


MoE-LLaVA: Revolutionizing Large Vision-Language Models with Efficient Scaling and Multimodal Expertise
MoE-LLaVA: Revolutionizing Large Vision-Language Models with Efficient Scaling and Multimodal Expertise
Breaking Barriers in AI with an Innovative Approach to Model Efficiency and Performance in Vision-Language Understanding

Talking about this paper: read here.

The intersection of vision and language models has led to transformative advancements in AI, enabling applications that understand and interpret the world in ways akin to human perception. Large Vision-Language Models (LVLMs) stand at the forefront of this revolution, offering unparalleled capabilities in image recognition, visual question answering, and multimodal interactions. The motivation for scaling these models stems from the desire to further enhance their accuracy, robustness, and versatility. As these models grow in complexity and scope, they become capable of tackling a wider range of tasks with greater nuance and sophistication, bridging the gap between AI and human-like understanding of visual and textual information.
Associated Challenges
However, the ambitious pursuit of scaling LVLMs is not without its challenges. Primarily, the exponential growth in model parameters necessitates a corresponding increase in computational resources for training and inference. This surge in computational demand poses significant barriers to accessibility, efficiency, and environmental sustainability. Additionally, the complexity of managing and optimizing these colossal models adds layers of technical challenges, complicating their adaptation and deployment across different platforms and applications. The dual pressures of escalating costs and operational complexity underscore the need for innovative approaches to model scaling.
Brief Overview of MoE-LLaVA’s Approach to Efficient Scaling
In response to these challenges, MoE-LLaVA introduces a groundbreaking approach that reimagines the paradigm of model scaling. By integrating the Mixture of Experts (MoE) architecture within LVLMs, MoE-LLaVA proposes a solution that decouples parameter growth from computational expense. This architecture selectively activates only the most relevant subsets of parameters (experts) for a given task, thereby optimizing computational resources without compromising the model’s capacity or performance. The MoE-tuning strategy, central to MoE-LLaVA, refines this concept through a specialized training regimen that prepares the model to leverage its sparse structure effectively. This innovative approach promises to sustain the trajectory of LVLM advancements while mitigating the computational and environmental costs associated with traditional scaling methods. MoE-LLaVA thus stands as a testament to the potential for efficient, scalable AI development, heralding a new era of environmentally conscious and resource-efficient LVLMs.
Abstract
Challenge of Scaling LVLMs
The rapid advancement in Large Vision-Language Models (LVLMs) has unlocked new frontiers in AI capabilities, blending visual understanding with linguistic context to enable more intuitive and powerful interactions between machines and the visual world. However, the quest for higher accuracy and broader applicability has led to an exponential increase in model size and complexity. This scaling up, while beneficial for performance, imposes significant computational costs, making training and deployment increasingly resource-intensive. The challenge lies not just in achieving state-of-the-art performance but doing so in a manner that is computationally efficient and scalable.
MoE-tuning Strategy and MoE-LLaVA Framework
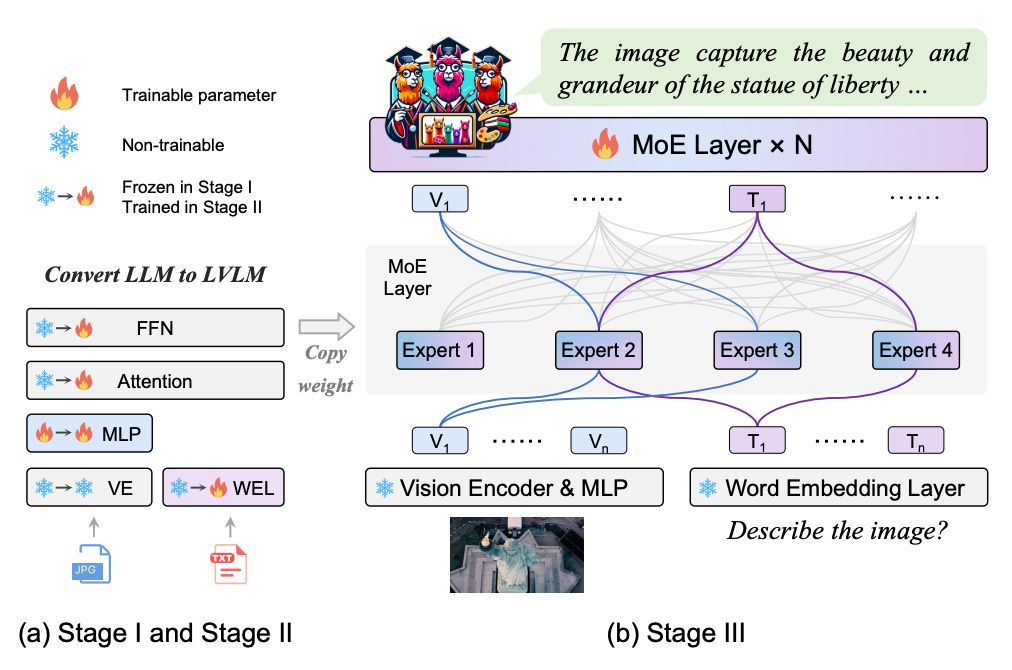
To address the computational challenges associated with scaling LVLMs, researchers have propose a novel training strategy termed “MoE-tuning,” alongside the introduction of the MoE-LLaVA framework. The essence of MoE-tuning lies in its ability to construct sparse models that leverage a Mixture of Experts (MoE) architecture, enabling the model to scale in parameter size without a proportional increase in computational demand. The MoE-LLaVA framework embodies this strategy by selectively activating only a subset of parameters (the ‘experts’) for each task, thereby keeping the computational cost manageable while still harnessing the benefits of a large parameter space.
Achieved Results and Contributions
Researchers extensive experiments demonstrate that MoE-LLaVA, with its sparse activation mechanism, not only matches but in some cases surpasses the performance of traditional dense LVLMs, including on benchmarks for visual understanding tasks. Remarkably, it achieves this with a fraction of the computational cost typically associated with models of comparable size. This breakthrough offers a new paradigm for scaling LVLMs, balancing the dual objectives of enhancing performance and optimizing computational efficiency. The MoE-LLaVA framework sets a new standard for future research in the field, providing a scalable and efficient pathway for advancing LVLM capabilities. Our work contributes to the broader discourse on model efficiency, pushing the boundaries of what is possible in the realm of vision-language AI.