

Tesla’s Self Driving Algorithm Explained For Dummies
Let's Understand the basics

Version 1
At the start of autonomous driving development, the main objective was to let the car move forward within a single lane and keep a fixed distance from the car in front. At that time, all of the processing was done on an individual image level.
So how can we detect cars or lanes in images?
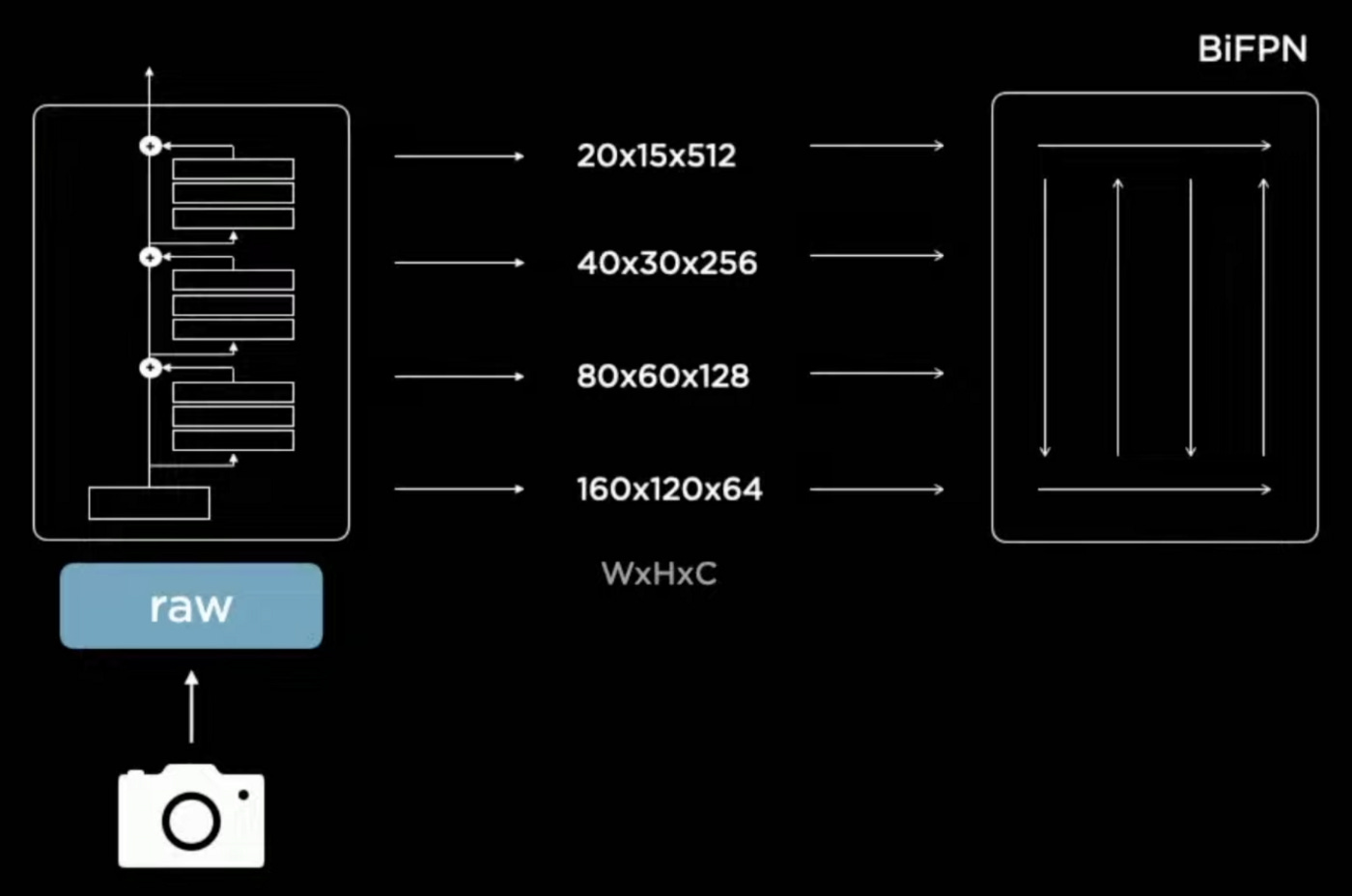
The Feature Extraction Flow or Neural Network Backbone
The raw images of the car camera are processed by a residual neural network (RegNet) that extracts multiple blocks or feature layers in width (W) x height (H) x channel (C).
The first feature output has a high resolution (160 x 120) and focuses on all the details in the image. Moving all the way to the top layer, with a low resolution (20 x 15) but with a greater channel count (512). Intuitively, you could visualize each channel as a different filter that activates certain parts of the feature map or image, for example, one channel puts more emphasis on edges and another on smoothing parts out. Therefore, the top layer puts more focus on the context by using a variety of channels. Whereas, the lower layer focuses more on the details and specifics by using a higher resolution.
