

The Unreasonable Effectiveness of Prompt Engineering in Large Language Models
Prompt engineering has emerged as both a practical tool and a contentious topic in the field of artificial intelligence.

Prompt engineering has emerged as both a practical tool and a contentious topic in the field of artificial intelligence. With the rise of large language models (LLMs) like OpenAI’s GPT series and Anthropic’s Claude, the art of crafting prompts to elicit specific responses has become increasingly sophisticated. While the basic premise seems straightforward — tell the AI what you want — it has evolved into a complex discipline involving various techniques and methodologies.
This article explores the intricacies of prompt engineering, examining its different methods, their effectiveness, and whether they genuinely enhance AI performance or are overestimated. We’ll delve into the underlying mechanisms of LLMs, discuss recent developments, and consider whether prompt engineering is a practical tool or an overcomplicated approach overshadowing a deeper understanding of AI.
I. Understanding Prompt Engineering
A. Definition and Purpose
Prompt engineering is the process of designing and refining input prompts to guide AI language models toward producing desired outputs. It aims to maximize the utility of these models by providing precise instructions, enabling them to generate more accurate, relevant, and coherent responses. In essence, it’s about “speaking the AI’s language” to get the best possible results.
In the context of LLMs, prompts are not just casual queries but carefully crafted inputs that influence the model’s behavior. By manipulating the wording, structure, and context of prompts, users can direct the AI to perform a wide array of tasks — from answering questions and composing essays to solving complex problems and even generating code.
B. The Role of Tokens and Context
Tokens are the fundamental units of text that AI models process. They can be words, subwords, or characters, depending on the model’s tokenization scheme. Providing more tokens in a prompt can offer the model more context, potentially leading to better performance.
The underlying principle is that the more information the AI has, the better it can predict the next token in a sequence. This autoregressive process — predicting the next token based on previous ones — is central to how LLMs generate text. Therefore, crafting prompts that supply ample and relevant context is crucial for extracting the model’s full potential.
C. Sensitivity of LLMs to Prompts
LLMs are highly sensitive to the nuances of prompts. Small changes in wording, punctuation, or formatting can significantly impact the model’s response. For example, altering word order, adding or removing a comma, or changing capitalization can lead to different outputs.
This sensitivity underscores the importance of prompt design. Crafting effective prompts requires an understanding of how the model interprets input and how subtle variations can influence its predictions. It’s not just about what you ask but how you ask it.
II. Core Prompting Methods
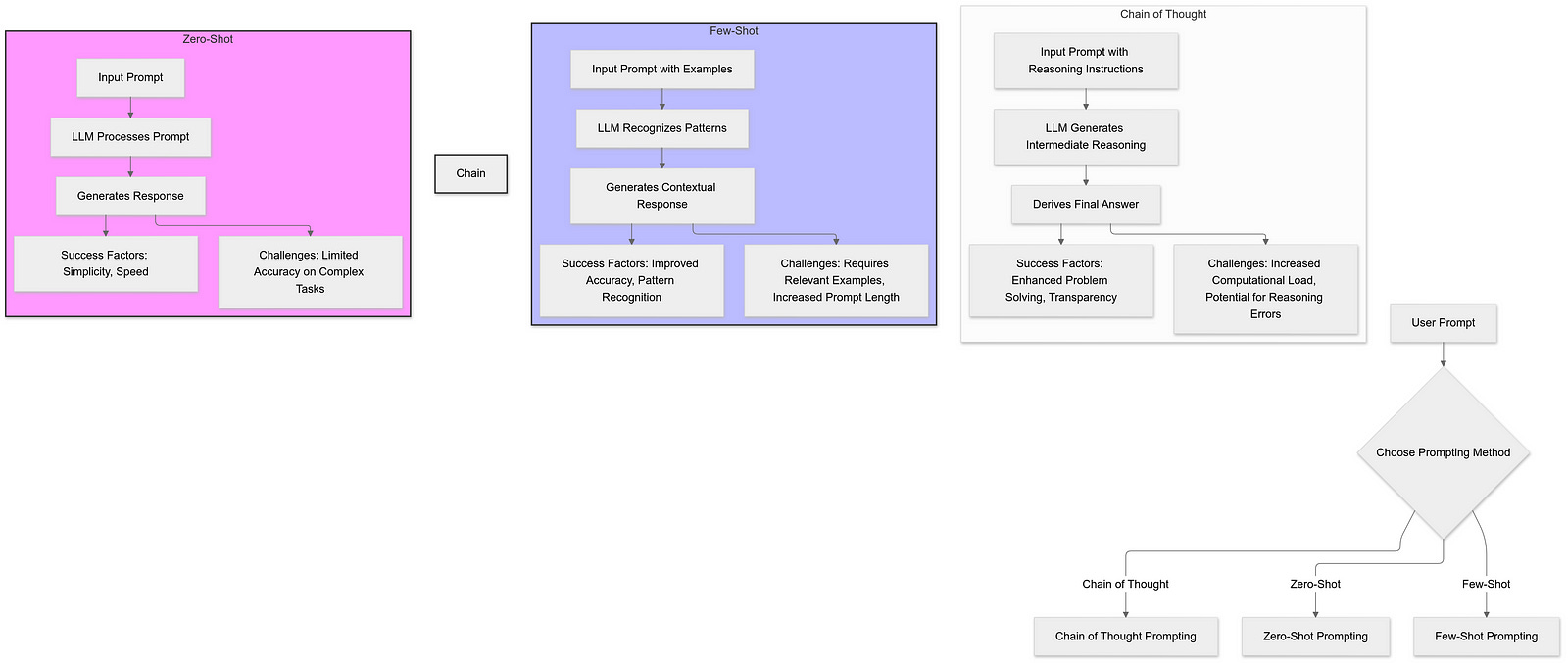
A. Zero-Shot Prompting
Zero-shot prompting involves asking the model to perform a task without providing any prior examples or additional guidance. The model relies solely on its pre-trained knowledge and the prompt to generate a response.
For instance:
Prompt: “Translate ‘Hello’ to Spanish.”
Response: “Hola.”
While zero-shot prompting demonstrates the model’s ability to generalize, it can be limited when the task is complex or outside the model’s training data. If the model hasn’t been exposed to certain information, it may struggle to provide accurate answers.
B. Few-Shot Prompting
Few-shot prompting provides the model with a few examples of the desired task before requesting the actual response. By including these examples in the prompt, the model can better understand the task and produce more accurate outputs.
For example:
Translate the following from English to French:
English: Good morning.
French: Bonjour.
English: Thank you.
French: Merci.
English: How are you?
French:The model is expected to continue the pattern and provide “Comment ça va?” as the translation.
Few-shot prompting helps the model recognize patterns and apply them to new instances, enhancing its performance on specific tasks.
C. Chain of Thought (CoT) Prompting
Chain of Thought prompting encourages the model to articulate intermediate reasoning steps when solving complex problems. Instead of directly providing an answer, the model explains the thought process leading to the solution.
For example:
Question: “If a train travels at 60 miles per hour for 2 hours, how far does it travel?”
Chain of Thought: “The train travels 60 miles in one hour. In two hours, it travels 60 miles/hour × 2 hours = 120 miles.”
Answer: “The train travels 120 miles.”
By breaking down the problem, the model can handle more complex tasks requiring multi-step reasoning, leading to more accurate and reliable answers.
D. Problem Decomposition and Advanced Techniques
Problem decomposition involves breaking down a complex problem into smaller, manageable parts. Techniques like “Plan and Solve” instruct the model to first outline a solution strategy before executing it.
For example:
Question: “Calculate the area of a triangle with a base of 10 units and a height of 5 units.”
Plan: “To find the area of a triangle, use the formula (base × height) / 2.”
Solution: “(10 units × 5 units) / 2 = 25 square units.”
Answer: “The area of the triangle is 25 square units.”
By explicitly instructing the model to plan, it can approach problems systematically, reducing errors and improving the quality of its responses.
III. Evaluating the Effectiveness of Prompt Engineering
A. Benefits and Limitations
Prompt engineering can significantly influence the performance of AI models. By providing clear instructions and relevant context, users can tap into the model’s existing capabilities. However, it’s essential to recognize that prompt engineering doesn’t create new knowledge within the model; it optimizes the extraction of knowledge the model has already learned during pre-training.
For example, if the model hasn’t been trained on a specific topic or lacks certain information, no amount of prompt engineering will enable it to produce accurate responses on that topic.
B. The Placebo Effect and Overcomplication
Some argue that the perceived effectiveness of complex prompting methods might be coincidental or exaggerated. Overcomplicating prompts may not necessarily lead to better results and can sometimes confuse the model. It’s crucial to find a balance between providing sufficient context and overloading the prompt with unnecessary information.
Studies have shown that sometimes, simply adding more words — even if they are irrelevant — can improve performance due to the model’s autoregressive nature. This raises questions about whether the complexity of some prompt engineering techniques is genuinely beneficial or if simpler approaches might suffice.
C. Research Findings
Research has produced mixed results regarding the effectiveness of different prompting techniques. The “Think Before You Speak” paper suggests that delaying the final answer, even with meaningless tokens, can improve performance. This implies that the act of generating more tokens might inherently aid the model’s reasoning process.
Another study, “Futuren Lens,” explores how the information used to generate one token contains predictive data for subsequent tokens. This suggests that models might inherently know more than they express and that their internal processes could be leveraged to improve performance without complex prompt engineering.
IV. Training AI Models: Pre-Training and Post-Training
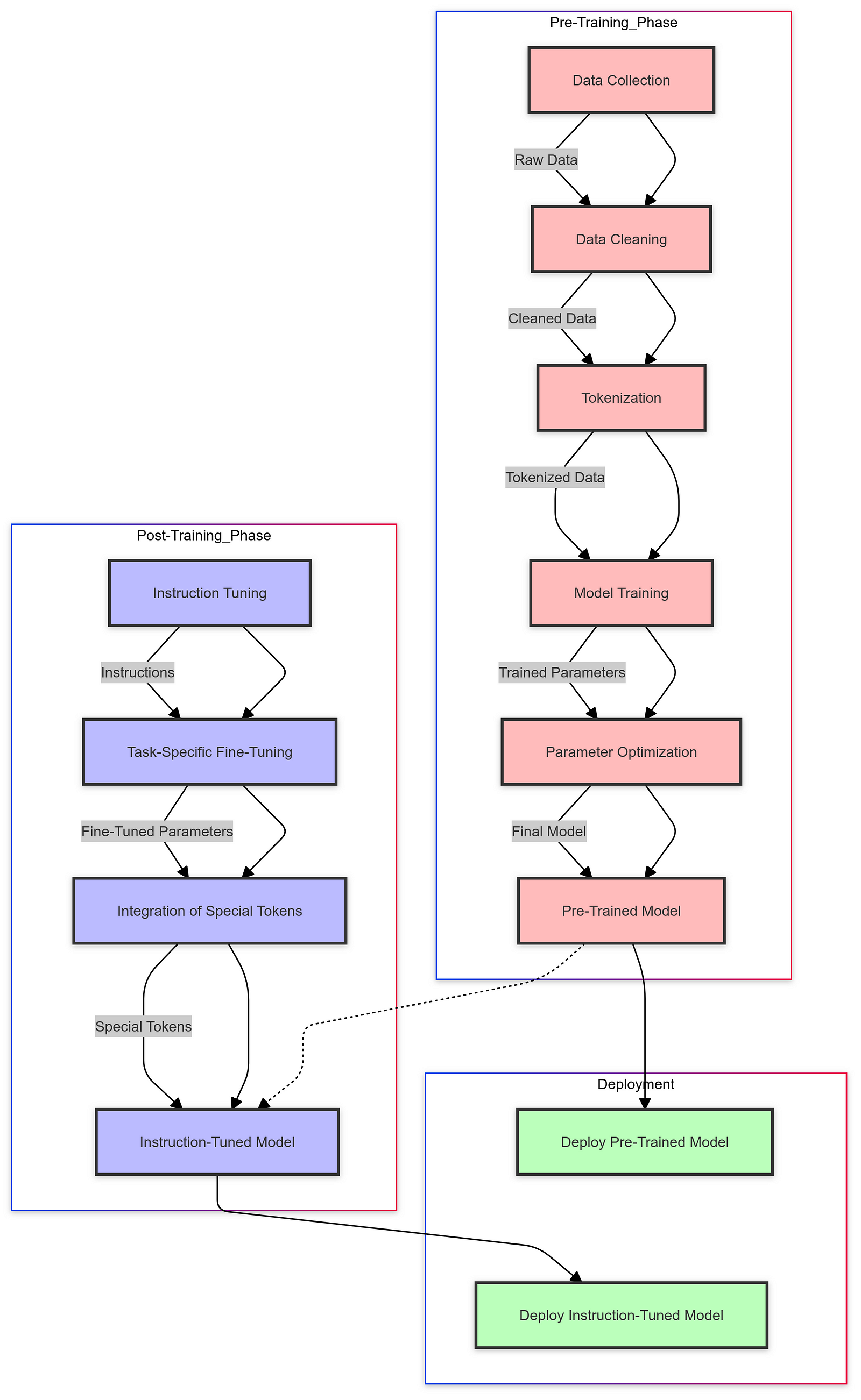
A. The Pre-Training Phase
In the pre-training phase, AI models learn from vast amounts of data, such as text from books, articles, and the internet. They develop an understanding of language patterns, facts, and general knowledge. This phase equips the model with the foundational knowledge needed to perform various tasks.
For example, by reading millions of webpages, the model learns grammar, vocabulary, and information about the world, which it can later use to generate coherent and contextually appropriate responses.
B. The Post-Training Phase (Instruction Tuning)
Post-training, or instruction tuning, involves fine-tuning the model to perform specific tasks and follow instructions. This phase teaches the model how to interact conversationally, adhere to desired formats, and execute particular functions.
For instance, a model might be fine-tuned to answer questions in a Q&A format, generate programming code, or perform calculations using specific APIs. This phase often involves training on curated datasets that include example interactions and desired behaviors.
C. Use of Special Tokens
Special tokens are markers used during training to signal different stages or actions in the model’s processing. They help the model distinguish between user input, its responses, and internal reasoning steps.
Examples include:
<BEGIN_THOUGHT>and<END_THOUGHT>: Indicate the start and end of the model's internal reasoning.<ASSISTANT>and<USER>: Distinguish between the AI's responses and user inputs.<CALCULATE>: Signal that the model should perform a calculation or call an API.
These tokens enable the model to manage complex interactions and functionalities, improving its ability to perform tasks accurately.
V. Recent Developments in Large Language Models
A. OpenAI’s ‘01’ Model
OpenAI introduced a new series of models, referred to as ‘01,’ designed to excel at reasoning and logical tasks. A key innovation is the use of Chain of Thought mechanisms that allow the model to “think” through problems before arriving at an answer.
This approach enhances the model’s performance on complex tasks requiring multi-step reasoning, such as mathematical problems, logical puzzles, and analytical questions. By integrating reasoning steps into the generation process, the model can provide more accurate and explainable answers.
B. Anthropic’s Claude 3.5 Solonet
Anthropic’s Claude 3.5 Solonet incorporates Chain of Thought natively using special tokens for internal reasoning. The model uses an “inner thought” process, where it conducts reasoning internally before generating the final response.
This method aims to improve consistency and prevent the model from deviating from the topic or making errors in its reasoning steps. By training the model to manage its internal thought processes effectively, it can deliver more reliable and coherent outputs.
C. Hidden Chain of Thought Processes
Some models, like OpenAI’s latest offerings, hide their Chain of Thought processes from the user. While the model uses internal reasoning to arrive at answers, these steps are not displayed in the output. This approach may be intended to:
Prevent reverse engineering of proprietary techniques.
Streamline user interactions by providing concise answers.
Maintain focus on the final result rather than the reasoning process.
Hiding the internal steps doesn’t diminish their impact on the model’s performance; it simply changes how the information is presented to the user.
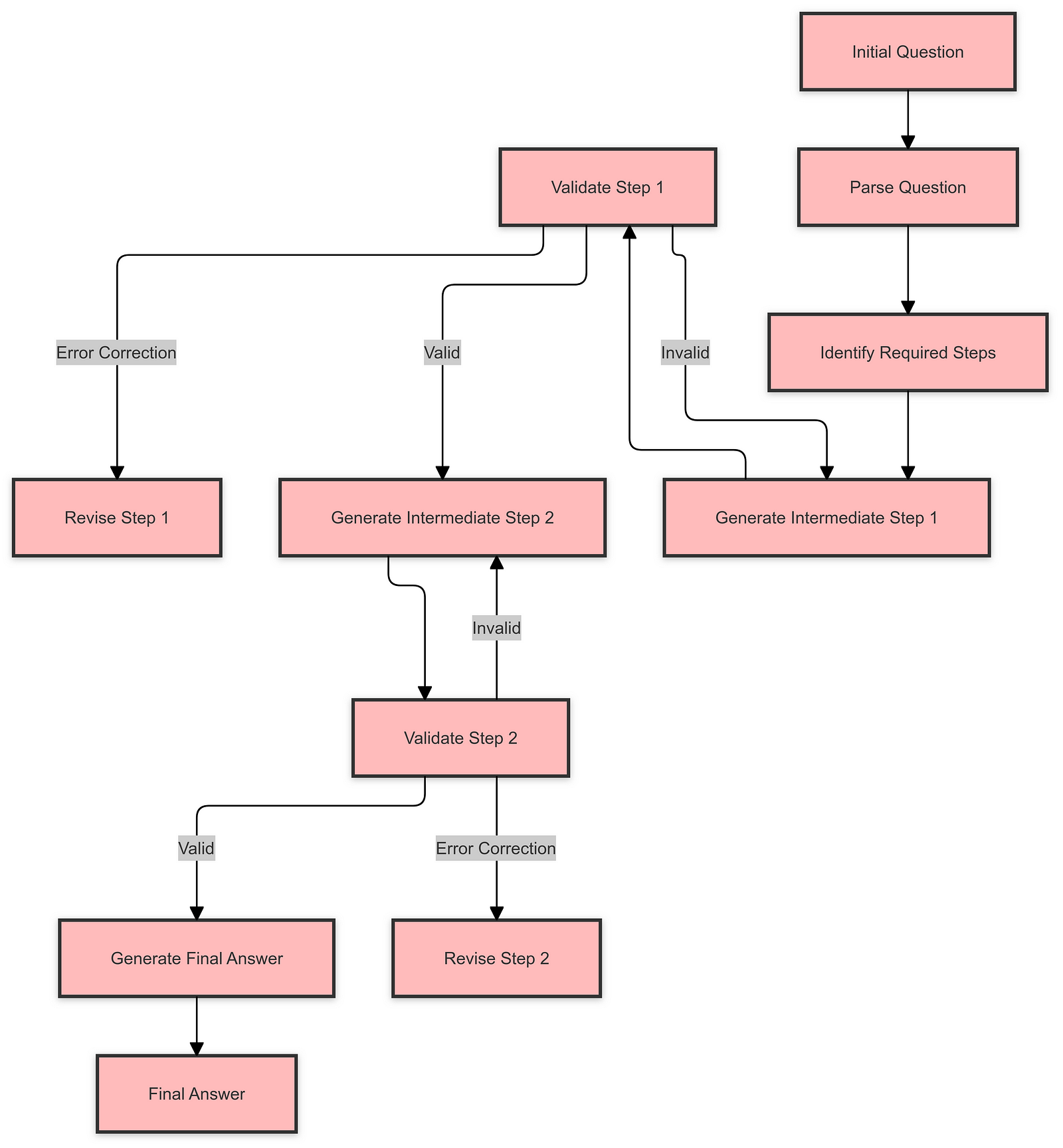
VI. In-Depth Analysis of Chain of Thought
A. Mechanisms Behind Chain of Thought
Chain of Thought prompting leverages the model’s ability to generate intermediate reasoning steps. By simulating a thought process, the model can handle tasks that require logical reasoning, mathematical calculations, or problem-solving.
For example, when solving a math problem, the model breaks down the calculations step by step, similar to how a human might work through the problem on paper. This process helps the model maintain accuracy and provides transparency in how it arrived at the answer.
B. Challenges with Chain of Thought
Despite its benefits, Chain of Thought can introduce challenges:
Fragility: The process is sensitive; a single incorrect step in the reasoning can lead to a wrong answer.
Inconsistency: Without careful prompt design or extensive training, the model may not consistently produce reasoning steps.
Complexity: Implementing effective Chain of Thought requires significant effort in training and prompt engineering.
These challenges highlight the need for careful design and understanding of the model’s capabilities when employing Chain of Thought techniques.
C. Comparison with Other Methods
Alternative methods like self-reflection and self-verification involve the model reviewing and checking its responses. While these can improve accuracy, they may not always be more effective than Chain of Thought prompting.
Self-Reflection: The model generates an answer, then re-evaluates it for correctness.
Self-Verification: The model compares its answer against known information or rephrases the problem to confirm consistency.
These methods can be time-consuming and may not significantly outperform simpler approaches, depending on the task and the model’s training.
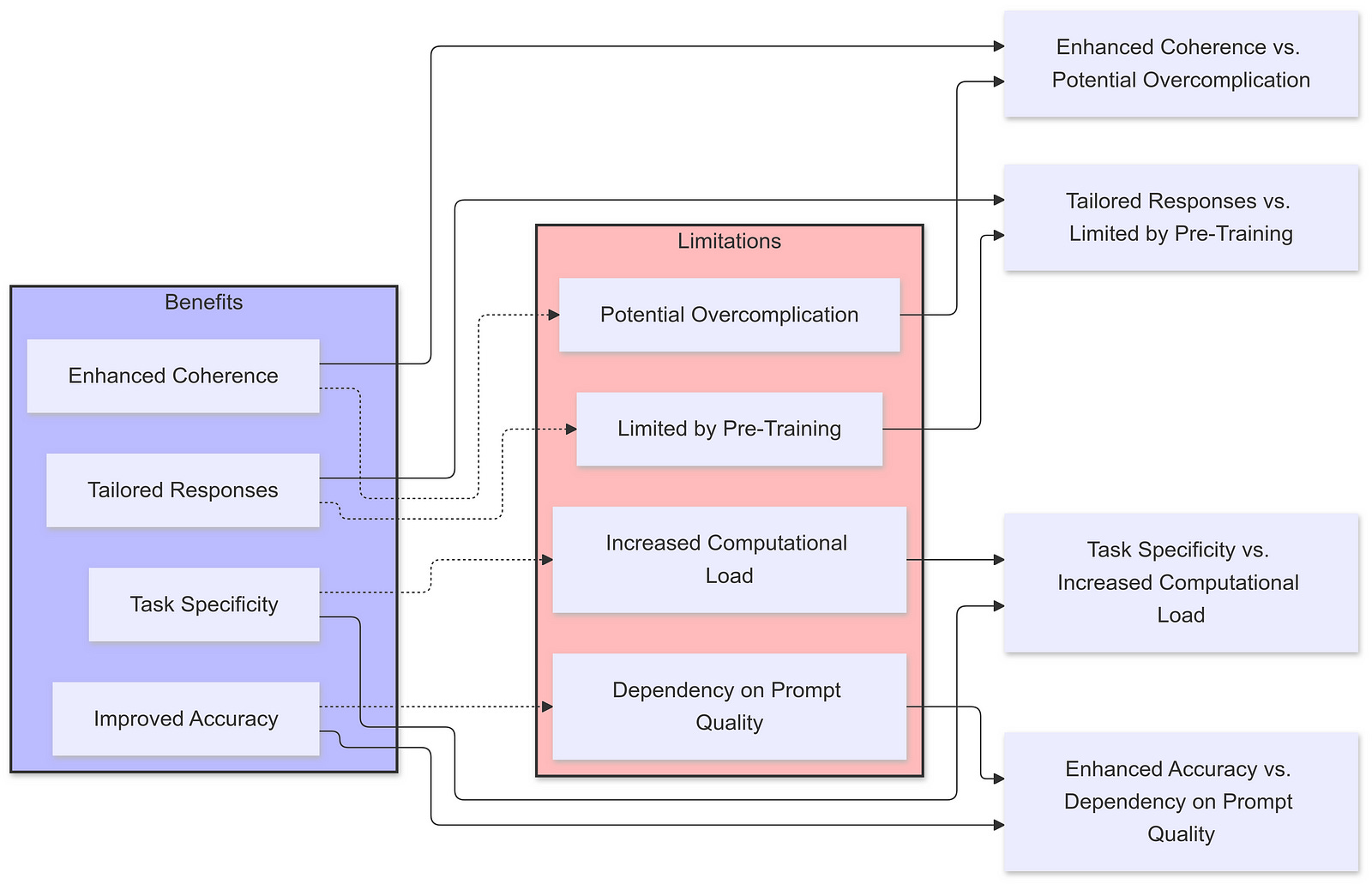
VII. The Debate: Is Prompt Engineering Overrated?
A. Arguments Suggesting Overestimation
