

Python Faker Tutorial: Synthetic Data Creation
Data privacy and application testing can be achieved by generating synthetic data using python faker

Synthetic Data: What is it?
Unlike real-world data, synthetic data is generated by computers. Synthetic data is primarily used to increase system security and integrity. Companies must implement data protection strategies to protect Personally Identifiable Information (PII) and Personal Health Information (PHI). In addition to protecting user privacy, synthetic data can be used to test new applications.
To improve the performance of machine learning models, we use synthetic data. It is also applicable to situations with scarce or unbalanced data. Machine learning uses synthetic data for self-driving cars, security, robotics, fraud protection, and healthcare.
Approximately 60% of data used for machine learning and analytical applications will be synthetically generated by 2024, according to Gartner. Why is synthetic data on the rise?
In some cases, real-world data is hard to collect and clean because it is costly. The real world rarely has data on bank fraud, breast cancer, self-driving cars, and malware attacks. Data cleaning and processing for machine learning will take time and resources even if you get the data.
First, we’ll learn why synthetic data is needed, how it’s used, and how it’s generated. Using the Python Faker library, we will create synthetic data for testing and maintaining user privacy in the final part of this tutorial.
Synthetic Data: Why is it Needed?
The purpose of synthetic data is to protect user privacy, test applications, improve model performance, represent rare cases, and reduce operating costs.
Privacy. Users’ data must be protected. A synthetic data file can be used in place of names, email addresses, and addresses. It will help us avoid cyberattacks and black-box attacks that infer training data details from models.
Testing. The cost of testing applications on real-world data is high. It is more cost-effective and secure to test databases, user interfaces, and artificial intelligence applications on synthetic data.
Model Performance. The performance of models can be improved by using synthetic data generated by the model. Image classifiers, for example, increase the size of the dataset and improve model accuracy by shearing, shifting, and rotating images.
Rare Cases. It is not possible to wait until a rare event occurs before collecting real-world data. Detecting credit fraud, detecting car accidents, and detecting cancer.
Cost. It takes time and resources to collect data. Testing and training models require the acquisition, cleaning, labelling, and preparation of real-world data.
Applications based on synthetic data: what are they?
Throughout this section, we’ll explore how companies use synthetic data to build high-performance, cost-effective applications.
Data Sharing. Synthetic data makes it possible for enterprises to share sensitive information internally and with third parties. Data can also be moved to the cloud and retained for analysis.
Financial service. Using synthetic data, frauds can be simulated, anomalies can be detected, and economic recessions can be simulated. Through analytics tools, it is also possible to understand customer behaviour.
Quality Assurance. Testing and maintaining the quality of applications and data systems. Using synthetic data, systems are tested for rarer anomalies and performance is improved.
Healthcare. Maintain patient confidentiality while sharing medical records internally and externally. Detecting rare diseases and conducting clinical trials can also be done with it.
Automotive. Self-driving cars, drones, and robots have difficulty getting real-world data. By using synthetic simulation data, companies can test and train their systems without compromising performance and save money on building solutions.
Machine Learning. The use of synthetic data is useful for increasing training dataset size, resolving imbalance data problems, and testing models for accuracy and performance. Image and text data are also subjected to this process to reduce bias. In addition to allowing us to maintain user privacy, it will help us test systems. Facial recognition systems are tested using DeepFake, for example.
Data Synthesis: How to Generate It
Synthetic data can be generated using fake data generators, statistical tools, neural networks, and generative adversarial networks.
Test databases and systems using fake databases created using Faker library. A fake user profile can be generated with all the necessary information, including addresses. In addition to generating random text and paragraphs, you can also use it to generate random numbers. Users’ privacy is protected during the testing phase, and real-world datasets are acquired at a lower cost.
Using statistical tools such as Gaussian, Exponential, Chi-square, T, lognormal, and Uniform to generate a completely new dataset. To generate synthetic data based on distributions, you need subject knowledge.
Variational Autoencoder is an unsupervised learning technique that combines encoders and decoders to compress and represent an original dataset. Input and output datasets are correlated to maximize efficiency.
Most data is generated using Generative Adversarial Networks. The software can be used to render synthetic images, sounds, tabular data, and simulation data. Synthetic data is generated by comparing random samples with actual data using a generator and discriminator deep learning model architecture.
What is Python Faker?
An open-source Python package called Python Faker creates fake datasets that can be used for testing applications, bootstrapping databases, and maintaining user anonymity.
Faker can be installed using the following methods:

Besides command line support, Faker supports Pytest fixtures, localization, reproducibility, and a dynamic provider (which can be customized to fit your requirements).
As well as creating a quick dataset, Faker allows you to customize it to meet your needs. You can find various Faker functions and their purposes in the table below.

These functions will be used to create various examples and dataframes, so it is important to review them.
With Python Faker, you can generate synthetic data
We will generate synthetic data using Python Faker in this section. This document contains five examples of how to use Faker for various tasks. For testing systems, a privacy-centric approach is the main objective. To complement the original data, we will generate fake data using Faker’s localized provider in the last part.
The first thing we will do is initiate a fake generator by calling `Faker()`. Default locale is “en_US”.

The first example
Property names can be used to generate data for the “fake” object.A random person’s full name can be generated using a function called fake.name().

In the same way, we can generate fake email addresses, country names, text, geolocations, and URLs.

the output will be:

The second example
The data can be generated in a variety of languages and for different regions using different locales.
The following example generates data in Spanish and in the region of Spain.
fake = Faker("es_ES")
print(fake.email())
print(fake.country())
print(fake.name())
print(fake.text())
print(fake.latitude(), fake.longitude())
print(fake.url())Final product
Here, we can see that both the name and text of the individual have changed.
casandrahierro@example.com
Tonga
Juan Solera-Mancebo
Cumque adipisci eligendi aperiam. Quas laboriosam amet at dignissimos. Excepturi pariatur ipsam esse.
89.180798 -2.274117
https://corbacho-galan.net/Here’s a new attempt using the German language and Germany as the country. Using the profile() function, we can create a complete user profile.
fake = Faker("de_DE")
fake.profile()Results
There is no doubt that Faker can generate data in a variety of languages for a variety of countries. Name, job, address, company, and other user identification data will change when you change your locale.
{'job': 'Erzieher',
'company': 'Stadelmann Thanel GmbH',
'ssn': '631-64-0521',
'residence': 'Leo-Schinke-Allee 298\n26224 Altötting',
'current_location': (Decimal('51.5788595'), Decimal('29.780659')),
'blood_group': 'B+',
'website': ['https://www.schmidtke.de/',
'https://roskoth.com/',
'http://www.textor.de/',
'https://www.zirme.com/'],
'username': 'vdoerr',
'name': 'Francesca Fröhlich',
'sex': 'F',
'address': 'Steinbergallee 13\n84765 Saarbrücken',
'mail': 'smuehle@gmail.com',
'birthdate': datetime.date(1998, 3, 19)}The third example
We will use Faker to create a pandas dataframe in this example.
Create an empty pandas dataframe (data)
To create multiple rows, pass it through a number of loops
To generate unique identifiers, use Randint()
Create names, addresses, and geolocations with Faker
The input data function can be run with x equal to 10 using the function input_data()
from random import randint
import pandas as pd
fake = Faker()
def input_data(x):
# pandas dataframe
data = pd.DataFrame()
for i in range(0, x):
data.loc[i,'id']= randint(1, 100)
data.loc[i,'name']= fake.name()
data.loc[i,'address']= fake.address()
data.loc[i,'latitude']= str(fake.latitude())
data.loc[i,'longitude']= str(fake.longitude())
return datainput_data(10)There is no doubt that the output is incredible. There are columns for ID, name, address, latitude, and longitude with unique information about each user.
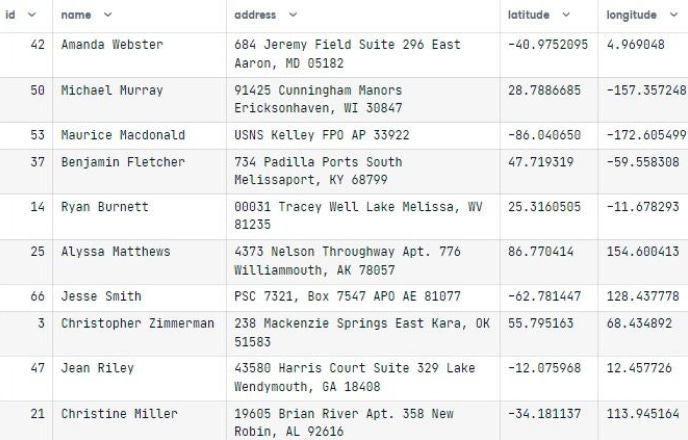
The seed must be set in order to reproduce the result. We will get the same results if we run the code cell again.
Faker.seed(2)
input_data(10)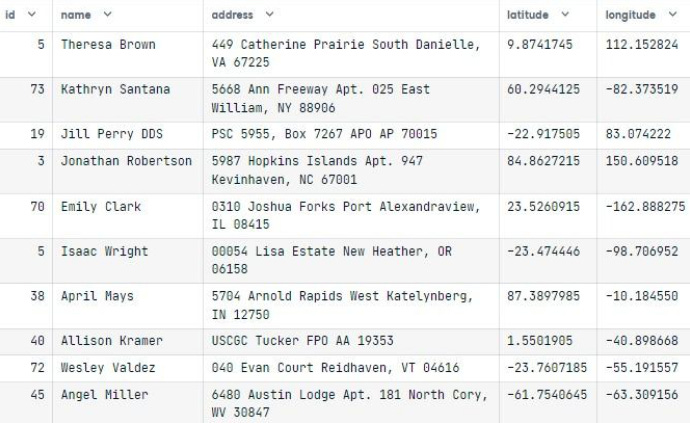
The fourth example
Alternatively, we can create a sentence containing our own keywords. As with `text(), texts(), paragraph(), word(), and words()`. By setting the nb_words argument, you can increase the number of words in a sentence.
The following example generates five sentences using a word list. Although it’s not perfect, it can help us test applications that need a lot of text data.
word_list = ["DataCamp", "says", "great", "loves", "tutorial", "workplace"]for i in range(0, 5):
print(fake.sentence(ext_word_list=word_list))Output:
Loves great says.
Says workplace workplace tutorial great loves.
Loves workplace workplace loves workplace loves great DataCamp.
Loves says workplace great.
Workplace great DataCamp.