

The Complexity of Text-Based Computer Games
Advancements in LLMs Revolutionizing Game Interactions

Article #65
The Complexity of Text-Based Computer Games
The introduction of this paper discusses the complexity and interactivity of text-based computer games, where the game’s state, including location, scenes, and dialogue. Players interact with non-player characters (NPCs) to achieve specific goals. Traditionally, these NPCs are pre-scripted, which limits user inputs to text commands and results in rigid interactions. However, recent advancements in large language models (LLMs) have revolutionized text-based games by enabling dynamic interactions between players and NPCs. Major companies have started releasing LLM-powered “character engines” that allow for adaptive, unscripted NPCs with backstories, goals, emotions, and free-form conversations. These advancements extend beyond NPCs to include other game design aspects such as level generation.
Message for paid users at the end of this article.
Link to Research Paper
This article is based on the research paper "Automatic Bug Detection in LLM-Powered Text-Based Games Using LLMs" by Claire Jin (Carnegie Mellon University), Sudha Rao, Chris Brockett, Bill Dolan (Microsoft Research), Xiangyu Peng (Salesforce Research), and Portia Botchway, Jessica Quaye (Harvard University). Their work advances the detection of bugs in text-based games using large language models, enhancing game interactivity and player experience.
Read the original research paper here: https://arxiv.org/pdf/2406.04482
Challenges and Opportunities in LLM-Powered Games
Despite the flexibility and adaptability of LLM-powered games, they also introduce opportunities for logical inconsistencies, hallucinations, and memory-loss mistakes. To ensure the playability of these games, it is crucial to automatically detect these bugs. The focus of this work is on logical and game balance bugs. Logical bugs involve flaws in the logic implementation, leading to unexpected outcomes without interface crashes. Game balance bugs are deviations from the designers’ intentions, making games either too challenging or too easy. Traditional bug detection has primarily focused on graphics bugs, crashes, or freezes, with little attention to logical and game balance bugs.
Player Feedback and Game Logs
Player feedback surveys and game designer discretion have traditionally been used to identify these bugs, but they require significant effort and offer limited insights. To address this gap, the authors develop an LLM-powered method to automatically detect player pain points and associated game logic and game balance bugs from game logs. Unlike player surveys, which rely on players’ post-game recollection, game logs are generated during gameplay, providing richer insights by capturing real-time player actions and dialogue.
Complexity of Identifying Bugs
Identifying game logic or balance bugs from logs of text-based games is a complex task. It requires synthesizing multiple sources of information, inferring intentions from player actions, and identifying subtle causal relationships between player behavior and game outcomes. This task remains challenging, even for humans. The authors leverage LLM’s language reasoning to address this challenge. However, feeding game logs directly into an LLM does not yield meaningful identification of logic and balance bugs due to the task’s complexity. Therefore, they develop a structured approach that uses the game designer’s intended gameplay to guide an LLM in mapping diverse gameplay attempts to a unified framework. This approach enables the aggregation of gameplay experiences across players to identify potential game logic and balance bugs.
Contributions of the Work
The main contributions of this work are twofold: first, they present a novel method of automatically assessing LLM-powered text-based games for logical and game balance bugs arising from LLM-driven NPC dialogue and plotlines. To their knowledge, this is the first method for this task. Second, their method provides objective, quantitative, and scalable assessments of the difficulties of each game part in a text-based game.
Case Study: DejaBoom!
In this section, the authors discuss their method by testing it on a recently published text-based mystery game called “DejaBoom!” The game employs a plot-constrained version of GPT-4 to generate all in-game text, including descriptions of the game state, outcomes of player actions, and dialogues with non-player characters (NPCs). This text generation is powered by a large language model (LLM).
Gameplay Mechanics
The game starts with the player waking up at home in a village, experiencing a sense of “deja vu” about an explosion. To win the game, the player needs to find a bomb disposal kit and locate the bomb to diffuse it. The player must explore the village, interact with NPCs, and examine items to figure out how to solve the mystery. Some NPCs and items are helpful for solving the mystery, while others are misleading.
Log Analysis
The bomb explodes after a set number of gameplay steps, specifically 30 steps, where each step represents a single in-game player action or utterance. This causes the player to relive the day until they successfully diffuse the bomb. Although the player retains memory across these explosions, the game world and NPCs reset after each explosion.
Study by Peng et al.
The authors reference a study by Peng et al. (2024), which released game logs for 28 players. These logs include all player text inputs and game engine outputs during their gaming sessions. The logs provide detailed information about player actions and utterances, NPC dialogues, and the current game state, such as location, inventory, and outcomes of player actions. Additionally, Peng et al. published post-study survey responses from the players, offering further insights into their experiences and feedback on the game.
Automated Bug Detection Procedure
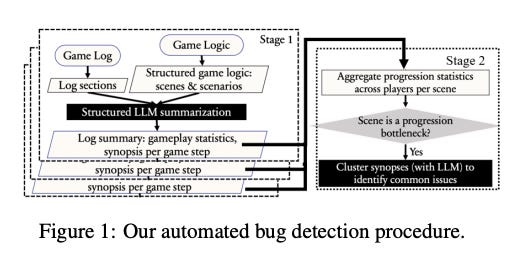
The automated bug detection procedure described in the text involves analyzing players’ game logs and comparing them to the designer’s intended game logic to identify bugs. This process is powered by a two-stage procedure using a large language model (LLM), as illustrated in Figure 1. In the first stage, a structured approach is used to prompt the LLM to map various player attempts recorded in a game log to the designer’s intended progression roadmap. This helps extract information on the player’s progression and gameplay experience, which is then summarized into a standardized format that can be compared across different players and gameplay steps. In the second stage, the LLM aggregates these summaries to quantify the difficulties of each game progression unit, identify common progression bottlenecks, and pinpoint issues related to player logic and game balance.
Game Logic Structure
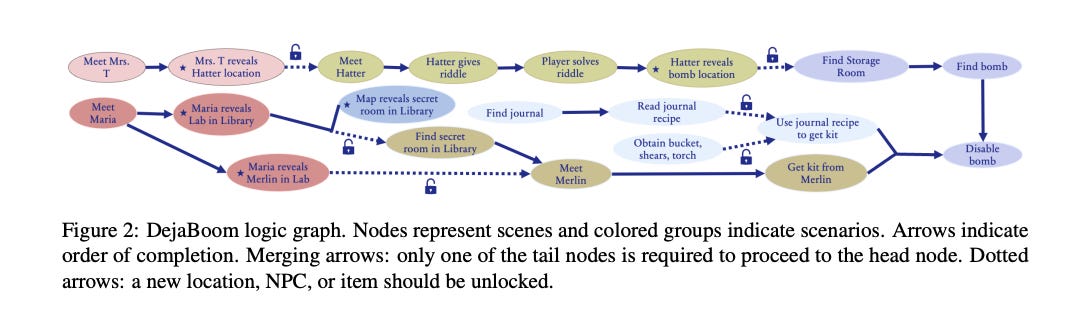
To achieve this, the game logic is segmented into “scenarios,” each representing a plotline segment with a specific aim necessary for progression. These scenarios are further divided into “scenes,” each with a distinct goal requiring a specific action or utterance from the player. Figure 2 shows the game logic graph of DejaBoom!, illustrating the node relationships and the structure of the intended game flow. This graph helps align player progress recorded in the game log with the intended game flow, leveraging the LLM’s reasoning capabilities.
Preprocessing and Summarization

The raw game logs are preprocessed by removing extraneous details and redundant information, and adding tags for non-player character (NPC) utterances, player input, and game world feedback. These preprocessed logs are then segmented into sections of two consecutive gameplay steps, each comprising a single player action or utterance, as shown in Figure 3a. This segmentation provides the LLM with additional temporal context, enhancing its ability to understand sequential progression.
The LLM is then instructed to generate a structured summary for each gameplay step, outlining the player’s action and outcome in a one-sentence synopsis. This summary maps the player’s progress to a scene of the game logic graph, recording completed scenes and assessing whether the step contributes to progression. These summaries are used to compute difficulty metrics for each scene in the second stage.
Few-Shot Learning and Consistency Checks
To train the LLM for this task, a few-shot learning protocol is employed, using 60 curated summaries as in-context training examples. All LLM-generated summaries undergo an automated legality check to ensure temporal consistency within each log. Figure 3b shows an example of an LLM-generated summary for a gameplay step, demonstrating how the LLM maps player actions to the game logic and assesses progress.
Identifying Pain Points
In Stage 2, the goal is to identify pain points and their causes within a scene. To do this, we first gather the summaries from Stage 1, as shown in Figure 3b, which are produced by players for each scene. We then calculate the completion rates for these scenes. If a scene has a low completion rate or a significant drop in completion rate compared to the previous scene, it is flagged as a potential pain point. Additionally, scenes with unusually high completion rates are also flagged, as this might indicate a deviation from the designer’s intent.
For each flagged scene, we use a large language model (LLM) to cluster the one-sentence synopses generated in Stage 1. These synopses summarize player actions, experiences, and outcomes across different players. By grouping synopses with similar semantic content, the LLM forms clusters that represent various common experiences encountered during gameplay in a particular scene. These clusters help reveal common player attempts, outcomes, and obstacles, which in turn facilitate the identification of specific causes of hindrances.
Completion Rate Analysis

Figure 4 provides a visual representation of this process. In part (a), the bar chart shows the completion rate for each scene, with black brackets grouping scenes that form a scenario. Stars mark potential pain point scenes. The chart indicates the percentage of players who completed each node, with some nodes having significantly lower completion rates, marked by arrows.
Parts (b) and (c) of Figure 4 show the clusters identified for the scenes marked by arrows in part (a). In part (b), the clusters are related to the scene “Merlin gives kit,” where players faced various issues such as being refused the kit without a good reason, being told they need evidence of deception, or trying to show evidence but being ignored. In part ©, the clusters pertain to the scene “Mrs. T reveals Hatter in Park,” where players asked Mrs. T about the Mad Hatter, a bomb, or any suspicious activity but did not receive useful information, or they asked other NPCs about the Mad Hatter’s location and learned he could be found in the park. These clusters help pinpoint the specific causes of player difficulties in these scenes.
Detailed Analysis of Bottlenecks
In this section, we delve into identifying common causes of bottlenecks in the game by analyzing the resultant clusters from Stage 2 for two specific flagged scenes, with additional details provided in Appendix A.4.
For the scene titled “Merlin gives kit” (illustrated in Figure 4b), clusters (a) through (d) highlight logic bugs where the behavior of NPC Merlin deviates from what players expect. Specifically, Merlin incorrectly identifies NPC James and Ingredient X, which are meant to be red herrings, as necessary components for obtaining the bomb disposal kit. This misdirection hampers player progress. Clusters (e) and (f) reveal player confusion during game exploration, particularly when players attempt to get a kit from Merlin despite already possessing one. This suggests a potential balance issue if a significant number of players waste time trying to acquire an unnecessary item due to the game design.
In the “Mrs. T reveals Hatter in Park” scene (depicted in Figure 4c), clusters (a) to © expose a balance bug where Mrs. Thompson only accepts the keyword “explosion” to unlock player queries, thereby increasing the scene’s difficulty by excluding synonymous terms like “bomb.” Cluster (d) identifies a logic bug in the LLM game engine, which mistakenly allows NPCs other than Mrs. T to disclose the Hatter’s location to the player. However, the player cannot unlock the Hatter because the unlocking condition is tied to Mrs. T’s disclosure.
Validation and Comparison
To validate the bugs detected by our method against those identified via survey and manual parsing, we conducted a survey-based ground truth along with an inspection of game logs. Players reported seven bugs in the survey, five of which were detected by applying Stage 2 of our method to the flagged scenes (Figure 4a). When we extended the clustering step in Stage 2 to additional scenes, the remaining two bugs were also uncovered. Out of the seven potential pain point scenes identified by our method, five were corroborated by the survey. The remaining two scenes involved NPC Maria, who received general complaints in the survey without specific bug reports. These findings suggest that our method aligns with player feedback surveys but offers greater specificity. Consequently, our method not only eliminates the need for manual feedback collection and parsing but also provides deeper insights into player experience beyond typical survey feedback. Further details of the survey and comparison analysis can be found in Appendix A.6.
Ablation Studies
In this section, the authors discuss two ablation studies conducted to compare different methods for identifying and summarizing parts of a game where players encounter logic or balance bugs. The first method lacks the game logic structure but retains the summarization structure, while the second method lacks the summarization structure but retains the game logic structure. In both methods, the goal is to extract “game parts” — specific sections of the game where players might struggle — and identify the bugs within those sections.
In the first method, the large language model (LLM) is tasked with identifying game parts that players struggled with and writing a prose summary for each section. In the second method, the LLM follows a predefined summary structure but assigns game-play steps to game parts dynamically, rather than relying on pre-defined scenes. The same log sections are used in all experiments, with new in-context examples provided for each experiment.
Both methods have significant shortcomings. Quantifying the difficulty of game parts is challenging due to the lack of standardized progression units for aggregating player experiences. Without predefined scenarios and scenes, the LLM often reports the player’s game step (a single action or utterance and its immediate consequence) as the game part. This makes it difficult to compare across players or sessions. The table in the image, Table 1, shows that the two ablation methods report a much larger number of unique game parts than the authors’ method. Many of these unique parts overlap with respect to the game sequence, such as “acquiring the disposal kit from Merlin” and “acquiring the disposal kit through non-violent means,” which are essentially the same but not obvious without context. Manual post-processing with game knowledge would be required to reconcile these parts for accurate difficulty quantification. Additionally, many identified game parts are irrelevant to game logic or overly vague, such as “attempting to sit on a non-existent bench” or “lack of progress towards objectives.”
The first ablation method also presents challenges in extracting common causes of player struggles compared to the second method. The prose summary in the first method requires laborious parsing and reasoning to extract relevant information, which can be infeasible. This demonstrates the effectiveness of the structured summarization in the authors’ method. The table also indicates that the authors’ method is more effective in aggregating game parts and revealing specific causes of bugs, with only 20 unique game parts identified compared to 661 and 400 in the two ablation methods, respectively. The authors’ method also allows for easy aggregation and reveals bug causes, unlike the other two methods. Further discussion on the shortcomings of the ablation methods is provided in Appendix A.7.
Conclusion and Future Directions
In this study, the researchers used OpenAI’s GPT-4 as the language model (LLM), which was selected because it is considered a state-of-the-art (SOTA) model. The choice of GPT-4 was due to its advanced capabilities, but it is important to note that the results might vary if different LLMs were used. The study acknowledges that there is a lack of other similar works in this area, which limited the researchers to comparing their methods with potential alternatives rather than established published methods.
The game “DejaBoom!” was used in this study, and it was designed and played in English. The interactional behaviors observed were from English-speaking players based in the United States, and all game logs were in English. This means that while the framework developed in this study can be applied to other games and game logs in different languages, its effectiveness might be influenced by the LLM’s ability to handle languages other than English.
The framework has only been tested on the “DejaBoom!” game so far, but the researchers believe it can be smoothly transferred to other adventure games. They point out that common issues in adventure games, such as progression bottlenecks, are what their framework is designed to identify and address. The framework can be adapted to other adventure games by modifying how it parses game logic and logs. However, for other types of games, additional adjustments might be necessary to ensure the framework’s effectiveness.