

The Scrapers' Toll: Analyzing the Economic and Infrastructural Impact of AI Web Crawlers on the Digital Ecosystem
Introduction: The Paradigm Shift in Web Crawling


The Old Covenant: A Symbiotic Web
For decades, the architecture of the open web has been predicated on an unwritten but widely understood covenant between content creators and search engines. This symbiotic relationship, primarily defined by crawlers like Googlebot, formed the economic bedrock of the digital information age. Website operators, from individual bloggers to multinational media corporations, created and hosted content. In exchange for access to this content, search engine crawlers would index it, making it discoverable to a global audience. The critical component of this value exchange was the reciprocal flow of traffic. Search engines did not merely consume data; they acted as a global directory, driving monetizable human users back to the original source websites.
This arrangement created a powerful, positive feedback loop. Increased content production led to better search results, which in turn drove more traffic to content creators, who could then monetize that traffic through advertising, subscriptions, or e-commerce. This model, while not without its flaws, directly funded the creation of the vast repository of information, art, and commerce that characterized the open web. The act of crawling was understood to be a precursor to value creation for both parties. The crawler was a visitor that promised to send many more visitors in its wake. This fundamental assumption of reciprocity underpinned website architecture, business models, and the very philosophy of a freely accessible internet.
The New Paradigm: The Rise of the Extractive AI
The emergence of web crawlers designed to feed Large Language Models (LLMs) represents not an evolution of the old paradigm, but its wholesale demolition. These new bots, driven by the near-insatiable data appetite of the artificial intelligence industry, operate on a purely extractive basis, shattering the symbiotic relationship that built the modern web. Their purpose is not to index content for referral but to "strip-mine" the web for any and all content to be used as a training corpus for proprietary AI models. This marks a fundamental disruption of the web's foundational social and economic contract.
The value exchange is no longer reciprocal; it is unilateral. The data's value is not realized when a human user visits the source page, but rather when it is absorbed and synthesized within the closed, proprietary environment of an LLM. The AI crawler is not an intermediary that facilitates traffic; it is a terminal consumer of the data asset. It takes the value—the text, the images, the code, the ideas—and provides nothing in return. This transforms the relationship from a symbiotic one into a parasitic one. The AI firm captures 100% of the value derived from the content, while the content creator is left to bear 100% of the cost of serving the data, with no resulting traffic, revenue, or attribution. This report will demonstrate that this is not merely a technical nuisance but a systemic economic threat that is actively degrading website performance, inflating operational costs, and forcing a strategic re-evaluation of the future of open information online.
Report Objectives and Structure
This report will provide a comprehensive analysis of the multifaceted crisis precipitated by AI web crawlers. It will begin by dissecting the technical anatomy and behavior of these new bots, quantifying their scale and contrasting them with their traditional predecessors. It will then detail the cascading operational and economic impacts on websites of all sizes, from performance degradation to the imposition of a silent, involuntary subsidy on the entire digital publishing industry. Subsequently, the analysis will explore the failure of traditional defense mechanisms and evaluate the emerging countermeasures, highlighting the strategic schism between appeasement and confrontation. The report will conclude with strategic recommendations for key stakeholders and project potential future scenarios for the digital ecosystem, ultimately arguing that the internet has reached a critical inflection point that will determine the fate of the open web.
Anatomy of the AI Crawler: Behavior, Scale, and Intent
Quantifying the Invasion: A New Class of Traffic
The scale of the AI crawler phenomenon has fundamentally altered the composition of global internet traffic. The web is no longer a space primarily traversed by humans. According to data from the content delivery network Cloudflare, automated bots now account for a staggering 30% of all global web traffic. Within this massive segment, AI bots are not only the leading source but also the most rapidly growing category. This signifies a profound demographic shift in the web's user base, where a significant and expanding plurality of "visitors" are non-human, non-monetizable, and intensely resource-hungry machines.
Further analysis from cloud services company Fastly sharpens this picture, revealing that an overwhelming 80% of all AI-related bot traffic originates specifically from AI data fetcher bots. This data point is critical, as it isolates the problem squarely with the crawlers designed for LLM data ingestion, distinguishing them from other forms of automated traffic. The implication is that the internet's infrastructure is now being forced to serve a massive, non-revenue-generating "audience" that operates with relentless, 24/7 intensity and unpredictable, high-volume bursts. This invalidates many of the core assumptions upon which web architecture, server capacity planning, and analytics models have been built for decades, leading to a systemic misallocation of resources where capital is expended to serve bots that actively degrade the experience for the revenue-generating human users.
Behavioral Analysis: Aggression and Disregard for Protocol
The operational characteristics of AI crawlers distinguish them sharply from the relatively benign behavior of traditional search engine bots. Their conduct is frequently described as "aggressively strip-mining the web," a process characterized by high frequency, high volume, and a disregard for the established norms of the web community. Unlike traditional crawlers, which were programmed to crawl methodically and respect community-developed protocols, many modern AI crawlers operate with a singular focus on maximal data extraction in minimal time.
This aggression manifests in several ways. Firstly, they frequently ignore or override the directives in robots.txt files, such as Crawl-delay commands, which were designed to prevent crawlers from overwhelming a server. This voluntary protocol, long the cornerstone of crawler etiquette, is being rendered obsolete by bots that do not adhere to its principles. Secondly, their technical methods are far more resource-intensive. Instead of merely parsing HTML for links and metadata, these bots are designed to extract the full text of pages. Furthermore, they often attempt to execute and follow dynamic links or JavaScript, a process that consumes significantly more server-side CPU and memory than serving static content. This behavior mimics a resource-heavy human user but at a machine-driven scale and speed, placing an unprecedented and often unsustainable load on web servers.
Case Study: The Perplexity Protocol Dispute
The growing conflict over crawling etiquette is exemplified by the public dispute between infrastructure providers and AI companies. Cloudflare has specifically accused the AI search company Perplexity of ignoring robots.txt directives, a claim that points to a deliberate policy of aggressive data acquisition that flouts established web standards. While Perplexity has denied the accusation, the incident itself highlights the deep erosion of trust and the lack of transparency that now defines the relationship between AI firms and the broader web ecosystem. This is no longer a cooperative environment governed by "gentlemen's agreements" but an adversarial one where the actions of crawlers are suspect and their operators' claims are met with skepticism. This breakdown of protocol is a direct consequence of the immense commercial pressure to build ever-larger datasets for competitive LLM development, an imperative that appears to supersede any commitment to responsible digital citizenship.
A Tale of Two Bots: Traditional vs. AI Crawlers
To fully appreciate the paradigm shift, it is essential to contrast the profiles of traditional search engine crawlers with their modern AI counterparts. The following table distills these differences, illustrating why the latter represents a fundamentally new and economically hostile category of web traffic.

This stark contrast provides the foundational context for the rest of this analysis. It clarifies that the current crisis is not simply about "more bots," but about the rise of a new type of bot whose function and economic impact are diametrically opposed to the principles that have historically governed the open web.
The Ripple Effect: Quantifying the Impact on Website Operations
The Assault on Infrastructure: Performance Degradation and Service Disruption
The most immediate and tangible consequence of aggressive AI crawler traffic is the direct assault on web infrastructure. These bots are capable of hammering websites with traffic spikes that are 10 to 20 times normal levels, often materializing within minutes and sustaining for extended periods. This sudden, massive influx of requests overwhelms server resources, leading directly to the "performance degradation, service disruption, and increased operational costs" that have become endemic for site operators. Servers that are provisioned for predictable patterns of human traffic are simply not equipped to handle a machine-driven onslaught of this magnitude.
The technical impact rapidly translates into a severe business impact. As servers struggle to process the bot requests, page load times for legitimate human visitors increase dramatically. This latency is not a minor inconvenience; it is a critical failure point for user engagement and commerce. Research consistently shows that user patience is fleeting, and more than half of all visitors will abandon a website if it takes longer than three seconds to load. Each additional second of delay results in higher bounce rates, lower conversion rates, and diminished ad revenue. In this way, AI crawlers inflict a double penalty: they consume costly server resources while simultaneously driving away the very human users whose engagement is necessary to pay for those resources.
The Vulnerability of the Small Web
While the entire web is affected, the impact of AI crawlers is disproportionately felt by smaller entities and independent publishers. Many of these sites operate on shared hosting environments to manage costs. In this architecture, the resources of a single physical server (CPU, RAM, bandwidth) are divided among hundreds or even thousands of different websites. This creates a critical vulnerability: even if a specific site is not the primary target of an AI crawler, it can suffer severe "collateral damage" if another site on the same hardware is hit. The aggressive crawler consumes the server's shared resources, causing a significant drop in performance for every other site on that server.
This is not a theoretical risk. Smaller outlets, such as the example site "Practical Tech," are being knocked completely out of service by these bot-driven resource spikes. For an independent creator or a small business, such an outage can be catastrophic, leading to lost revenue, reputational damage, and the potential loss of their entire online presence. They lack the financial resources and technical expertise of larger corporations to provision dedicated servers or implement sophisticated mitigation strategies, leaving them acutely vulnerable to the indiscriminate harvesting of data by well-funded AI companies.
The Cost to the Enterprise
Even large, well-resourced enterprise websites are not immune to the financial drain imposed by AI crawlers. While they may have the capacity to withstand the traffic spikes without going offline, they are nonetheless forced to absorb significant and escalating operational costs. To maintain acceptable performance levels for their human visitors, these organizations must "increase processor, memory, and network resources" specifically to handle the massive load generated by non-monetizable AI bots.
This represents a direct and unwelcome line item on their operational budget. Capital that could be invested in product development, marketing, or customer service is instead diverted to over-provisioning infrastructure for the sole purpose of serving data to AI companies that will then use that data to compete against them. It is a forced, unreciprocated expenditure that provides no return on investment and acts as a direct subsidy from the enterprise to the AI industry.
The Economics of Unreciprocated Value Extraction
The central economic thesis of the AI crawler problem is the complete absence of reciprocal value. The traffic generated by these bots "cannot be monetized" by website owners in any traditional sense. This stands in stark contrast to the established model of search indexing crawlers, which, despite their own resource consumption, ultimately "direct users back to the original sources," creating an opportunity for website owners to generate income through advertising, e-commerce, or subscriptions.
AI crawlers break this economic loop entirely. They are effectively imposing an involuntary, unfunded mandate on every website operator, forcing them to subsidize the data acquisition costs of multi-billion dollar AI corporations. The process begins with the AI company seeking to minimize its primary input cost: training data. By aggressively scraping the web without compensation, these firms are externalizing the cost of data acquisition onto the global community of content creators. This externalized cost is not zero; it is simply transferred to website owners in the form of tangible expenses: higher bandwidth bills, the need for server hardware upgrades, increased fees for content delivery networks, valuable engineering hours spent on mitigation, and, most damagingly, the lost revenue from human users who abandon the slow, bot-congested site. In effect, every business, publisher, and creator running a website is now paying a "data tax" to support the research and development of the very AI firms whose products may one day render their own business models obsolete. This is a profound market distortion where the entity creating the value (the content) is forced to pay for its own asset to be taken and used against its interests.
The Failure of the Old Guard: Why Traditional Defenses Are Ineffective
The Gentlemen's Agreement is Dead: The Impotence of robots.txt
The robots.txt file has long been the primary mechanism for website administrators to communicate their crawling preferences to automated bots. However, it was never a security mechanism or an enforcement tool. It was, in essence, a "gentlemen's agreement"—a voluntary standard of etiquette based on the assumption that bot operators would act as responsible members of the web community. Its effectiveness was entirely dependent on the willingness of crawlers to comply.
The rise of AI crawlers, driven by intense commercial pressure for data, has shattered this cooperative model. Many of these new bots simply ignore the directives within robots.txt files, treating them not as a set of rules to be followed but as an inconvenience to be bypassed. The imperative to acquire vast datasets for training competitive LLMs outweighs any adherence to community-established protocols. Consequently,
robots.txt has been rendered largely impotent as a primary line of defense. Relying on it to control access in the modern web environment is akin to posting a "no trespassing" sign with no fence and no enforcement; it only deters those who were already inclined to be respectful.
Circumventing the Gatekeepers: Logins, Paywalls, and CAPTCHA
In response to unwanted automated access, website operators have historically deployed a range of gatekeeping mechanisms, including user logins, paywalls, and CAPTCHAs (Completely Automated Public Turing test to tell Computers and Humans Apart). For years, these tools provided a reasonably effective barrier against unsophisticated bots. However, the very technology that powers LLMs has also made AI exceptionally proficient at defeating these defenses.
Modern AI is now highly effective at "circumventing these protective measures". AI-powered tools can programmatically solve complex CAPTCHAs that were once thought to be a robust defense. They can identify and exploit weaknesses in simple login or paywall scripts, and in some cases, use headless browsers to simulate human interaction so perfectly that they can navigate through these gateways undetected. The gatekeepers of the old web were designed to distinguish between a simple script and a human; they are ill-equipped to handle an AI that can mimic human behavior with increasing fidelity.
The Limits of Brute-Force Defense
Even more robust security tools, such as traditional Distributed Denial of Service (DDoS) protection, are proving less effective against the new wave of AI crawlers. Standard DDoS mitigation is designed to handle volumetric attacks—massive floods of simple, easily identifiable malicious traffic, such as SYN floods or UDP reflection attacks. It works by identifying and blocking traffic based on crude patterns and known bad IP addresses.
AI bot attacks, however, are far more sophisticated. They are not a brute-force flood from a single source. Instead, they often employ a "low and slow" approach from a vast, distributed network of residential or cloud-based IP addresses, making them difficult to distinguish from legitimate traffic. Each request from an AI crawler can appear to be a valid page request from a real user's browser. They often use rotating user-agents and respect some site behaviors to further cloak their automated nature. This sophistication means they can often bypass the simple rule-based filters of traditional DDoS protection. This marks a fundamental shift in web security, from a "rules-based" to a "capabilities-based" posture. The old model, which relied on enforcing known protocols, is failing. The new reality is a purely adversarial technological conflict that requires adaptive, behavior-based defense systems, a capability that is often beyond the reach of smaller organizations and creates a new "security poverty line" on the web.
The New Front Line: An Analysis of Emerging Countermeasures
A New Protocol for a New Era? The llms.txt Proposal
In response to the breakdown of the robots.txt standard, a new proposal has emerged: llms.txt. The goal of this proposed standard is to create a dedicated channel for communication between websites and AI crawlers. It aims to provide a machine-readable, LLM-friendly version of a site's content that AI models can access efficiently without overwhelming the site's primary infrastructure and degrading the experience for human users. In theory, this would allow AI companies to acquire the data they need while minimizing the collateral damage of aggressive scraping.
However, this approach has been met with considerable skepticism, with reports noting that "not everyone is enthusiastic". The
llms.txt proposal is fundamentally an act of appeasement. It accepts the inevitability of data scraping and seeks only to manage the technical consequences. It does not, in its current form, address the core economic problem of uncompensated value extraction. Website owners would still be providing their content for free to train proprietary models, merely doing so in a more structured format. This strategy cedes the right to the data in exchange for technical stability, a trade-off many content creators are unwilling to make. Its success hinges entirely on voluntary adoption by AI companies and a belief that they will honor this new protocol any more than they honored the last.
The Infrastructure Strikes Back: Platform-Level Defenses
A contrasting and far more confrontational strategy is emerging from the major infrastructure providers that form the backbone of the web. Companies like Cloudflare, which sit between websites and their visitors, are in a unique position to analyze traffic patterns at a global scale and identify malicious bot activity. In a direct response to the AI crawler threat, these providers are now offering "default bot-blocking services" designed to deter AI companies from accessing their customers' data.
This represents a significant market shift towards mitigation-as-a-service. Instead of placing the burden of defense on individual website owners, these platforms leverage their vast network and machine learning capabilities to detect and block sophisticated crawlers in real time. This approach treats unwanted AI scraping not as a negotiation but as a security threat to be neutralized. It asserts the website owner's right to control their data and represents a philosophy of confrontation and denial rather than appeasement. The prevalence and increasing sophistication of these services indicate that the industry is moving towards an active, technological arms race.
The Open-Source Resistance
Alongside commercial solutions, a community-driven, open-source resistance has also begun to form. Tools like the "Anubis AI crawler blocker" have been developed to provide accessible, low-cost defense mechanisms for smaller site owners who may not be able to afford enterprise-grade protection from major CDNs. These tools typically work by maintaining and sharing community-sourced lists of known bad IP addresses, user-agent strings, and behavioral fingerprints associated with aggressive AI crawlers. They aim to democratize defense, allowing anyone to implement a basic level of protection. While these efforts are crucial for the broader ecosystem, their long-term efficacy remains a question in a fast-evolving arms race against multi-billion dollar technology companies that can rapidly change their tactics to evade such static defenses.
Strategic Assessment of Defensive Options
The choice of a defensive strategy involves a complex trade-off between cost, complexity, effectiveness, and underlying philosophy. The following table provides a strategic assessment of the available countermeasures, offering a framework for decision-makers to evaluate their options.
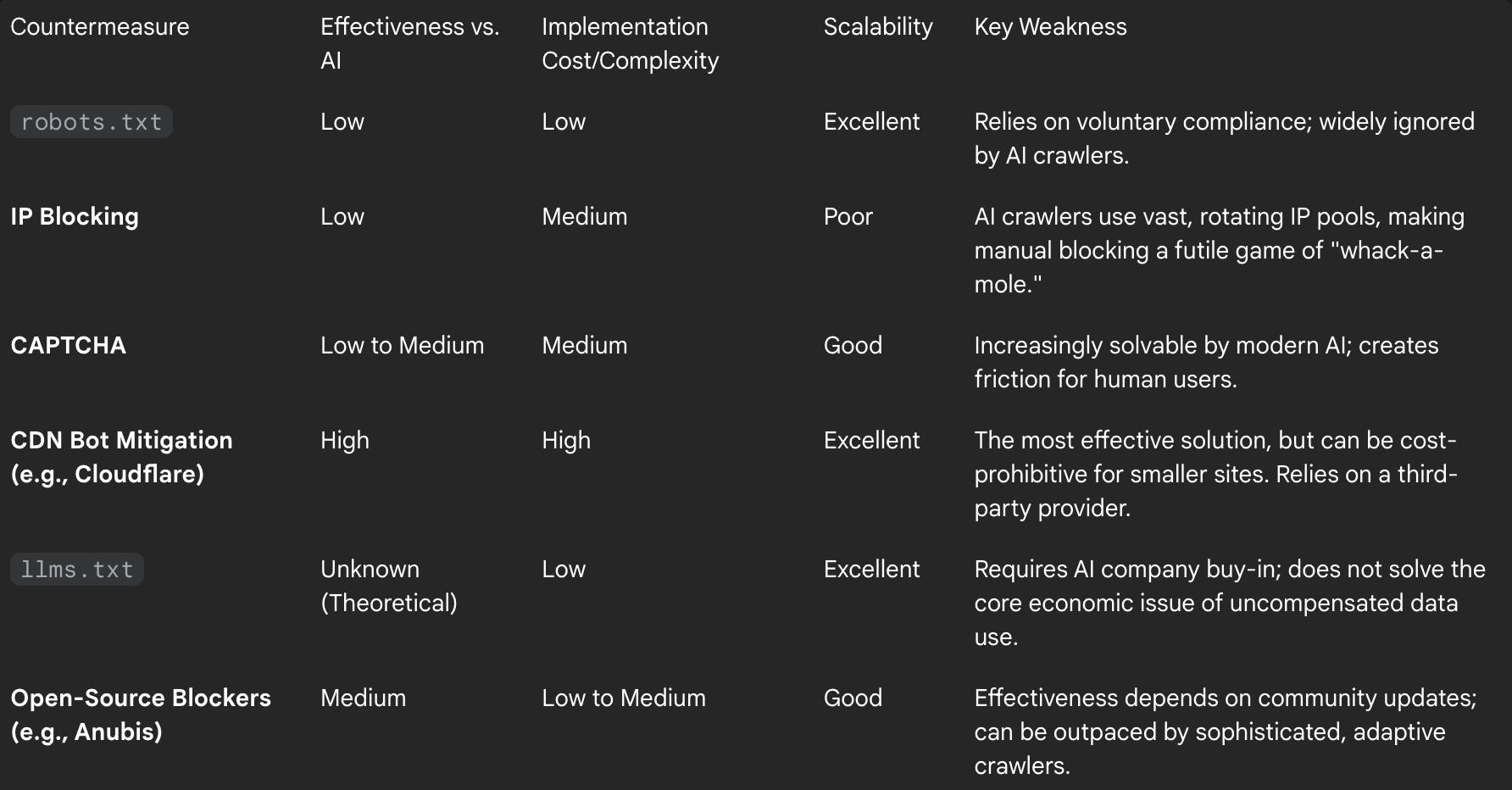
This evaluation reveals a clear strategic schism. One path, represented by llms.txt, advocates for managed cooperation. The other, represented by CDN bot mitigation, advocates for technological confrontation. The future of the web may well be determined by which of these two philosophies prevails in the market.
Strategic Recommendations for Key Stakeholders
For Website and Content Owners
Website and content owners must abandon passive defense and adopt a proactive, multi-layered "defense-in-depth" strategy. The era of relying on a single text file is over.
Technical Layer: The first priority should be the implementation of a sophisticated, real-time bot mitigation service, preferably at the CDN level. Services from providers like Cloudflare offer the most effective defense against adaptive AI crawlers. This should be supplemented with on-server tools, such as open-source blockers like Anubis, to act as a secondary layer of protection. Furthermore, websites should be hardened to minimize attack surfaces, for instance, by disabling unnecessary script execution for requests identified as likely bots.
Legal & Policy Layer: Terms of Service must be immediately updated to explicitly and unambiguously forbid data scraping, harvesting, or any form of automated content extraction for the purpose of training artificial intelligence models. While the legal enforceability of ToS is complex, it establishes a clear legal basis for future action and signals intent. Operators should also actively monitor and engage with emerging legal and regulatory frameworks surrounding data ownership and copyright in the age of AI.