

Unlocking Business Success by Unifying Your Data for Smarter Decisions and Seamless Operations
Beyond Data Silos: Achieving Enterprise-Wide Data Consistency in the Modern Age

In the spring of 2010, a prominent financial institution faced a catastrophic loss amounting to hundreds of millions of dollars due to inconsistent trading data across its systems. Trades were duplicated, market positions were misrepresented, and risk assessments were skewed—all because disparate systems failed to maintain consistent data. This disaster not only led to significant financial loss but also eroded stakeholder trust and invited regulatory scrutiny. Such incidents underscore the escalating complexity of enterprise systems and the critical importance of robust data management strategies.
As organizations expand and adopt new technologies, the challenge of maintaining consistent data across distributed systems intensifies. A report by IBM indicates that poor data quality costs the U.S. economy around $3.1 trillion annually. Data inconsistencies can lead to erroneous business decisions, compliance violations, and operational inefficiencies. The tension between allowing systems to operate autonomously and ensuring enterprise-wide data consistency has never been more pronounced. While "eventual consistency" models offer flexibility and performance benefits, they may not suffice for operations requiring immediate and accurate data synchronization. Conversely, "strong consistency" ensures real-time data uniformity but can impede system performance and scalability.
The Modern Enterprise Data Landscape
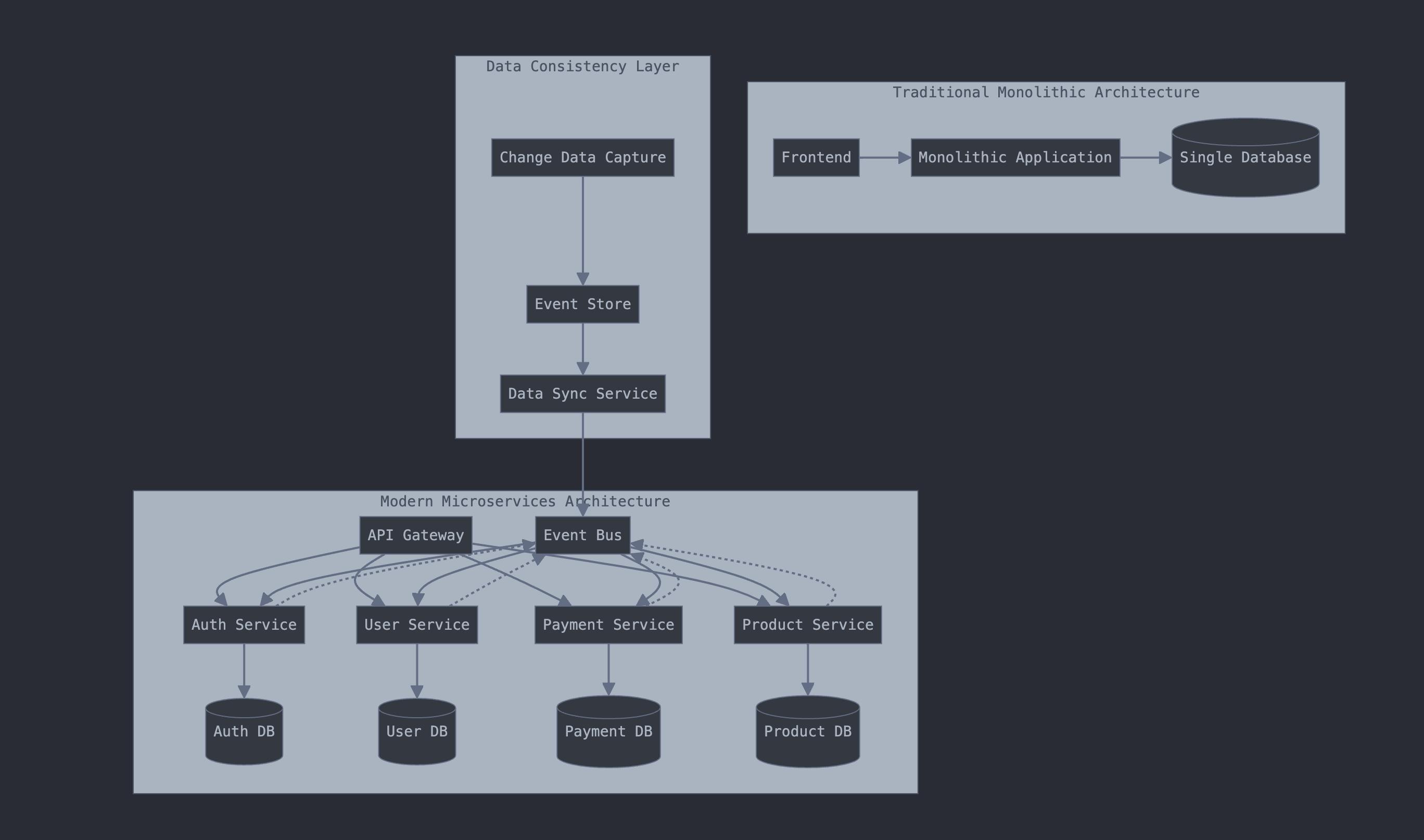
The architecture of enterprise systems has evolved dramatically over the past few decades. Organizations have transitioned from monolithic applications to microservices architectures, influenced by the need for scalability, flexibility, and rapid deployment cycles. This shift has been further propelled by the widespread adoption of cloud computing, enabling hybrid deployments that combine on-premises systems with cloud-based services. However, integrating Software as a Service (SaaS) solutions introduces new challenges, as data must be synchronized across platforms with differing protocols and standards.
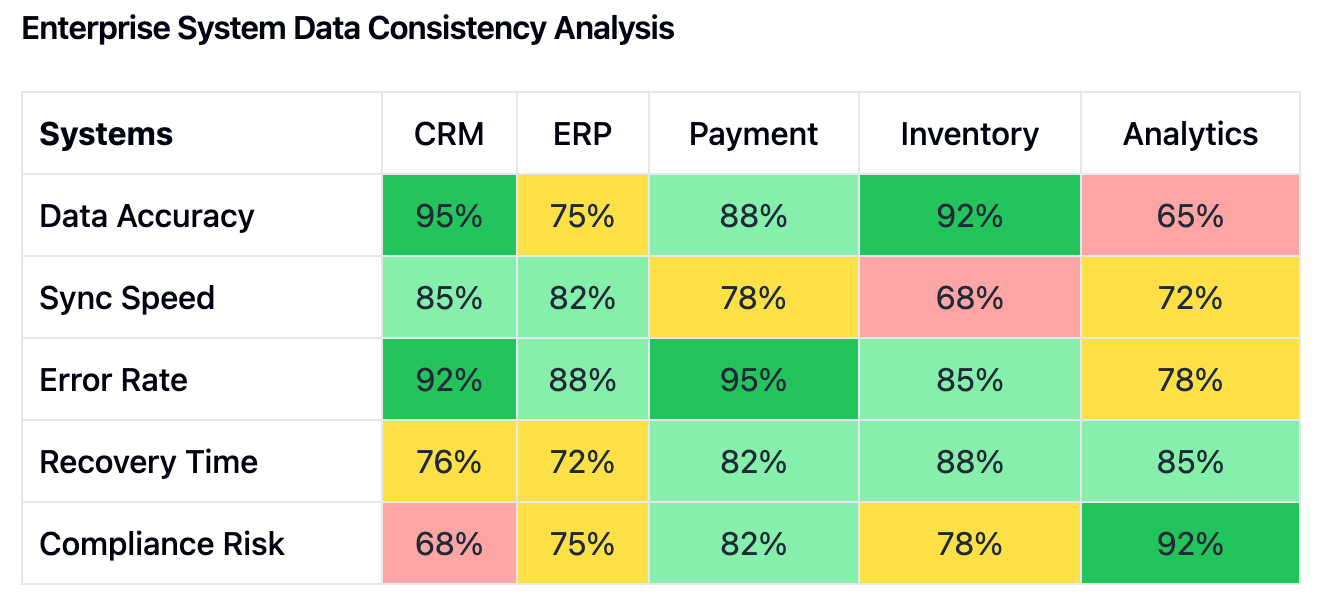
Data sprawl is a defining characteristic of the modern enterprise. Operational databases, analytical data warehouses, and various cache layers create a complex web of data repositories. The proliferation of these repositories often leads to data duplication, as different systems require local copies of data to function efficiently. For instance, a customer record might exist in separate CRM, ERP, and marketing automation systems, each updated independently. Real-time processing requirements exacerbate this issue, as businesses demand instantaneous insights and responsiveness, leading to more frequent data replication and synchronization efforts.
The business implications of this landscape are significant. Operational costs rise due to increased infrastructure needs, as more storage and compute resources are required to manage duplicated and fragmented data. Development becomes more complex, with engineers needing to account for data synchronization and consistency across multiple systems. Maintenance burdens increase, as does the necessity for robust incident response mechanisms to address data-related issues swiftly.
From a risk perspective, data inconsistencies can lead to regulatory compliance violations. For example, under the General Data Protection Regulation (GDPR), organizations must ensure that personal data is accurate and up-to-date. Failure to maintain consistent data can result in substantial fines. Customer experience also suffers when, say, a client updates their contact information, but different parts of the organization continue to use outdated details. This can lead to lost revenue opportunities and damage to the company's reputation.
Common Data Consistency Challenges

Technical challenges in maintaining data consistency are manifold. Distributed transaction management becomes increasingly complex in a microservices architecture. The CAP theorem posits that in the presence of a network partition, a distributed system must choose between consistency and availability. Network partitions, though often transient, can cause systems to desynchronize, leading to inconsistent data states. Clock synchronization issues add another layer of complexity, as distributed systems rely on timestamps to order events, and discrepancies can lead to race conditions where the outcome depends on the sequence of event execution, potentially causing data anomalies.
Data synchronization patterns such as event-driven architectures introduce their own challenges. Ensuring message delivery guarantees—whether at-most-once, at-least-once, or exactly-once semantics—is critical to maintaining consistency. Ordering guarantees are equally important; messages must be processed in the correct sequence to reflect the accurate state of the system. Idempotency becomes a key requirement, as systems must handle duplicate messages without causing unintended side effects.
Organizational challenges are equally significant. According to Conway's Law, organizations design systems that mirror their communication structures. Silos within teams can lead to knowledge gaps and inconsistent implementation of data management practices. Communication overhead increases as teams grow and become more specialized, making it harder to coordinate changes that affect multiple systems. Responsibility boundaries can become blurred, leading to confusion over who owns data quality and consistency.
Process complexities arise in change management and release coordination. Implementing changes that affect data consistency requires meticulous planning and collaboration across teams. Incident response coordination becomes more challenging when multiple systems and teams are involved. Documentation, often overlooked, is essential to ensure that everyone has a clear understanding of data flows and dependencies.
Regulatory Landscape
The regulatory environment adds another layer of urgency to addressing data consistency. In the financial sector, the Digital Operational Resilience Act (DORA) mandates that financial entities ensure the integrity and availability of critical data. Basel III requirements emphasize the importance of accurate risk data aggregation and reporting. The Sarbanes-Oxley Act (SOX) imposes strict financial reporting obligations, necessitating consistent and accurate data across all financial systems. GDPR not only focuses on data privacy but also on the accuracy and consistency of personal data.
Industry-specific requirements further complicate the landscape. In healthcare, the Health Insurance Portability and Accountability Act (HIPAA) mandates strict controls over patient data, requiring consistent and accurate records to ensure patient safety and privacy. The Payment Card Industry Data Security Standard (PCI-DSS) in retail requires consistent handling of payment information to prevent fraud. Manufacturing industries often have traceability requirements, needing consistent data to track products through the supply chain for quality control and recall management.
Future trends indicate that regulatory pressures will only increase. Emerging regulations are focusing on data ethics, artificial intelligence, and cross-border data flows. Industry self-regulation efforts are also gaining momentum, with consortiums developing best practices and standards for data management. International coordination initiatives aim to harmonize regulations across jurisdictions, adding complexity to compliance efforts but also offering opportunities for
standardization.
Solution Approaches
Technical solutions to data consistency challenges are evolving. Modern data platforms leverage event sourcing patterns, where changes to data are logged as a sequence of events. This approach allows systems to reconstruct the current state by replaying events, ensuring consistency across different components. Command Query Responsibility Segregation (CQRS) separates read and write operations, optimizing each for performance and scalability while maintaining data integrity. Distributed consensus protocols like Raft and Paxos enable systems to agree on the state of data across nodes, essential for strong consistency models. State machine replication replicates services across multiple machines, ensuring that they all process the same sequence of inputs and thus remain consistent.
Infrastructure considerations play a crucial role. High availability patterns such as active-active clustering prevent single points of failure and ensure that data remains accessible and consistent even during outages. Disaster recovery approaches, including automated failover and data replication to secondary sites, are essential for resilience. Performance optimization techniques, such as in-memory data grids and optimized query processing, help maintain system responsiveness while managing data consistency. Monitoring and observability tools provide real-time insights into system performance and data flows, enabling proactive management of potential issues.
Architectural patterns offer frameworks for implementing consistency. The Saga pattern coordinates transactions across microservices by breaking them into a sequence of local transactions with compensating actions for rollbacks. The Outbox pattern ensures that messages are sent only after a local transaction commits, preventing inconsistencies between data stores and message queues. Change Data Capture (CDC) approaches monitor data changes in databases and propagate them to other systems, keeping data synchronized. Version vectors and vector clocks help in resolving conflicts in distributed systems by tracking the causal relationships between different versions of data.
Integration patterns are essential for connecting disparate systems. API gateways provide a unified interface for external clients while abstracting the complexities of underlying services. Service meshes manage service-to-service communication within a microservices architecture, offering features like load balancing, encryption, and authentication. Event broker architectures, using technologies like Apache Kafka or RabbitMQ, facilitate asynchronous communication and decouple systems for scalability. Database federation techniques allow queries to span multiple databases, presenting a unified view of data without the need for duplication.
Implementation Strategy
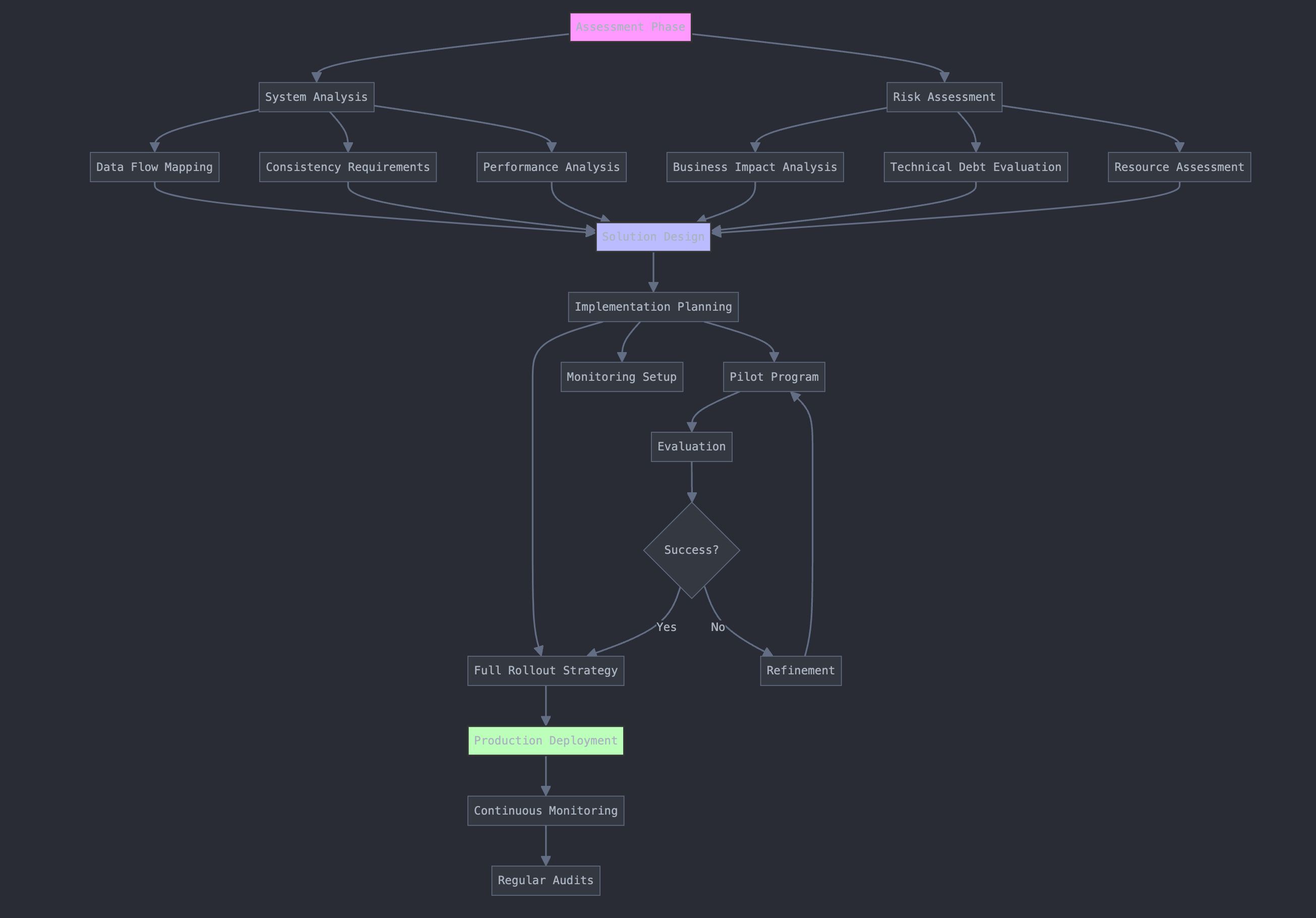
A successful implementation strategy begins with a thorough assessment phase. System analysis involves mapping data flows across the organization to identify where inconsistencies may arise. Classifying consistency requirements helps prioritize efforts, as not all data may require the same level of consistency. For instance, financial transactions may need strong consistency, while product catalog updates might tolerate eventual consistency. Analyzing performance requirements ensures that solutions do not adversely impact system responsiveness. A cost-benefit analysis helps justify investments by weighing the costs of implementation against the potential risks and savings.
Risk assessment is crucial. Business impact analysis evaluates the potential consequences of data inconsistencies, guiding decision-making on where to focus resources. Technical debt evaluation identifies legacy systems or practices that may hinder consistency efforts. Assessing resource availability, both in terms of personnel and technology, ensures that the organization can support the initiative. Timeline constraints must be considered to align the project with business objectives and regulatory deadlines.
The implementation approach often benefits from a phased rollout strategy. Designing a pilot program allows the organization to test solutions on a smaller scale, gather feedback, and make adjustments before full deployment. Defining success metrics, such as reduced incidents of data inconsistency or improved system performance, provides measurable goals. Establishing rollback procedures ensures that the organization can revert changes if unforeseen issues arise. A comprehensive communication plan keeps stakeholders informed and engaged throughout the process.
Organizational changes may be necessary to support the technical initiatives. Adjusting team structures to promote cross-functional collaboration can break down silos and improve communication. Training programs equip staff with the necessary skills to implement and maintain new systems and practices. Modifying processes, such as adopting agile methodologies or DevOps practices, can enhance flexibility and responsiveness. Updating documentation ensures that knowledge is retained and accessible, facilitating onboarding and ongoing operations.
