[self.step_st: self.step_st+self.obs_len]
self.obs_makereal = self.reward_makereal_arr[self.step_st: self.step_st+self.obs_len]
self.obs_reward = self.reward_arr[self.step_st: self.step_st+self.obs_len]
if self.return_transaction:
self.obs_return = np.concatenate((self.obs_state,
self.obs_posi[:, np.newaxis],
self.obs_posi_var[:, np.newaxis],
self.obs_posi_entry_cover[:, np.newaxis],
self.obs_price[:, np.newaxis],
self.obs_price_mean[:, np.newaxis],
self.obs_reward_fluctuant[:, np.newaxis],
self.obs_makereal[:, np.newaxis],
self.obs_reward[:, np.newaxis]), axis=1)
else:
self.obs_return = self.obs_state
self.t_index = 0
return self.obs_returnThe `reset` method is called to start a new training episode. It invokes `_random_choice_section` to get a fresh, random slice of market data. It then resets all internal state counters and arrays: `step_st` (simulation step), `posi_arr` (positions), `reward_arr` (rewards), and others. It prepares the initial observation vector from the beginning of this new data slice. By resetting to a random market scenario each time, this method ensures that the agent’s learning process is not biased by the chronological order of the data.
def _long(self, open_posi, enter_price, current_mkt_position, current_price_mean):
if open_posi:
self.chg_price_mean[:] = enter_price
self.chg_posi[:] = 1
self.chg_posi_var[:1] = 1
self.chg_posi_entry_cover[:1] = 1
else:
after_act_mkt_position = current_mkt_position + 1
self.chg_price_mean[:] = (current_price_mean*current_mkt_position + \
enter_price)/after_act_mkt_position
self.chg_posi[:] = after_act_mkt_position
self.chg_posi_var[:1] = 1
self.chg_posi_entry_cover[:1] = 2The `_long` method executes a LONG (buy) order logic. If `open_posi` is True (new position), it sets the position to 1 and records the entry price. If adding to an existing long position, it updates the weighted average entry price (`chg_price_mean`) and increments the position size. It marks the helper arrays `chg_posi_var` and `chg_posi_entry_cover` to record the type of transaction (entry/increase).
def _short(self, open_posi, enter_price, current_mkt_position, current_price_mean):
if open_posi:
self.chg_price_mean[:] = enter_price
self.chg_posi[:] = -1
self.chg_posi_var[:1] = -1
self.chg_posi_entry_cover[:1] = 1
else:
after_act_mkt_position = current_mkt_position - 1
self.chg_price_mean[:] = (current_price_mean*abs(current_mkt_position) + \
enter_price)/abs(after_act_mkt_position)
self.chg_posi[:] = after_act_mkt_position
self.chg_posi_var[:1] = -1
self.chg_posi_entry_cover[:1] = 2The `_short` method executes a SHORT (sell) order logic. If opening a new short position (`open_posi` is True), it sets the position to -1. If adding to an existing short, it updates the average entry price and decrements the position (making it more negative). It updates status arrays to reflect the short entry or addition.
def _short_cover(self, current_price_mean, current_mkt_position):
self.chg_price_mean[:] = current_price_mean
self.chg_posi[:] = current_mkt_position + 1
self.chg_makereal[:1] = 1
self.chg_reward[:] = ((self.chg_price - self.chg_price_mean)*(-1) - self.fee)*self.chg_makereal
self.chg_posi_var[:1] = 1
self.chg_posi_entry_cover[:1] = -1The `_short_cover` method handles the closing of a Short position (buying back). It increments the position count (moving it towards 0) while keeping the average price constant for the *remaining* position. It calculates the realized PnL for the portion being covered: (Selling Price — Current Price) — Fees. It sets the `chg_makereal` flag to indicate a realized profit/loss event.
def _long_cover(self, current_price_mean, current_mkt_position):
self.chg_price_mean[:] = current_price_mean
self.chg_posi[:] = current_mkt_position - 1
self.chg_makereal[:1] = 1
self.chg_reward[:] = ((self.chg_price - self.chg_price_mean)*(1) - self.fee)*self.chg_makereal
self.chg_posi_var[:1] = -1
self.chg_posi_entry_cover[:1] = -1The `_long_cover` method handles the closing of a Long position (selling). It decrements the position count (moving it towards 0). It calculates the realized PnL based on (Current Price — Average Entry Price) — Fees. It updates the state arrays to reflect the partial or full closure of the trade and the realization of financial results.
def _stayon(self, current_price_mean, current_mkt_position):
“”“
The `_stayon` method maintains the current state when the agent chooses to Hold (Do Nothing). It simply copies the current position and average entry price to the variables for the next time step, ensuring continuity in the portfolio state.
“”“
self.chg_posi[:] = current_mkt_position
self.chg_price_mean[:] = current_price_meanThe `_stayon` method maintains the current state when the agent chooses to Hold (Do Nothing). It simply copies the current position and average entry price to the variables for the next time step, ensuring continuity in the portfolio state.
def step(self, action):
current_index = self.step_st + self.obs_len -1
current_price_mean = self.price_mean_arr[current_index]
current_mkt_position = self.posi_arr[current_index]
self.t_index += 1
self.step_st += self.step_len
# observation part
self.obs_state = self.obs_features[self.step_st: self.step_st+self.obs_len]
self.obs_posi = self.posi_arr[self.step_st: self.step_st+self.obs_len]
# position variation
self.obs_posi_var = self.posi_variation_arr[self.step_st: self.step_st+self.obs_len]
# position entry or cover :new_entry->1 increase->2 cover->-1 decrease->-2
self.obs_posi_entry_cover = self.posi_entry_cover_arr[self.step_st: self.step_st+self.obs_len]
self.obs_price = self.price[self.step_st: self.step_st+self.obs_len]
self.obs_price_mean = self.price_mean_arr[self.step_st: self.step_st+self.obs_len]
self.obs_reward_fluctuant = self.reward_fluctuant_arr[self.step_st: self.step_st+self.obs_len]
self.obs_makereal = self.reward_makereal_arr[self.step_st: self.step_st+self.obs_len]
self.obs_reward = self.reward_arr[self.step_st: self.step_st+self.obs_len]
# change part
self.chg_posi = self.obs_posi[-self.step_len:]
self.chg_posi_var = self.obs_posi_var[-self.step_len:]
self.chg_posi_entry_cover = self.obs_posi_entry_cover[-self.step_len:]
self.chg_price = self.obs_price[-self.step_len:]
self.chg_price_mean = self.obs_price_mean[-self.step_len:]
self.chg_reward_fluctuant = self.obs_reward_fluctuant[-self.step_len:]
self.chg_makereal = self.obs_makereal[-self.step_len:]
self.chg_reward = self.obs_reward[-self.step_len:]
done = False
if self.step_st+self.obs_len+self.step_len >= len(self.price):
done = True
action = -1
if current_mkt_position != 0:
self.chg_price_mean[:] = current_price_mean
self.chg_posi[:] = 0
self.chg_posi_var[:1] = -current_mkt_position
self.chg_posi_entry_cover[:1] = -2
self.chg_makereal[:1] = 1
self.chg_reward[:] = ((self.chg_price - self.chg_price_mean)*(current_mkt_position) - abs(current_mkt_position)*self.fee)*self.chg_makereal
self.transaction_details = pd.DataFrame([self.posi_arr,
self.posi_variation_arr,
self.posi_entry_cover_arr,
self.price_mean_arr,
self.reward_fluctuant_arr,
self.reward_makereal_arr,
self.reward_arr],
index=[’position’, ‘position_variation’, ‘entry_cover’,
‘price_mean’, ‘reward_fluctuant’, ‘reward_makereal’,
‘reward’],
columns=self.df_sample.index).T
self.info = self.df_sample.join(self.transaction_details)
# use next tick, maybe choice avg in first 10 tick will be better to real backtest
enter_price = self.chg_price[0]
if action == 1 and self.max_position > current_mkt_position >= 0:
open_posi = (current_mkt_position == 0)
self._long(open_posi, enter_price, current_mkt_position, current_price_mean)
elif action == 2 and -self.max_position < current_mkt_position <= 0:
open_posi = (current_mkt_position == 0)
self._short(open_posi, enter_price, current_mkt_position, current_price_mean)
elif action == 1 and current_mkt_position<0:
self._short_cover(current_price_mean, current_mkt_position)
elif action == 2 and current_mkt_position>0:
self._long_cover(current_price_mean, current_mkt_position)
elif action == 1 and current_mkt_position==self.max_position:
action = 0
elif action == 2 and current_mkt_position==-self.max_position:
action = 0
if action == 0:
if current_mkt_position != 0:
self._stayon(current_price_mean, current_mkt_position)
self.chg_reward_fluctuant[:] = (self.chg_price - self.chg_price_mean)*self.chg_posi - np.abs(self.chg_posi)*self.fee
if self.return_transaction:
self.obs_return = np.concatenate((self.obs_state,
self.obs_posi[:, np.newaxis],
self.obs_posi_var[:, np.newaxis],
self.obs_posi_entry_cover[:, np.newaxis],
self.obs_price[:, np.newaxis],
self.obs_price_mean[:, np.newaxis],
self.obs_reward_fluctuant[:, np.newaxis],
self.obs_makereal[:, np.newaxis],
self.obs_reward[:, np.newaxis]), axis=1)
else:
self.obs_return = self.obs_state
return self.obs_return, self.obs_reward.sum(), done, self.infoThe step method moves the training simulation forward by one time interval. It receives the action chosen by the agent and returns the next observation, the reward obtained, and a flag indicating whether the episode has finished. When this method runs, the environment shifts its internal state to the next timestamp and collects the appropriate segment of market data to form the next observation. This observation contains numerical values such as prices and position related information.
At every step the environment checks whether the data sequence has reached its end. If that situation occurs the episode is marked finished, and any open positions are forcefully closed so that the final reward reflects the actual profit or loss. Based on the selected action the method executes trading logic. A long action will either initiate a buy or close a short position when the agent is already short. A short action will either initiate a sell or close a long position when the agent is already long. A hold action keeps the current position unchanged. Position limits are always verified before any trade is executed.
Once the action is processed the environment updates the reward to reflect the change in price along with any transaction costs. Internal values such as price statistics and position related variables are also updated to prepare for the next step. After these updates the method returns the next observation, the cumulative reward so far, the status of completion, and an information dictionary.
def _gen_trade_color(self, ind, long_entry=(1, 0, 0, 0.5), long_cover=(1, 1, 1, 0.5),
short_entry=(0, 1, 0, 0.5), short_cover=(1, 1, 1, 0.5)):
if self.posi_variation_arr[ind]>0 and self.posi_entry_cover_arr[ind]>0:
return long_entry
elif self.posi_variation_arr[ind]>0 and self.posi_entry_cover_arr[ind]<0:
return long_cover
elif self.posi_variation_arr[ind]<0 and self.posi_entry_cover_arr[ind]>0:
return short_entry
elif self.posi_variation_arr[ind]<0 and self.posi_entry_cover_arr[ind]<0:
return short_cover The `_gen_trade_color` method determines the color of trade markers for the visualization. It analyzes the position change (`posi_variation_arr`) and entry/cover status (`posi_entry_cover_arr`) at a given index to classify the trade as Long Entry, Long Cover, Short Entry, or Short Cover, returning the appropriate RGBA color tuple.
def _plot_trading(self):
price_x = list(range(len(self.price[:self.step_st+self.obs_len])))
self.price_plot = self.ax.plot(price_x, self.price[:self.step_st+self.obs_len], c=(0, 0.68, 0.95, 0.9),zorder=1)
# maybe seperate up down color
#self.price_plot = self.ax.plot(price_x, self.price[:self.step_st+self.obs_len], c=(0, 0.75, 0.95, 0.9),zorder=1)
self.features_plot = [self.ax3.plot(price_x, self.obs_features[:self.step_st+self.obs_len, i],
c=self.features_color[i])[0] for i in range(self.feature_len)]
rect_high = self.obs_price.max() - self.obs_price.min()
self.target_box = self.ax.add_patch(
patches.Rectangle(
(self.step_st, self.obs_price.min()), self.obs_len, rect_high,
label=’observation’,edgecolor=(0.9, 1, 0.2, 0.8),facecolor=(0.95,1,0.1,0.3),
linestyle=’-’,linewidth=1.5,
fill=True)
) # remove background)
self.fluc_reward_plot_p = self.ax2.fill_between(price_x, 0, self.reward_fluctuant_arr[:self.step_st+self.obs_len],
where=self.reward_fluctuant_arr[:self.step_st+self.obs_len]>=0,
facecolor=(1, 0.8, 0, 0.2), edgecolor=(1, 0.8, 0, 0.9), linewidth=0.8)
self.fluc_reward_plot_n = self.ax2.fill_between(price_x, 0, self.reward_fluctuant_arr[:self.step_st+self.obs_len],
where=self.reward_fluctuant_arr[:self.step_st+self.obs_len]<=0,
facecolor=(0, 1, 0.8, 0.2), edgecolor=(0, 1, 0.8, 0.9), linewidth=0.8)
self.posi_plot_long = self.ax2.fill_between(price_x, 0, self.posi_arr[:self.step_st+self.obs_len],
where=self.posi_arr[:self.step_st+self.obs_len]>=0,
facecolor=(1, 0.5, 0, 0.2), edgecolor=(1, 0.5, 0, 0.9), linewidth=1)
self.posi_plot_short = self.ax2.fill_between(price_x, 0, self.posi_arr[:self.step_st+self.obs_len],
where=self.posi_arr[:self.step_st+self.obs_len]<=0,
facecolor=(0, 0.5, 1, 0.2), edgecolor=(0, 0.5, 1, 0.9), linewidth=1)
self.reward_plot_p = self.ax2.fill_between(price_x, 0,
self.reward_arr[:self.step_st+self.obs_len].cumsum(),
where=self.reward_arr[:self.step_st+self.obs_len].cumsum()>=0,
facecolor=(1, 0, 0, 0.2), edgecolor=(1, 0, 0, 0.9), linewidth=1)
self.reward_plot_n = self.ax2.fill_between(price_x, 0,
self.reward_arr[:self.step_st+self.obs_len].cumsum(),
where=self.reward_arr[:self.step_st+self.obs_len].cumsum()<=0,
facecolor=(0, 1, 0, 0.2), edgecolor=(0, 1, 0, 0.9), linewidth=1)
trade_x = self.posi_variation_arr.nonzero()[0]
trade_x_buy = [i for i in trade_x if self.posi_variation_arr[i]>0]
trade_x_sell = [i for i in trade_x if self.posi_variation_arr[i]<0]
trade_y_buy = [self.price[i] for i in trade_x_buy]
trade_y_sell = [self.price[i] for i in trade_x_sell]
trade_color_buy = [self._gen_trade_color(i) for i in trade_x_buy]
trade_color_sell = [self._gen_trade_color(i) for i in trade_x_sell]
self.trade_plot_buy = self.ax.scatter(x=trade_x_buy, y=trade_y_buy, s=100, marker=’^’,
c=trade_color_buy, edgecolors=(1,0,0,0.9), zorder=2)
self.trade_plot_sell = self.ax.scatter(x=trade_x_sell, y=trade_y_sell, s=100, marker=’v’,
c=trade_color_sell, edgecolors=(0,1,0,0.9), zorder=2)The `_plot_trading` method draws the trading chart components. It plots the price history line, the observation window box, and the volume (or other features). Crucially, it visualizes the agent’s performance by filling areas under the curve for profit/loss (PnL) and position size. It also scatters markers (triangles) at specific time steps where buys and sells occurred, colored by trade type, to give a complete visual replay of the agent’s decisions.
def render(self, save=False):
if self.render_on == 0:
matplotlib.style.use(’dark_background’)
self.render_on = 1
left, width = 0.1, 0.8
rect1 = [left, 0.4, width, 0.55]
rect2 = [left, 0.2, width, 0.2]
rect3 = [left, 0.05, width, 0.15]
self.fig = plt.figure(figsize=(15,8))
self.fig.suptitle(’%s’%self.df_sample[’datetime’].iloc[0].date(), fontsize=14, fontweight=’bold’)
#self.ax = self.fig.add_subplot(1,1,1)
self.ax = self.fig.add_axes(rect1) # left, bottom, width, height
self.ax2 = self.fig.add_axes(rect2, sharex=self.ax)
self.ax3 = self.fig.add_axes(rect3, sharex=self.ax)
self.ax.grid(color=’gray’, linestyle=’-’, linewidth=0.5)
self.ax2.grid(color=’gray’, linestyle=’-’, linewidth=0.5)
self.ax3.grid(color=’gray’, linestyle=’-’, linewidth=0.5)
self.features_color = [c.rgb+(0.9,) for c in Color(’yellow’).range_to(Color(’cyan’), self.feature_len)]
#fig, ax = plt.subplots()
self._plot_trading()
self.ax.set_xlim(0,len(self.price[:self.step_st+self.obs_len])+200)
plt.ion()
#self.fig.tight_layout()
plt.show()
if save:
self.fig.savefig(’fig/%s.png’ % str(self.t_index))
elif self.render_on == 1:
self.ax.lines.remove(self.price_plot[0])
[self.ax3.lines.remove(plot) for plot in self.features_plot]
self.fluc_reward_plot_p.remove()
self.fluc_reward_plot_n.remove()
self.target_box.remove()
self.reward_plot_p.remove()
self.reward_plot_n.remove()
self.posi_plot_long.remove()
self.posi_plot_short.remove()
self.trade_plot_buy.remove()
self.trade_plot_sell.remove()
self._plot_trading()
self.ax.set_xlim(0,len(self.price[:self.step_st+self.obs_len])+200)
if save:
self.fig.savefig(’fig/%s.png’ % str(self.t_index))
plt.pause(0.0001)The `render` method updates the Matplotlib visualization of the environment. On the first call (`render_on==0`), it initializes the figure, axes, and static elements. On subsequent calls, it clears dynamic elements and redraws the plot using `_plot_trading` to reflect the updated state. This allows for real-time (animation-style) viewing of the training process.
Final Setup.py
from setuptools import setup, find_packages
setup(
name=’QuantArena’,
version=’0.0.1dev0’,
author=’Yvictor’,
author_email=’410175015@gms.ndhu.edu.tw’,
packages=find_packages(),
install_requires=[”pandas”,
“numpy”,
“matplotlib”,
“colour”],
)This setup.py script serves as the configuration file that controls how the trading_env package is built, installed, and distributed. It uses the setuptools module to define important information about the package so that it can be installed easily and managed properly.
When the script is run through commands such as pip install ., the setup function reads the provided arguments to register the package. The name and version identify the library, while the author and author_email fields provide developer information. The packages option relies on find_packages to automatically scan the project directory and include every valid package, meaning folders that contain an init.py file. This ensures that the core trading_env module and related submodules are packaged together without requiring manual listing.
The install_requires section specifies the external libraries that must be present for the package to work. These required dependencies include pandas for handling datasets, numpy for numerical computations, matplotlib for generating graphical outputs, and colour for applying colors to plots. Including them in the configuration guarantees that anyone installing the package receives a complete environment with all necessary tools for running trading simulations without additional setup steps.