

The Machine Learning Landscape
In this comprehensive guide, we delve into the intricacies of Machine Learning, particularly focusing on the relationship between life satisfaction and GDP per capita across various countries.

The article starts by setting up the environment for data visualization using the matplotlib library in Python, ensuring that plots are both informative and visually appealing.
The core of the analysis involves utilizing the Python libraries numpy for numerical operations, pandas for data manipulation, and sklearn for implementing machine learning models. The data, sourced from the OECD’s Better Life Index and the World Bank, is methodically prepared and processed. This includes filtering, merging, and structuring the datasets for optimal analysis.
The article presents a thorough exploration of linear regression and K-Nearest Neighbors regression models to understand and predict life satisfaction based on GDP per capita. It includes practical demonstrations of these models, offering insights into their predictions for specific countries like Cyprus.
Further, the article highlights the importance of data preparation and preprocessing, showcasing the process of downloading, cleaning, and structuring data for effective machine learning applications. It also addresses the challenges of overfitting and demonstrates the use of model parameters to fine-tune predictions.
Finally, the guide concludes with a discussion on different regression models, including regularized linear models, and their implications on the analyzed data. This technical article serves as a detailed resource for understanding the practical applications of machine learning in analyzing real-world data.
There is no source code to download. This is a step by step, for giving you basic experience in machine learning.
Setup
Let’s define the default font sizes, to plot pretty figures:
import matplotlib.pyplot as plt
plt.rc('font', size=12)
plt.rc('axes', labelsize=14, titlesize=14)
plt.rc('legend', fontsize=12)
plt.rc('xtick', labelsize=10)
plt.rc('ytick', labelsize=10)This code imports the matplotlib.pyplot library and sets the default font size to 12. Then, it sets the sizes of the labels and titles on axes to 14, the font size for legends to 12, and the label sizes for the x and y tick marks to 10. The purpose of this code is to set the default visual settings for matplotlib plots to specific values.
Make this notebook’s output stable across runs:
import numpy as np
np.random.seed(42)This code imports the numpy library under the alias np and sets a random seed at 42. This ensures that the random numbers generated by numpy will be the same every time the code is run. This is useful for reproducibility in data analysis and experimentation.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# Download and prepare the data
data_root = "https://github.com/ageron/data/raw/main/"
lifesat = pd.read_csv(data_root + "lifesat/lifesat.csv")
X = lifesat[["GDP per capita (USD)"]].values
y = lifesat[["Life satisfaction"]].values
# Visualize the data
lifesat.plot(kind='scatter', grid=True,
x="GDP per capita (USD)", y="Life satisfaction")
plt.axis([23_500, 62_500, 4, 9])
plt.show()
# Select a linear model
model = LinearRegression()
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[37_655.2]] # Cyprus' GDP per capita in 2020
print(model.predict(X_new)) # outputs [[6.30165767]]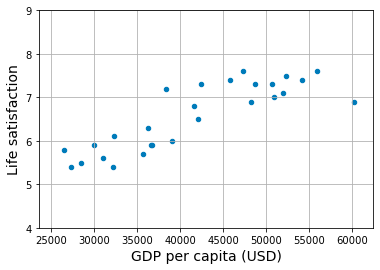
This code is using various packages and modules in Python to perform a linear regression analysis on data related to life satisfaction and GDP per capita in different countries. First, the code imports the necessary packages for this analysis — matplotlib for data visualization, numpy for working with arrays and data, pandas for data manipulation and analysis, and the linear regression model from sklearn. Next, the code downloads the data from a GitHub repository and prepares it for analysis. It then selects the two columns of interest — GDP per capita and Life satisfaction — and converts them into numpy arrays. The code then uses the matplotlib package to plot a scatter plot of the data, showing the relationship between the two variables. It also sets the x and y-axis limits for better visualization. Next, a linear regression model is selected and trained on the data using the fit function. This allows the model to learn the relationship between GDP per capita and life satisfaction. Finally, the code makes a prediction for a new data point — the GDP per capita for Cyprus in 2020 represented as an array. The predicted life satisfaction score for this data point is then printed to the console.
# Select a 3-Nearest Neighbors regression model
from sklearn.neighbors import KNeighborsRegressor
model = KNeighborsRegressor(n_neighbors=3)
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
print(model.predict(X_new)) # outputs [[6.33333333]]
This code imports the 3-Nearest Neighbors regression model from the sklearn.neighbors library and assigns it to the variable model. Then, it trains the model using the independent variable X and the dependent variable y. After training the model, it makes a prediction for a new set of data represented by X_new. The output of this prediction is the predicted value for Cyprus, which is in this case 6.33333333.
Load And Prepare Life Satisfaction Data
To create the lifesat.csv file, two primary data sources were utilized. The first source is the Better Life Index (BLI) data, which was obtained from the OECD's official website. This dataset provides information on Life Satisfaction for each country. The second source is the World Bank GDP per capita data, sourced from OurWorldInData.org. The BLI data, specifically from the year 2020, is stored in datasets/lifesat/oecd_bli.csv, and the GDP per capita data, which includes records up to 2020, is located in datasets/lifesat/gdp_per_capita.csv.
For those interested in accessing the most recent versions of these datasets, they are available for download. However, it’s important to note that there might be variations, such as changes in column names or the availability of data for certain countries. Consequently, adjustments to the code may be necessary to accommodate these updates.
import urllib.request
datapath = Path() / "datasets" / "lifesat"
datapath.mkdir(parents=True, exist_ok=True)
data_root = "https://github.com/ageron/data/raw/main/"
for filename in ("oecd_bli.csv", "gdp_per_capita.csv"):
if not (datapath / filename).is_file():
print("Downloading", filename)
url = data_root + "lifesat/" + filename
urllib.request.urlretrieve(url, datapath / filename)This python code imports the urllib library and creates a path variable named datapath using the Path function. The datapath variable is then used to specify the location where the downloaded data will be stored. Next, the code creates a new folder named datasets inside the datapath location using the mkdir function. If the folder already exists, the exist_ok=True parameter ensures that the code does not throw an error. The code then sets a variable named data_root to the URL https://github.com/ageron/data/raw/main/ which is the root location of the data files that will be downloaded. Next, the code enters a for loop which iterates through the list of file names oecd_bli.csv and gdp_per_capita.csv and checks if the file already exists in the datapath location. If the file does not exist, the code prints a message to inform the user that the file is being downloaded and sets a variable named url to the full URL of the file to be downloaded. Finally, the urllib librarys urlretrieve function is used to download the file from the specified url and save it in the datapath location with the same filename.
